 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriven to Distraction: Self-Supervised Distractor Learning for Robust Monocular Visual Odometry in Urban Environments
Paper and Code
Mar 05, 2018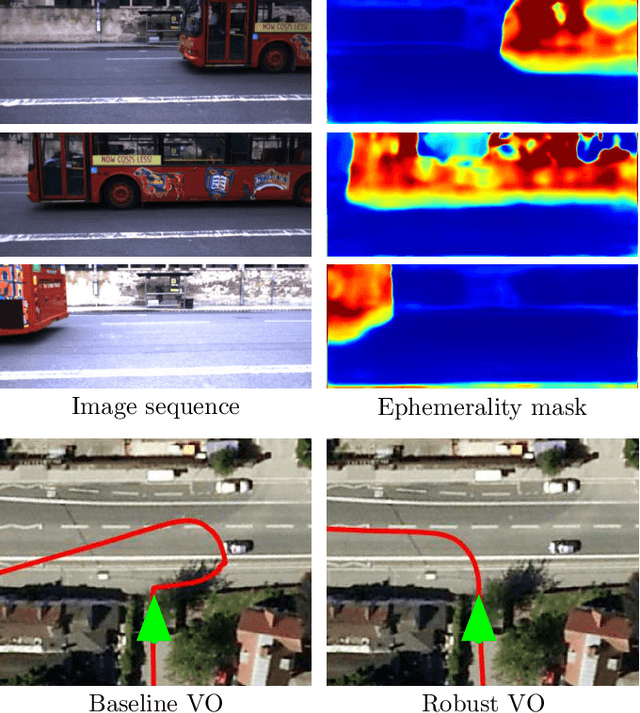
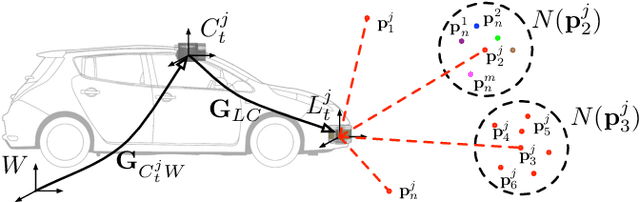

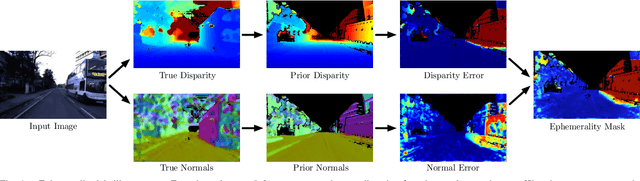
We present a self-supervised approach to ignoring "distractors" in camera images for the purposes of robustly estimating vehicle motion in cluttered urban environments. We leverage offline multi-session mapping approaches to automatically generate a per-pixel ephemerality mask and depth map for each input image, which we use to train a deep convolutional network. At run-time we use the predicted ephemerality and depth as an input to a monocular visual odometry (VO) pipeline, using either sparse features or dense photometric matching. Our approach yields metric-scale VO using only a single camera and can recover the correct egomotion even when 90% of the image is obscured by dynamic, independently moving objects. We evaluate our robust VO methods on more than 400km of driving from the Oxford RobotCar Dataset and demonstrate reduced odometry drift and significantly improved egomotion estimation in the presence of large moving vehicles in urban traffic.