 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubleMatch: Improving Semi-Supervised Learning with Self-Supervision
Paper and Code
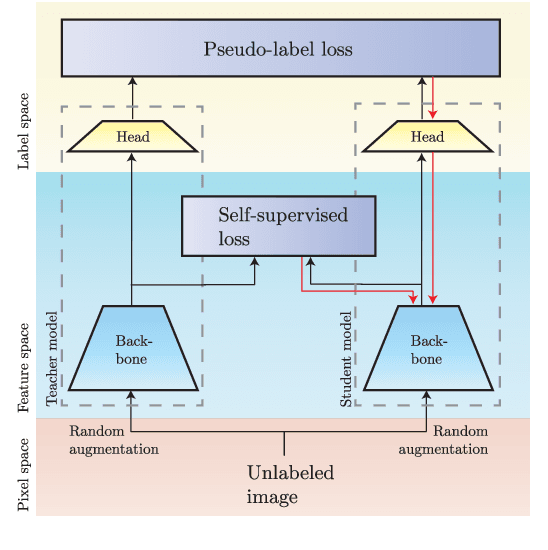
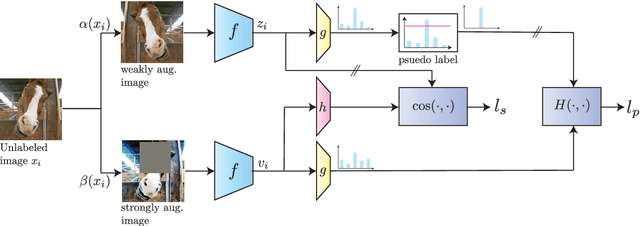
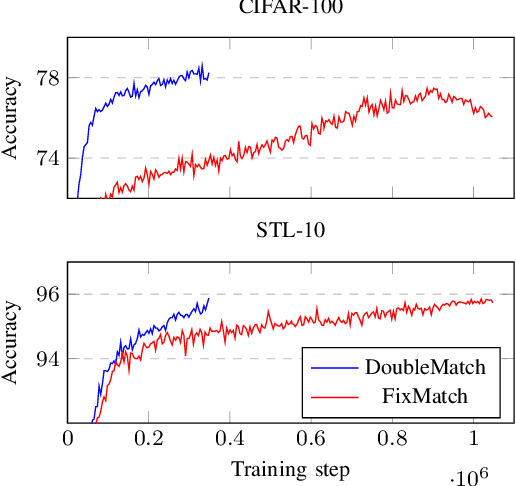
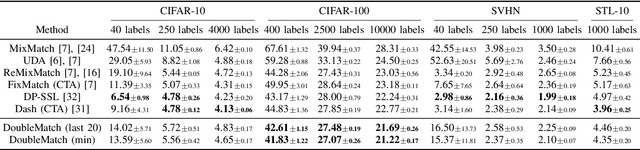
Following the success of supervised learning, semi-supervised learning (SSL) is now becoming increasingly popular. SSL is a family of methods, which in addition to a labeled training set, also use a sizable collection of unlabeled data for fitting a model. Most of the recent successful SSL methods are based on pseudo-labeling approaches: letting confident model predictions act as training labels. While these methods have shown impressive results on many benchmark datasets, a drawback of this approach is that not all unlabeled data are used during training. We propose a new SSL algorithm, DoubleMatch, which combines the pseudo-labeling technique with a self-supervised loss, enabling the model to utilize all unlabeled data in the training process. We show that this method achieves state-of-the-art accuracies on multiple benchmark datasets while also reducing training times compared to existing SSL methods. Code is available at https://github.com/walline/doublematch.