 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated learning for unpaired multimodal data through a homogeneous transformer model
Jan 25, 2026Training of multimodal foundation models is currently restricted to centralized data centers containing massive, aligned datasets (e.g., image-text pairs). However, in realistic federated environments, data is often unpaired and fragmented across disjoint nodes; one node may hold sensor data, while another holds textual logs. These datasets are strictly private and share no common samples. Current federated learning (FL) methods fail in this regime, as they assume local clients possess aligned pairs or require sharing raw feature embeddings, which violates data sovereignty. We propose a novel framework to train a global multimodal transformer across decentralized nodes with disjoint modalities. We introduce a small public anchor set to align disjoint private manifolds. Using Gram matrices calculated from these public anchors, we enforce semantic alignment across modalities through centered kernel alignment without ever transmitting private samples, offering a mathematically superior privacy guarantee compared to prototype sharing. Further, we introduce a subspace-stabilized fine-tuning method to handle FL with huge transformer models. We strictly decouple domain-specific magnitude shifts from semantic direction, ensuring that nodes with varying sensor characteristics align geometrically to the global consensus. Lastly, we propose precision weighted averaging, where efficiently obtained uncertainty estimates are used to downweight uncertain nodes. This paper establishes the mathematical backbone for federated unpaired foundation models, enabling a global model to learn a unified representation of the world from fragmented, disjoint, and private data silos without requiring centralized storage or paired samples.
Brain tumor segmentation using synthetic MR images -- A comparison of GANs and diffusion models
Jun 05, 2023Large annotated datasets are required for training deep learning models, but in medical imaging data sharing is often complicated due to ethics, anonymization and data protection legislation (e.g. the general data protection regulation (GDPR)). Generative AI models, such as generative adversarial networks (GANs) and diffusion models, can today produce very realistic synthetic images, and can potentially facilitate data sharing as GDPR should not apply for medical images which do not belong to a specific person. However, in order to share synthetic images it must first be demonstrated that they can be used for training different networks with acceptable performance. Here, we therefore comprehensively evaluate four GANs (progressive GAN, StyleGAN 1-3) and a diffusion model for the task of brain tumor segmentation. Our results show that segmentation networks trained on synthetic images reach Dice scores that are 80\% - 90\% of Dice scores when training with real images, but that memorization of the training images can be a problem for diffusion models if the original dataset is too small. Furthermore, we demonstrate that common metrics for evaluating synthetic images, Fr\'echet inception distance (FID) and inception score (IS), do not correlate well with the obtained performance when using the synthetic images for training segmentation networks.
Beware of diffusion models for synthesizing medical images -- A comparison with GANs in terms of memorizing brain tumor images
May 12, 2023Diffusion models were initially developed for text-to-image generation and are now being utilized to generate high quality synthetic images. Preceded by GANs, diffusion models have shown impressive results using various evaluation metrics. However, commonly used metrics such as FID and IS are not suitable for determining whether diffusion models are simply reproducing the training images. Here we train StyleGAN and diffusion models, using BRATS20 and BRATS21 datasets, to synthesize brain tumor images, and measure the correlation between the synthetic images and all training images. Our results show that diffusion models are much more likely to memorize the training images, especially for small datasets. Researchers should be careful when using diffusion models for medical imaging, if the final goal is to share the synthetic images.
Efficient brain age prediction from 3D MRI volumes using 2D projections
Nov 10, 2022Using 3D CNNs on high resolution medical volumes is very computationally demanding, especially for large datasets like the UK Biobank which aims to scan 100,000 subjects. Here we demonstrate that using 2D CNNs on a few 2D projections (representing mean and standard deviation across axial, sagittal and coronal slices) of the 3D volumes leads to reasonable test accuracy when predicting the age from brain volumes. Using our approach, one training epoch with 20,324 subjects takes 40 - 70 seconds using a single GPU, which is almost 100 times faster compared to a small 3D CNN. These results are important for researchers who do not have access to expensive GPU hardware for 3D CNNs.
Does an ensemble of GANs lead to better performance when training segmentation networks with synthetic images?
Nov 08, 2022Large annotated datasets are required to train segmentation networks. In medical imaging, it is often difficult, time consuming and expensive to create such datasets, and it may also be difficult to share these datasets with other researchers. Different AI models can today generate very realistic synthetic images, which can potentially be openly shared as they do not belong to specific persons. However, recent work has shown that using synthetic images for training deep networks often leads to worse performance compared to using real images. Here we demonstrate that using synthetic images and annotations from an ensemble of 10 GANs, instead of from a single GAN, increases the Dice score on real test images with 4.7 % to 14.0 % on specific classes.
NUQ: A Noise Metric for Diffusion MRI via Uncertainty Discrepancy Quantification
Mar 04, 2022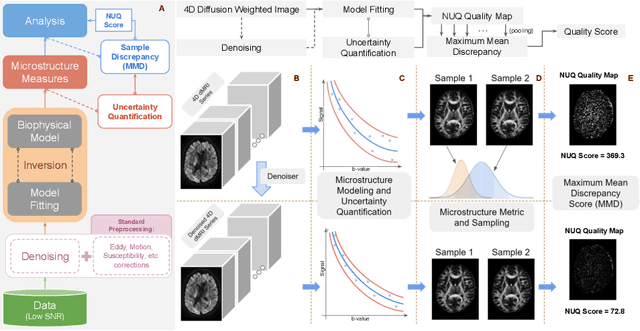
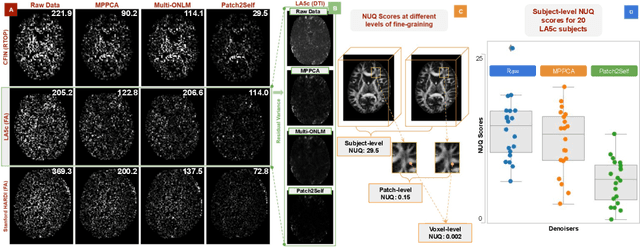
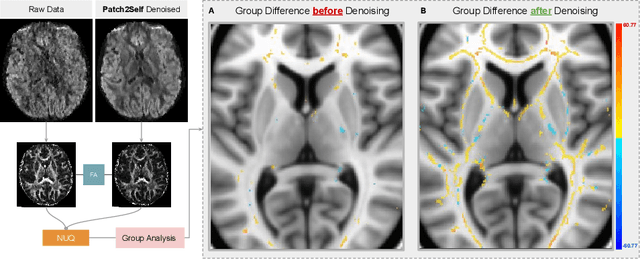
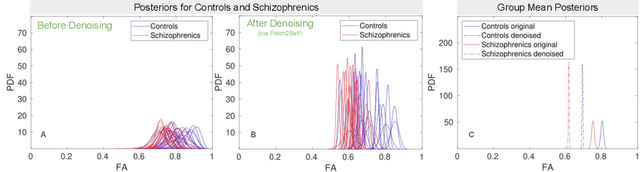
Diffusion MRI (dMRI) is the only non-invasive technique sensitive to tissue micro-architecture, which can, in turn, be used to reconstruct tissue microstructure and white matter pathways. The accuracy of such tasks is hampered by the low signal-to-noise ratio in dMRI. Today, the noise is characterized mainly by visual inspection of residual maps and estimated standard deviation. However, it is hard to estimate the impact of noise on downstream tasks based only on such qualitative assessments. To address this issue, we introduce a novel metric, Noise Uncertainty Quantification (NUQ), for quantitative image quality analysis in the absence of a ground truth reference image. NUQ uses a recent Bayesian formulation of dMRI models to estimate the uncertainty of microstructural measures. Specifically, NUQ uses the maximum mean discrepancy metric to compute a pooled quality score by comparing samples drawn from the posterior distribution of the microstructure measures. We show that NUQ allows a fine-grained analysis of noise, capturing details that are visually imperceptible. We perform qualitative and quantitative comparisons on real datasets, showing that NUQ generates consistent scores across different denoisers and acquisitions. Lastly, by using NUQ on a cohort of schizophrenics and controls, we quantify the substantial impact of denoising on group differences.
Inflation of test accuracy due to data leakage in deep learning-based classification of OCT images
Feb 21, 2022



In the application of deep learning on optical coherence tomography (OCT) data, it is common to train classification networks using 2D images originating from volumetric data. Given the micrometer resolution of OCT systems, consecutive images are often very similar in both visible structures and noise. Thus, an inappropriate data split can result in overlap between the training and testing sets, with a large portion of the literature overlooking this aspect. In this study, the effect of improper dataset splitting on model evaluation is demonstrated for two classification tasks using two OCT open-access datasets extensively used in the literature, Kermany's ophthalmology dataset and AIIMS breast tissue dataset. Our results show that the classification accuracy is inflated by 3.9 to 26 percentage units for models tested on a dataset with improper splitting, highlighting the considerable effect of dataset handling on model evaluation. This study intends to raise awareness on the importance of dataset splitting for research on deep learning using OCT data and volumetric data in general.
Evaluation of augmentation methods in classifying autism spectrum disorders from fMRI data with 3D convolutional neural networks
Oct 20, 2021

Classifying subjects as healthy or diseased using neuroimaging data has gained a lot of attention during the last 10 years. Here we apply deep learning to derivatives from resting state fMRI data, and investigate how different 3D augmentation techniques affect the test accuracy. Specifically, we use resting state derivatives from 1,112 subjects in ABIDE preprocessed to train a 3D convolutional neural network (CNN) to perform the classification. Our results show that augmentation only provide minor improvements to the test accuracy.
Does contextual information improve 3D U-Net based brain tumor segmentation?
Oct 26, 2020

Effective, robust and automatic tools for brain tumor segmentation are needed for extraction of information useful in treatment planning. In recent years, convolutional neural networks have shown state-of-the-art performance in the identification of tumor regions in magnetic resonance (MR) images. A large portion of the current research is devoted to the development of new network architectures to improve segmentation accuracy. In this work it is instead investigated if the addition of contextual information in the form of white matter (WM), gray matter (GM) and cerebrospinal fluid (CSF) masks improves U-Net based brain tumor segmentation. The BraTS 2020 dataset was used to train and test a standard 3D U-Net model that, in addition to the conventional MR image modalities, used the contextual information as extra channels. For comparison, a baseline model that only used the conventional MR image modalities was also trained. Dice scores of 80.76 and 79.58 were obtained for the baseline and the contextual information models, respectively. Results show that there is no statistically significant difference when comparing Dice scores of the two models on the test dataset p > 0.5. In conclusion, there is no improvement in segmentation performance when using contextual information as extra channels.
What is the best data augmentation approach for brain tumor segmentation using 3D U-Net?
Oct 26, 2020

Training segmentation networks requires large annotated datasets, which in medical imaging can be hard to obtain. Despite this fact, data augmentation has in our opinion not been fully explored for brain tumor segmentation (a possible explanation is that the number of training subjects (369) is rather large in the BraTS 2020 dataset). Here we apply different types of data augmentation (flipping, rotation, scaling, brightness adjustment, elastic deformation) when training a standard 3D U-Net, and demonstrate that augmentation significantly improves performance on the validation set (125 subjects) in many cases. Our conclusion is that brightness augmentation and elastic deformation works best, and that combinations of different augmentation techniques do not provide further improvement compared to only using one augmentation technique.