 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Chamfer Distance: Granular Order-aware Evaluation Metric For Online Mapping
May 21, 2026Online map estimation is a crucial component of autonomous driving systems that reduces the reliance on costly high-definition maps. State-of-the-art (SOTA) methods commonly predict map elements as ordered sequences of points that form polylines and polygons. The evaluation of these methods relies predominantly on mean average precision (mAP) based on thresholded Chamfer distance (CD). This framework lacks sensitivity to point ordering and provides limited granularity in assessing geometric quality, making it difficult to distinguish which methods truly excel over others. In this work, we address these limitations on two fronts. For the single-instance similarity measure, we introduce sequence optimal sub-pattern assignment (SOSPA), an order-aware metric that enables fine-grained evaluation of individual geometries while satisfying all metric axioms. For the multi-instance evaluation framework, we propose polyline localisation and detection (PLD), a soft metric that jointly captures detection quality and geometric accuracy, replacing the hard thresholding of mAP with a principled soft assignment. Through evaluations on nuScenes, we demonstrate that PLD effectively ranks SOTA online mapping methods (MapTRv2, StreamMapNet, MapTracker) while providing a decomposed error analysis. This analysis identifies detection capability as the dominant bottleneck in current methods, revealing a performance trend that mAP fails to capture. Code for evaluation using our metrics will be released.
Semi-Supervised Hierarchical Open-Set Classification
Jan 23, 2026Hierarchical open-set classification handles previously unseen classes by assigning them to the most appropriate high-level category in a class taxonomy. We extend this paradigm to the semi-supervised setting, enabling the use of large-scale, uncurated datasets containing a mixture of known and unknown classes to improve the hierarchical open-set performance. To this end, we propose a teacher-student framework based on pseudo-labeling. Two key components are introduced: 1) subtree pseudo-labels, which provide reliable supervision in the presence of unknown data, and 2) age-gating, a mechanism that mitigates overconfidence in pseudo-labels. Experiments show that our framework outperforms self-supervised pretraining followed by supervised adaptation, and even matches the fully supervised counterpart when using only 20 labeled samples per class on the iNaturalist19 benchmark. Our code is available at https://github.com/walline/semihoc.
NeuRadar: Neural Radiance Fields for Automotive Radar Point Clouds
Apr 01, 2025Radar is an important sensor for autonomous driving (AD) systems due to its robustness to adverse weather and different lighting conditions. Novel view synthesis using neural radiance fields (NeRFs) has recently received considerable attention in AD due to its potential to enable efficient testing and validation but remains unexplored for radar point clouds. In this paper, we present NeuRadar, a NeRF-based model that jointly generates radar point clouds, camera images, and lidar point clouds. We explore set-based object detection methods such as DETR, and propose an encoder-based solution grounded in the NeRF geometry for improved generalizability. We propose both a deterministic and a probabilistic point cloud representation to accurately model the radar behavior, with the latter being able to capture radar's stochastic behavior. We achieve realistic reconstruction results for two automotive datasets, establishing a baseline for NeRF-based radar point cloud simulation models. In addition, we release radar data for ZOD's Sequences and Drives to enable further research in this field. To encourage further development of radar NeRFs, we release the source code for NeuRadar.
ProHOC: Probabilistic Hierarchical Out-of-Distribution Classification via Multi-Depth Networks
Mar 27, 2025Out-of-distribution (OOD) detection in deep learning has traditionally been framed as a binary task, where samples are either classified as belonging to the known classes or marked as OOD, with little attention given to the semantic relationships between OOD samples and the in-distribution (ID) classes. We propose a framework for detecting and classifying OOD samples in a given class hierarchy. Specifically, we aim to predict OOD data to their correct internal nodes of the class hierarchy, whereas the known ID classes should be predicted as their corresponding leaf nodes. Our approach leverages the class hierarchy to create a probabilistic model and we implement this model by using networks trained for ID classification at multiple hierarchy depths. We conduct experiments on three datasets with predefined class hierarchies and show the effectiveness of our method. Our code is available at https://github.com/walline/prohoc.
GASP: Unifying Geometric and Semantic Self-Supervised Pre-training for Autonomous Driving
Mar 19, 2025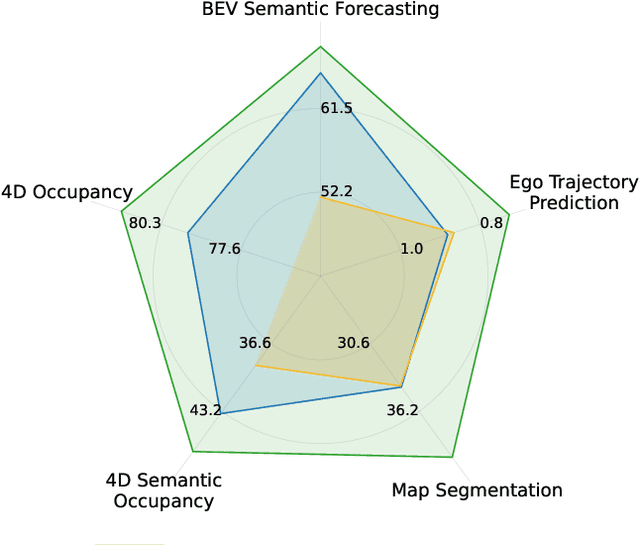
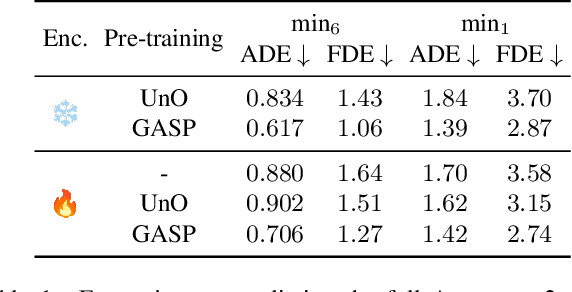
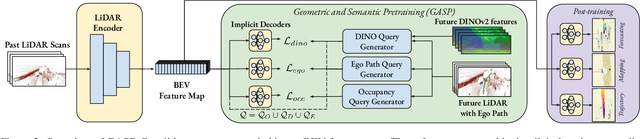
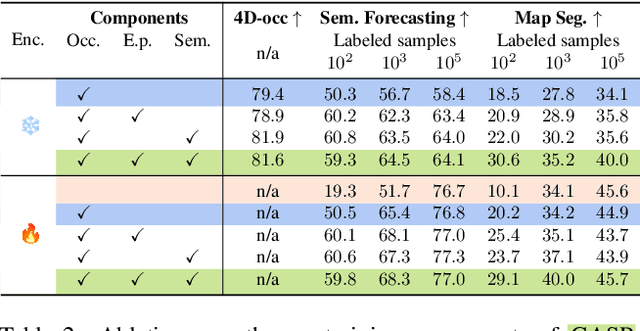
Self-supervised pre-training based on next-token prediction has enabled large language models to capture the underlying structure of text, and has led to unprecedented performance on a large array of tasks when applied at scale. Similarly, autonomous driving generates vast amounts of spatiotemporal data, alluding to the possibility of harnessing scale to learn the underlying geometric and semantic structure of the environment and its evolution over time. In this direction, we propose a geometric and semantic self-supervised pre-training method, GASP, that learns a unified representation by predicting, at any queried future point in spacetime, (1) general occupancy, capturing the evolving structure of the 3D scene; (2) ego occupancy, modeling the ego vehicle path through the environment; and (3) distilled high-level features from a vision foundation model. By modeling geometric and semantic 4D occupancy fields instead of raw sensor measurements, the model learns a structured, generalizable representation of the environment and its evolution through time. We validate GASP on multiple autonomous driving benchmarks, demonstrating significant improvements in semantic occupancy forecasting, online mapping, and ego trajectory prediction. Our results demonstrate that continuous 4D geometric and semantic occupancy prediction provides a scalable and effective pre-training paradigm for autonomous driving. For code and additional visualizations, see \href{https://research.zenseact.com/publications/gasp/.
Exploring Semi-Supervised Learning for Online Mapping
Oct 14, 2024Online mapping is important for scaling autonomous driving beyond well-defined areas. Training a model to produce a local map, including lane markers, road edges, and pedestrian crossings using only onboard sensory information, traditionally requires extensive labelled data, which is difficult and costly to obtain. This paper draws inspiration from semi-supervised learning techniques in other domains, demonstrating their applicability to online mapping. Additionally, we propose a simple yet effective method to exploit inherent attributes of online mapping to further enhance performance by fusing the teacher's pseudo-labels from multiple samples. The performance gap to using all labels is reduced from 29.6 to 3.4 mIoU on Argoverse, and from 12 to 3.4 mIoU on NuScenes utilising only 10% of the labelled data. We also demonstrate strong performance in extrapolating to new cities outside those in the training data. Specifically, for challenging nuScenes, adapting from Boston to Singapore, performance increases by 6.6 mIoU when unlabelled data from Singapore is included in training.
ProSub: Probabilistic Open-Set Semi-Supervised Learning with Subspace-Based Out-of-Distribution Detection
Jul 16, 2024In open-set semi-supervised learning (OSSL), we consider unlabeled datasets that may contain unknown classes. Existing OSSL methods often use the softmax confidence for classifying data as in-distribution (ID) or out-of-distribution (OOD). Additionally, many works for OSSL rely on ad-hoc thresholds for ID/OOD classification, without considering the statistics of the problem. We propose a new score for ID/OOD classification based on angles in feature space between data and an ID subspace. Moreover, we propose an approach to estimate the conditional distributions of scores given ID or OOD data, enabling probabilistic predictions of data being ID or OOD. These components are put together in a framework for OSSL, termed \emph{ProSub}, that is experimentally shown to reach SOTA performance on several benchmark problems. Our code is available at https://github.com/walline/prosub.
Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap
Mar 24, 2024Neural Radiance Fields (NeRFs) have emerged as promising tools for advancing autonomous driving (AD) research, offering scalable closed-loop simulation and data augmentation capabilities. However, to trust the results achieved in simulation, one needs to ensure that AD systems perceive real and rendered data in the same way. Although the performance of rendering methods is increasing, many scenarios will remain inherently challenging to reconstruct faithfully. To this end, we propose a novel perspective for addressing the real-to-simulated data gap. Rather than solely focusing on improving rendering fidelity, we explore simple yet effective methods to enhance perception model robustness to NeRF artifacts without compromising performance on real data. Moreover, we conduct the first large-scale investigation into the real-to-simulated data gap in an AD setting using a state-of-the-art neural rendering technique. Specifically, we evaluate object detectors and an online mapping model on real and simulated data, and study the effects of different pre-training strategies. Our results show notable improvements in model robustness to simulated data, even improving real-world performance in some cases. Last, we delve into the correlation between the real-to-simulated gap and image reconstruction metrics, identifying FID and LPIPS as strong indicators.
Localization Is All You Evaluate: Data Leakage in Online Mapping Datasets and How to Fix It
Dec 11, 2023Data leakage is a critical issue when training and evaluating any method based on supervised learning. The state-of-the-art methods for online mapping are based on supervised learning and are trained predominantly using two datasets: nuScenes and Argoverse 2. These datasets revisit the same geographic locations across training, validation, and test sets. Specifically, over $80$% of nuScenes and $40$% of Argoverse 2 validation and test samples are located less than $5$ m from a training sample. This allows methods to localize within a memorized implicit map during testing and leads to inflated performance numbers being reported. To reveal the true performance in unseen environments, we introduce geographical splits of the data. Experimental results show significantly lower performance numbers, for some methods dropping with more than $45$ mAP, when retraining and reevaluating existing online mapping models with the proposed split. Additionally, a reassessment of prior design choices reveals diverging conclusions from those based on the original split. Notably, the impact of the lifting method and the support from auxiliary tasks (e.g., depth supervision) on performance appears less substantial or follows a different trajectory than previously perceived. Geographical splits can be found https://github.com/LiljaAdam/geographical-splits
Improving Open-Set Semi-Supervised Learning with Self-Supervision
Jan 24, 2023
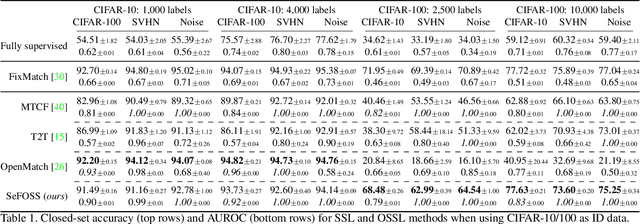
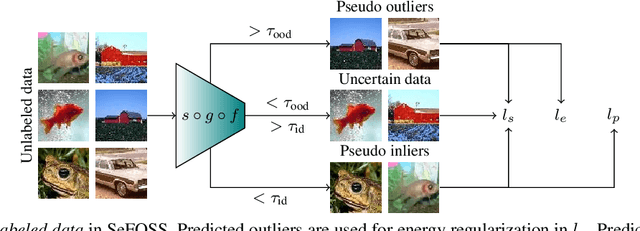

Open-set semi-supervised learning (OSSL) is a realistic setting of semi-supervised learning where the unlabeled training set contains classes that are not present in the labeled set. Many existing OSSL methods assume that these out-of-distribution data are harmful and put effort into excluding data from unknown classes from the training objective. In contrast, we propose an OSSL framework that facilitates learning from all unlabeled data through self-supervision. Additionally, we utilize an energy-based score to accurately recognize data belonging to the known classes, making our method well-suited for handling uncurated data in deployment. We show through extensive experimental evaluations on several datasets that our method shows overall unmatched robustness and performance in terms of closed-set accuracy and open-set recognition compared with state-of-the-art for OSSL. Our code will be released upon publication.