 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Global Geo-alignment for Precision Learned Autonomous Vehicle Localization using Aerial Data
Mar 18, 2025

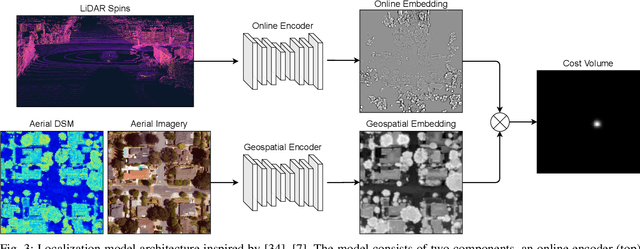

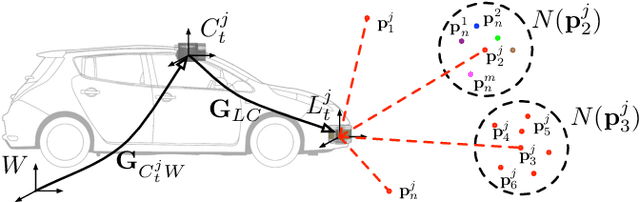
Recently there has been growing interest in the use of aerial and satellite map data for autonomous vehicles, primarily due to its potential for significant cost reduction and enhanced scalability. Despite the advantages, aerial data also comes with challenges such as a sensor-modality gap and a viewpoint difference gap. Learned localization methods have shown promise for overcoming these challenges to provide precise metric localization for autonomous vehicles. Most learned localization methods rely on coarsely aligned ground truth, or implicit consistency-based methods to learn the localization task -- however, in this paper we find that improving the alignment between aerial data and autonomous vehicle sensor data at training time is critical to the performance of a learning-based localization system. We compare two data alignment methods using a factor graph framework and, using these methods, we then evaluate the effects of closely aligned ground truth on learned localization accuracy through ablation studies. Finally, we evaluate a learned localization system using the data alignment methods on a comprehensive (1600km) autonomous vehicle dataset and demonstrate localization error below 0.3m and 0.5$^{\circ}$ sufficient for autonomous vehicle applications.
Exploring Real World Map Change Generalization of Prior-Informed HD Map Prediction Models
Jun 04, 2024



Building and maintaining High-Definition (HD) maps represents a large barrier to autonomous vehicle deployment. This, along with advances in modern online map detection models, has sparked renewed interest in the online mapping problem. However, effectively predicting online maps at a high enough quality to enable safe, driverless deployments remains a significant challenge. Recent work on these models proposes training robust online mapping systems using low quality map priors with synthetic perturbations in an attempt to simulate out-of-date HD map priors. In this paper, we investigate how models trained on these synthetically perturbed map priors generalize to performance on deployment-scale, real world map changes. We present a large-scale experimental study to determine which synthetic perturbations are most useful in generalizing to real world HD map changes, evaluated using multiple years of real-world autonomous driving data. We show there is still a substantial sim2real gap between synthetic prior perturbations and observed real-world changes, which limits the utility of current prior-informed HD map prediction models.
Real-time Kinematic Ground Truth for the Oxford RobotCar Dataset
Feb 24, 2020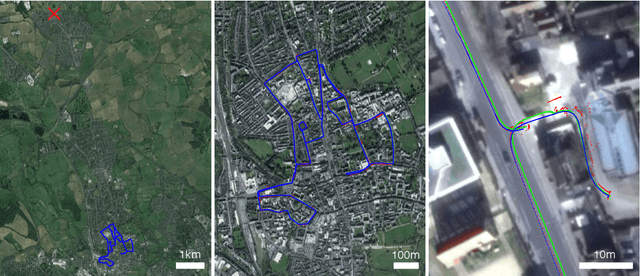

We describe the release of reference data towards a challenging long-term localisation and mapping benchmark based on the large-scale Oxford RobotCar Dataset. The release includes 72 traversals of a route through Oxford, UK, gathered in all illumination, weather and traffic conditions, and is representative of the conditions an autonomous vehicle would be expected to operate reliably in. Using post-processed raw GPS, IMU, and static GNSS base station recordings, we have produced a globally-consistent centimetre-accurate ground truth for the entire year-long duration of the dataset. Coupled with a planned online benchmarking service, we hope to enable quantitative evaluation and comparison of different localisation and mapping approaches focusing on long-term autonomy for road vehicles in urban environments challenged by changing weather.
Distant Vehicle Detection Using Radar and Vision
Jan 30, 2019
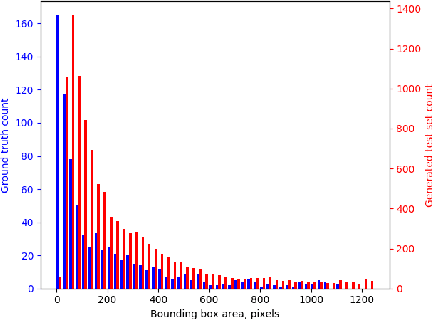

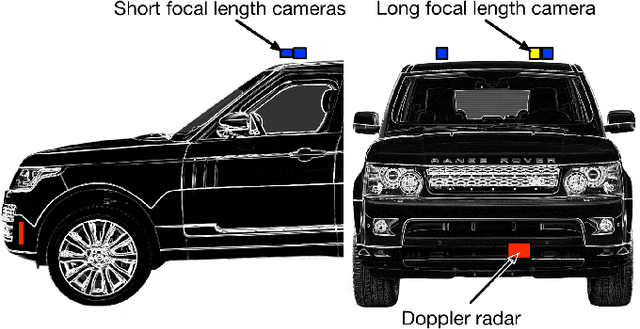
For autonomous vehicles to be able to operate successfully they need to be aware of other vehicles with sufficient time to make safe, stable plans. Given the possible closing speeds between two vehicles, this necessitates the ability to accurately detect distant vehicles. Many current image-based object detectors using convolutional neural networks exhibit excellent performance on existing datasets such as KITTI. However, the performance of these networks falls when detecting small (distant) objects. We demonstrate that incorporating radar data can boost performance in these difficult situations. We also introduce an efficient automated method for training data generation using cameras of different focal lengths.
Benchmarking 6DOF Outdoor Visual Localization in Changing Conditions
Apr 04, 2018



Visual localization enables autonomous vehicles to navigate in their surroundings and augmented reality applications to link virtual to real worlds. Practical visual localization approaches need to be robust to a wide variety of viewing condition, including day-night changes, as well as weather and seasonal variations, while providing highly accurate 6 degree-of-freedom (6DOF) camera pose estimates. In this paper, we introduce the first benchmark datasets specifically designed for analyzing the impact of such factors on visual localization. Using carefully created ground truth poses for query images taken under a wide variety of conditions, we evaluate the impact of various factors on 6DOF camera pose estimation accuracy through extensive experiments with state-of-the-art localization approaches. Based on our results, we draw conclusions about the difficulty of different conditions, showing that long-term localization is far from solved, and propose promising avenues for future work, including sequence-based localization approaches and the need for better local features. Our benchmark is available at visuallocalization.net.
Adversarial Training for Adverse Conditions: Robust Metric Localisation using Appearance Transfer
Mar 09, 2018

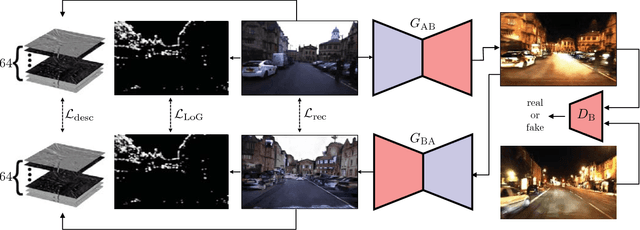

We present a method of improving visual place recognition and metric localisation under very strong appear- ance change. We learn an invertable generator that can trans- form the conditions of images, e.g. from day to night, summer to winter etc. This image transforming filter is explicitly designed to aid and abet feature-matching using a new loss based on SURF detector and dense descriptor maps. A network is trained to output synthetic images optimised for feature matching given only an input RGB image, and these generated images are used to localize the robot against a previously built map using traditional sparse matching approaches. We benchmark our results using multiple traversals of the Oxford RobotCar Dataset over a year-long period, using one traversal as a map and the other to localise. We show that this method significantly improves place recognition and localisation under changing and adverse conditions, while reducing the number of mapping runs needed to successfully achieve reliable localisation.
Driven to Distraction: Self-Supervised Distractor Learning for Robust Monocular Visual Odometry in Urban Environments
Mar 05, 2018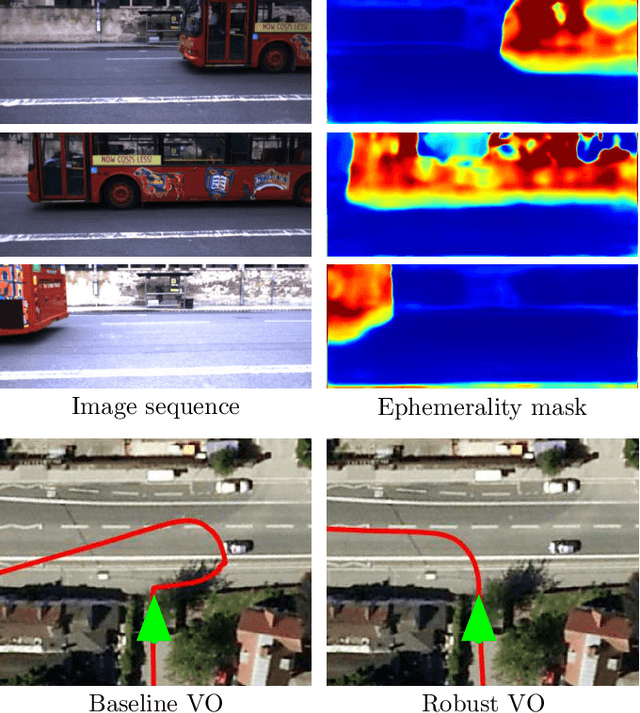

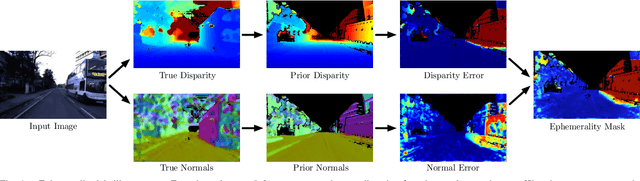
We present a self-supervised approach to ignoring "distractors" in camera images for the purposes of robustly estimating vehicle motion in cluttered urban environments. We leverage offline multi-session mapping approaches to automatically generate a per-pixel ephemerality mask and depth map for each input image, which we use to train a deep convolutional network. At run-time we use the predicted ephemerality and depth as an input to a monocular visual odometry (VO) pipeline, using either sparse features or dense photometric matching. Our approach yields metric-scale VO using only a single camera and can recover the correct egomotion even when 90% of the image is obscured by dynamic, independently moving objects. We evaluate our robust VO methods on more than 400km of driving from the Oxford RobotCar Dataset and demonstrate reduced odometry drift and significantly improved egomotion estimation in the presence of large moving vehicles in urban traffic.
Find Your Own Way: Weakly-Supervised Segmentation of Path Proposals for Urban Autonomy
Nov 17, 2017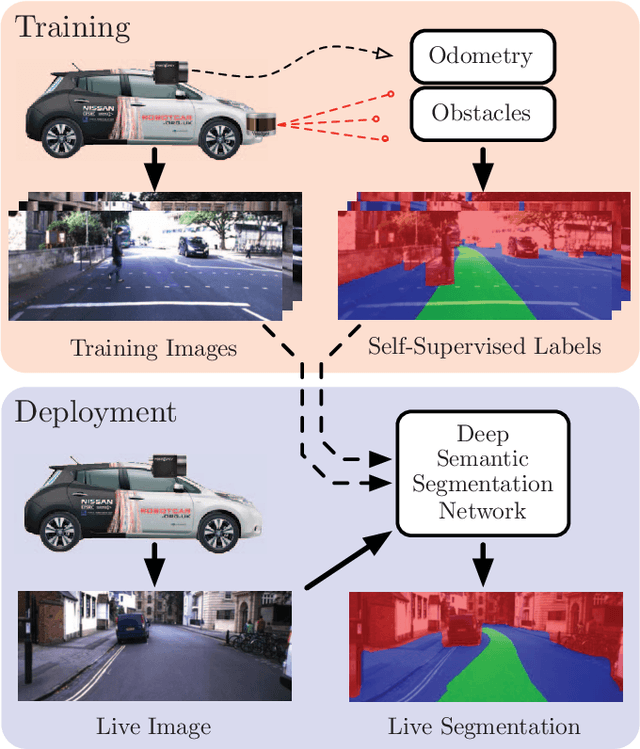



We present a weakly-supervised approach to segmenting proposed drivable paths in images with the goal of autonomous driving in complex urban environments. Using recorded routes from a data collection vehicle, our proposed method generates vast quantities of labelled images containing proposed paths and obstacles without requiring manual annotation, which we then use to train a deep semantic segmentation network. With the trained network we can segment proposed paths and obstacles at run-time using a vehicle equipped with only a monocular camera without relying on explicit modelling of road or lane markings. We evaluate our method on the large-scale KITTI and Oxford RobotCar datasets and demonstrate reliable path proposal and obstacle segmentation in a wide variety of environments under a range of lighting, weather and traffic conditions. We illustrate how the method can generalise to multiple path proposals at intersections and outline plans to incorporate the system into a framework for autonomous urban driving.