 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Global Geo-alignment for Precision Learned Autonomous Vehicle Localization using Aerial Data
Mar 18, 2025

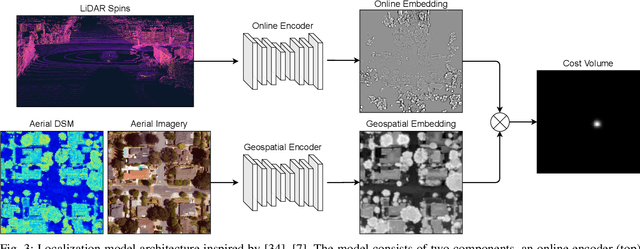

Recently there has been growing interest in the use of aerial and satellite map data for autonomous vehicles, primarily due to its potential for significant cost reduction and enhanced scalability. Despite the advantages, aerial data also comes with challenges such as a sensor-modality gap and a viewpoint difference gap. Learned localization methods have shown promise for overcoming these challenges to provide precise metric localization for autonomous vehicles. Most learned localization methods rely on coarsely aligned ground truth, or implicit consistency-based methods to learn the localization task -- however, in this paper we find that improving the alignment between aerial data and autonomous vehicle sensor data at training time is critical to the performance of a learning-based localization system. We compare two data alignment methods using a factor graph framework and, using these methods, we then evaluate the effects of closely aligned ground truth on learned localization accuracy through ablation studies. Finally, we evaluate a learned localization system using the data alignment methods on a comprehensive (1600km) autonomous vehicle dataset and demonstrate localization error below 0.3m and 0.5$^{\circ}$ sufficient for autonomous vehicle applications.
A Continuous Optimization Approach for Efficient and Accurate Scene Flow
Jul 27, 2016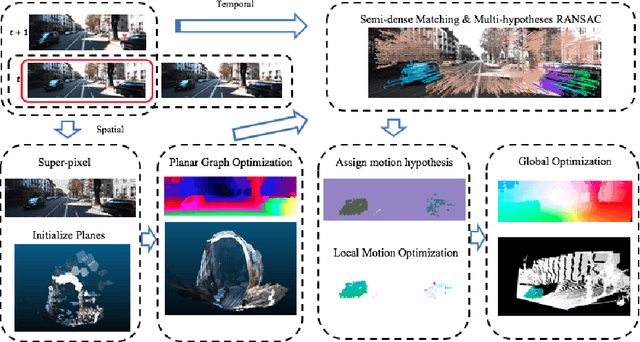

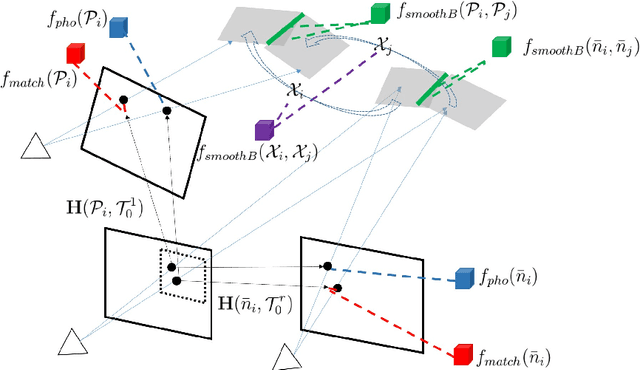

We propose a continuous optimization method for solving dense 3D scene flow problems from stereo imagery. As in recent work, we represent the dynamic 3D scene as a collection of rigidly moving planar segments. The scene flow problem then becomes the joint estimation of pixel-to-segment assignment, 3D position, normal vector and rigid motion parameters for each segment, leading to a complex and expensive discrete-continuous optimization problem. In contrast, we propose a purely continuous formulation which can be solved more efficiently. Using a fine superpixel segmentation that is fixed a-priori, we propose a factor graph formulation that decomposes the problem into photometric, geometric, and smoothing constraints. We initialize the solution with a novel, high-quality initialization method, then independently refine the geometry and motion of the scene, and finally perform a global non-linear refinement using Levenberg-Marquardt. We evaluate our method in the challenging KITTI Scene Flow benchmark, ranking in third position, while being 3 to 30 times faster than the top competitors.