 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Projected Gradient Descent Method for CRF Inference allowing End-To-End Training of Arbitrary Pairwise Potentials
Paper and Code
Jan 02, 2018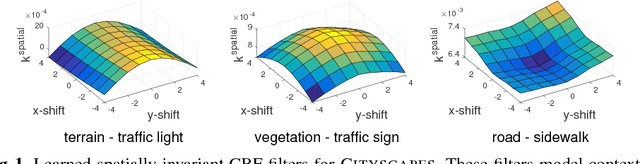
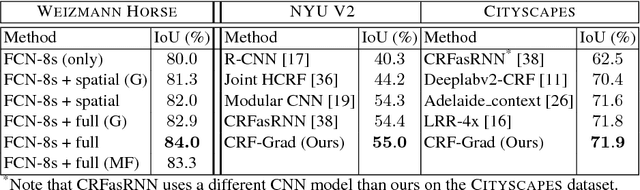
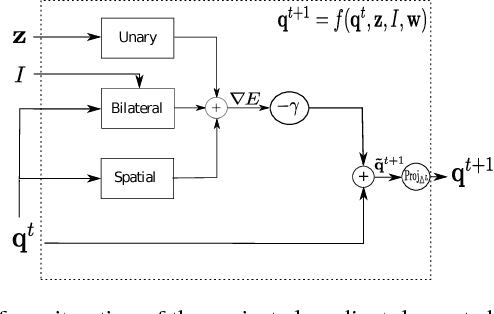

Are we using the right potential functions in the Conditional Random Field models that are popular in the Vision community? Semantic segmentation and other pixel-level labelling tasks have made significant progress recently due to the deep learning paradigm. However, most state-of-the-art structured prediction methods also include a random field model with a hand-crafted Gaussian potential to model spatial priors, label consistencies and feature-based image conditioning. In this paper, we challenge this view by developing a new inference and learning framework which can learn pairwise CRF potentials restricted only by their dependence on the image pixel values and the size of the support. Both standard spatial and high-dimensional bilateral kernels are considered. Our framework is based on the observation that CRF inference can be achieved via projected gradient descent and consequently, can easily be integrated in deep neural networks to allow for end-to-end training. It is empirically demonstrated that such learned potentials can improve segmentation accuracy and that certain label class interactions are indeed better modelled by a non-Gaussian potential. In addition, we compare our inference method to the commonly used mean-field algorithm. Our framework is evaluated on several public benchmarks for semantic segmentation with improved performance compared to previous state-of-the-art CNN+CRF models.