 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain tumor segmentation using synthetic MR images -- A comparison of GANs and diffusion models
Jun 05, 2023Large annotated datasets are required for training deep learning models, but in medical imaging data sharing is often complicated due to ethics, anonymization and data protection legislation (e.g. the general data protection regulation (GDPR)). Generative AI models, such as generative adversarial networks (GANs) and diffusion models, can today produce very realistic synthetic images, and can potentially facilitate data sharing as GDPR should not apply for medical images which do not belong to a specific person. However, in order to share synthetic images it must first be demonstrated that they can be used for training different networks with acceptable performance. Here, we therefore comprehensively evaluate four GANs (progressive GAN, StyleGAN 1-3) and a diffusion model for the task of brain tumor segmentation. Our results show that segmentation networks trained on synthetic images reach Dice scores that are 80\% - 90\% of Dice scores when training with real images, but that memorization of the training images can be a problem for diffusion models if the original dataset is too small. Furthermore, we demonstrate that common metrics for evaluating synthetic images, Fr\'echet inception distance (FID) and inception score (IS), do not correlate well with the obtained performance when using the synthetic images for training segmentation networks.
Does an ensemble of GANs lead to better performance when training segmentation networks with synthetic images?
Nov 08, 2022Large annotated datasets are required to train segmentation networks. In medical imaging, it is often difficult, time consuming and expensive to create such datasets, and it may also be difficult to share these datasets with other researchers. Different AI models can today generate very realistic synthetic images, which can potentially be openly shared as they do not belong to specific persons. However, recent work has shown that using synthetic images for training deep networks often leads to worse performance compared to using real images. Here we demonstrate that using synthetic images and annotations from an ensemble of 10 GANs, instead of from a single GAN, increases the Dice score on real test images with 4.7 % to 14.0 % on specific classes.
Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
Apr 07, 2021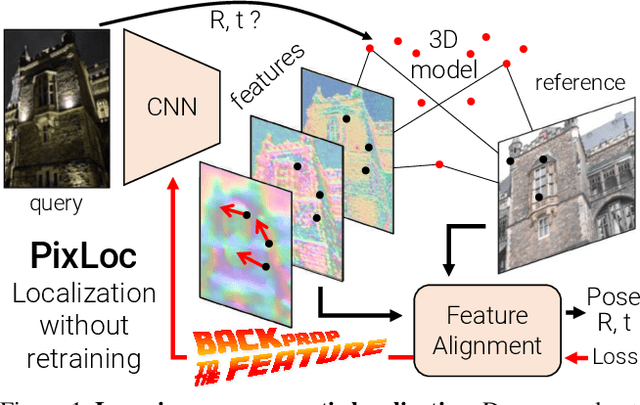
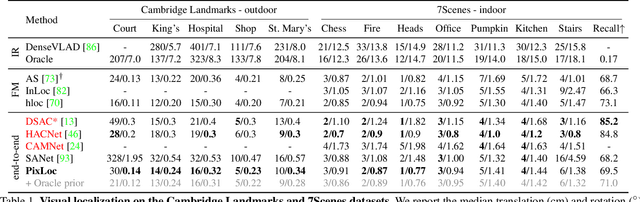
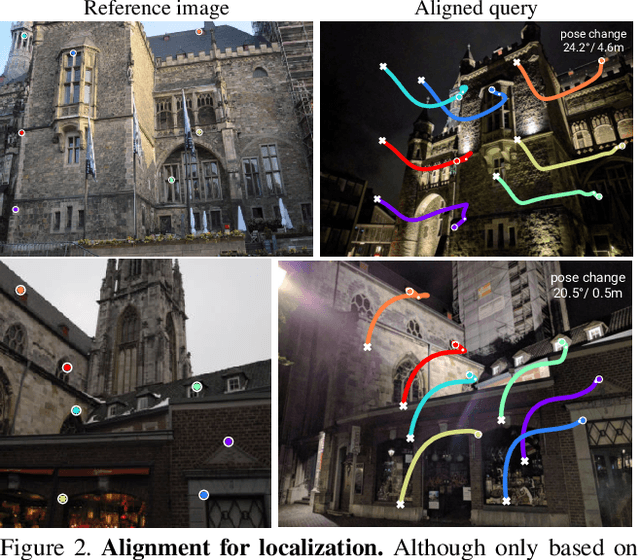
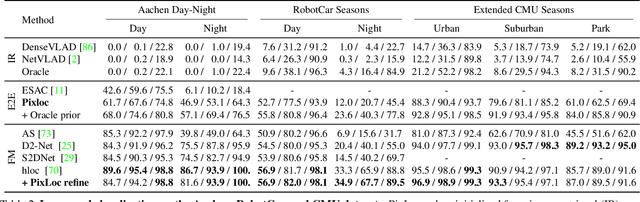
Camera pose estimation in known scenes is a 3D geometry task recently tackled by multiple learning algorithms. Many regress precise geometric quantities, like poses or 3D points, from an input image. This either fails to generalize to new viewpoints or ties the model parameters to a specific scene. In this paper, we go Back to the Feature: we argue that deep networks should focus on learning robust and invariant visual features, while the geometric estimation should be left to principled algorithms. We introduce PixLoc, a scene-agnostic neural network that estimates an accurate 6-DoF pose from an image and a 3D model. Our approach is based on the direct alignment of multiscale deep features, casting camera localization as metric learning. PixLoc learns strong data priors by end-to-end training from pixels to pose and exhibits exceptional generalization to new scenes by separating model parameters and scene geometry. The system can localize in large environments given coarse pose priors but also improve the accuracy of sparse feature matching by jointly refining keypoints and poses with little overhead. The code will be publicly available at https://github.com/cvg/pixloc.
Fine-Grained Segmentation Networks: Self-Supervised Segmentation for Improved Long-Term Visual Localization
Aug 18, 2019
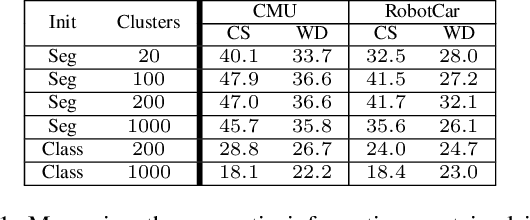
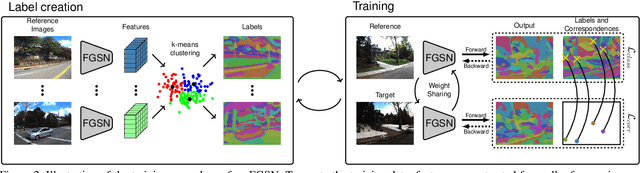

Long-term visual localization is the problem of estimating the camera pose of a given query image in a scene whose appearance changes over time. It is an important problem in practice, for example, encountered in autonomous driving. In order to gain robustness to such changes, long-term localization approaches often use segmantic segmentations as an invariant scene representation, as the semantic meaning of each scene part should not be affected by seasonal and other changes. However, these representations are typically not very discriminative due to the limited number of available classes. In this paper, we propose a new neural network, the Fine-Grained Segmentation Network (FGSN), that can be used to provide image segmentations with a larger number of labels and can be trained in a self-supervised fashion. In addition, we show how FGSNs can be trained to output consistent labels across seasonal changes. We demonstrate through extensive experiments that integrating the fine-grained segmentations produced by our FGSNs into existing localization algorithms leads to substantial improvements in localization performance.
A Cross-Season Correspondence Dataset for Robust Semantic Segmentation
Mar 16, 2019
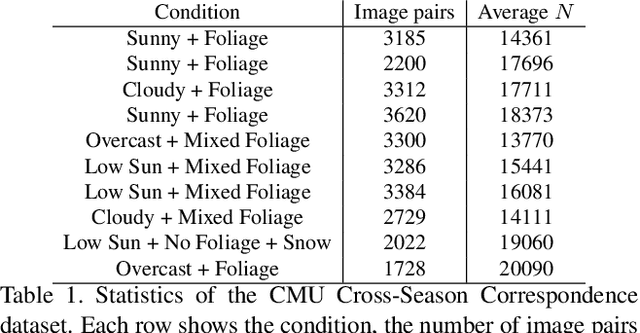

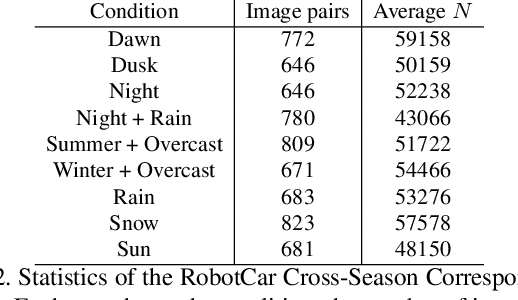
In this paper, we present a method to utilize 2D-2D point matches between images taken during different image conditions to train a convolutional neural network for semantic segmentation. Enforcing label consistency across the matches makes the final segmentation algorithm robust to seasonal changes. We describe how these 2D-2D matches can be generated with little human interaction by geometrically matching points from 3D models built from images. Two cross-season correspondence datasets are created providing 2D-2D matches across seasonal changes as well as from day to night. The datasets are made publicly available to facilitate further research. We show that adding the correspondences as extra supervision during training improves the segmentation performance of the convolutional neural network, making it more robust to seasonal changes and weather conditions.
A Projected Gradient Descent Method for CRF Inference allowing End-To-End Training of Arbitrary Pairwise Potentials
Jan 02, 2018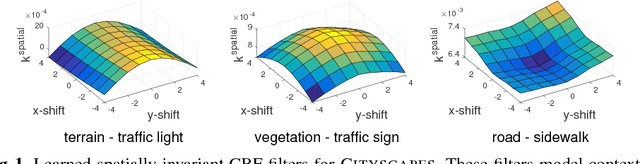
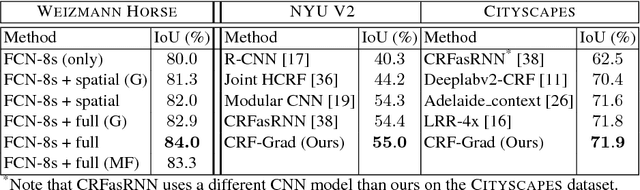
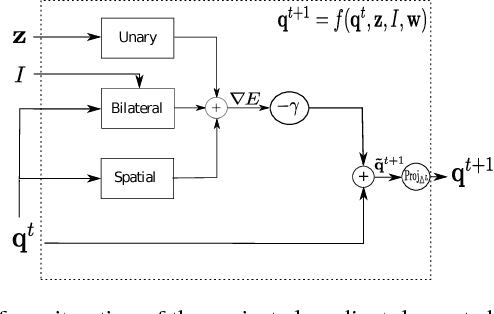

Are we using the right potential functions in the Conditional Random Field models that are popular in the Vision community? Semantic segmentation and other pixel-level labelling tasks have made significant progress recently due to the deep learning paradigm. However, most state-of-the-art structured prediction methods also include a random field model with a hand-crafted Gaussian potential to model spatial priors, label consistencies and feature-based image conditioning. In this paper, we challenge this view by developing a new inference and learning framework which can learn pairwise CRF potentials restricted only by their dependence on the image pixel values and the size of the support. Both standard spatial and high-dimensional bilateral kernels are considered. Our framework is based on the observation that CRF inference can be achieved via projected gradient descent and consequently, can easily be integrated in deep neural networks to allow for end-to-end training. It is empirically demonstrated that such learned potentials can improve segmentation accuracy and that certain label class interactions are indeed better modelled by a non-Gaussian potential. In addition, we compare our inference method to the commonly used mean-field algorithm. Our framework is evaluated on several public benchmarks for semantic segmentation with improved performance compared to previous state-of-the-art CNN+CRF models.