 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINQUIRE: A Natural World Text-to-Image Retrieval Benchmark
Nov 04, 2024We introduce INQUIRE, a text-to-image retrieval benchmark designed to challenge multimodal vision-language models on expert-level queries. INQUIRE includes iNaturalist 2024 (iNat24), a new dataset of five million natural world images, along with 250 expert-level retrieval queries. These queries are paired with all relevant images comprehensively labeled within iNat24, comprising 33,000 total matches. Queries span categories such as species identification, context, behavior, and appearance, emphasizing tasks that require nuanced image understanding and domain expertise. Our benchmark evaluates two core retrieval tasks: (1) INQUIRE-Fullrank, a full dataset ranking task, and (2) INQUIRE-Rerank, a reranking task for refining top-100 retrievals. Detailed evaluation of a range of recent multimodal models demonstrates that INQUIRE poses a significant challenge, with the best models failing to achieve an mAP@50 above 50%. In addition, we show that reranking with more powerful multimodal models can enhance retrieval performance, yet there remains a significant margin for improvement. By focusing on scientifically-motivated ecological challenges, INQUIRE aims to bridge the gap between AI capabilities and the needs of real-world scientific inquiry, encouraging the development of retrieval systems that can assist with accelerating ecological and biodiversity research. Our dataset and code are available at https://inquire-benchmark.github.io
Deep learning-based ecological analysis of camera trap images is impacted by training data quality and size
Aug 26, 2024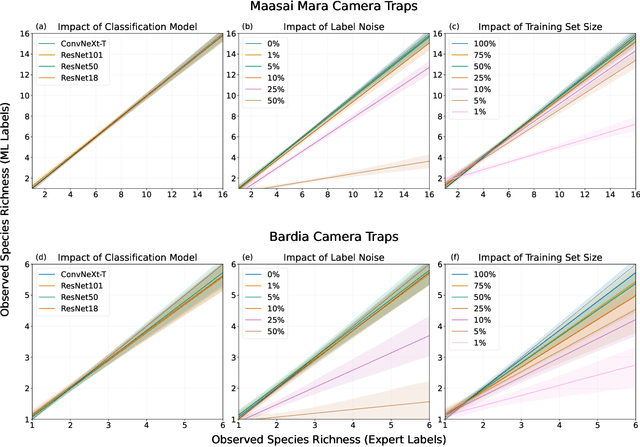
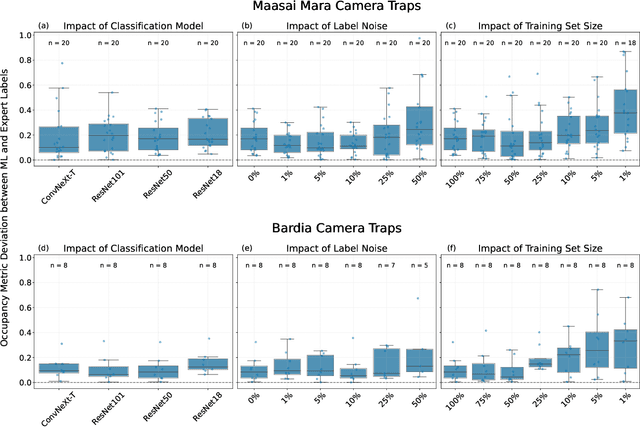
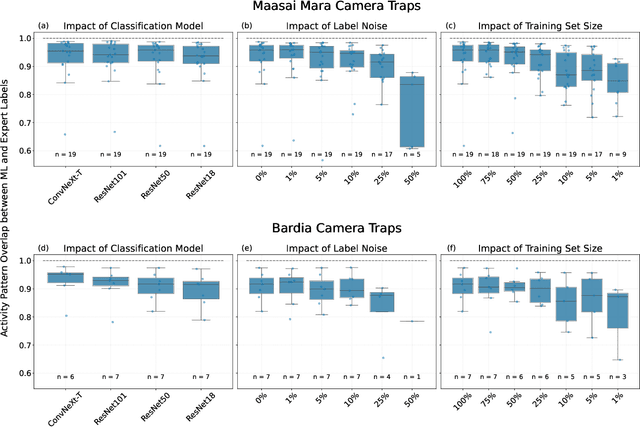
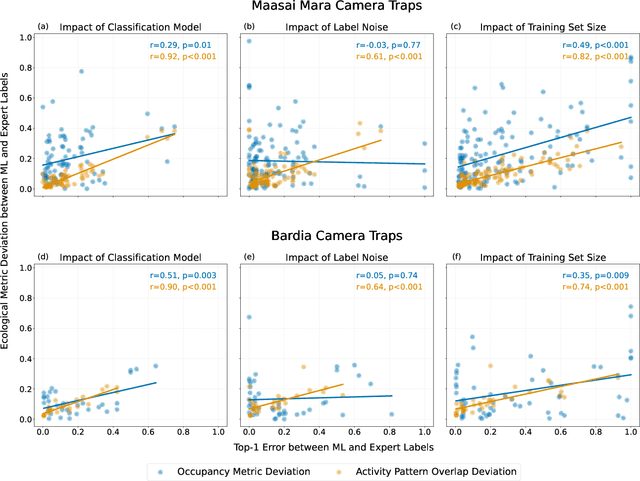
Large wildlife image collections from camera traps are crucial for biodiversity monitoring, offering insights into species richness, occupancy, and activity patterns. However, manual processing of these data is time-consuming, hindering analytical processes. To address this, deep neural networks have been widely adopted to automate image analysis. Despite their growing use, the impact of model training decisions on downstream ecological metrics remains unclear. Here, we analyse camera trap data from an African savannah and an Asian sub-tropical dry forest to compare key ecological metrics derived from expert-generated species identifications with those generated from deep neural networks. We assess the impact of model architecture, training data noise, and dataset size on ecological metrics, including species richness, occupancy, and activity patterns. Our results show that while model architecture has minimal impact, large amounts of noise and reduced dataset size significantly affect these metrics. Nonetheless, estimated ecological metrics are resilient to considerable noise, tolerating up to 10% error in species labels and a 50% reduction in training set size without changing significantly. We also highlight that conventional metrics like classification error may not always be representative of a model's ability to accurately measure ecological metrics. We conclude that ecological metrics derived from deep neural network predictions closely match those calculated from expert labels and remain robust to variations in the factors explored. However, training decisions for deep neural networks can impact downstream ecological analysis. Therefore, practitioners should prioritize creating large, clean training sets and evaluate deep neural network solutions based on their ability to measure the ecological metrics of interest.
SVL-Adapter: Self-Supervised Adapter for Vision-Language Pretrained Models
Oct 07, 2022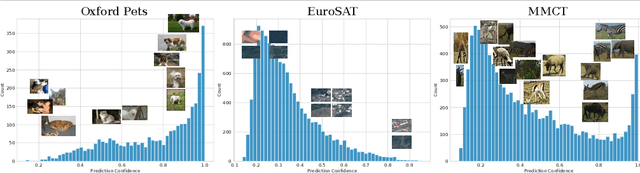
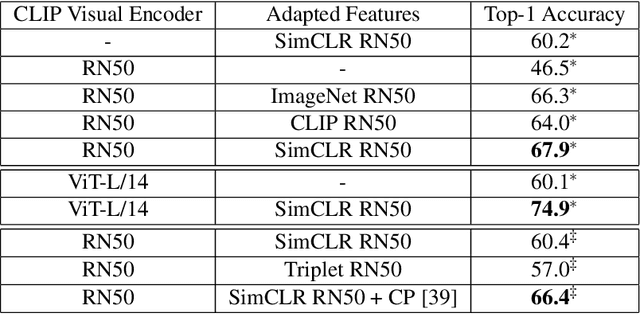
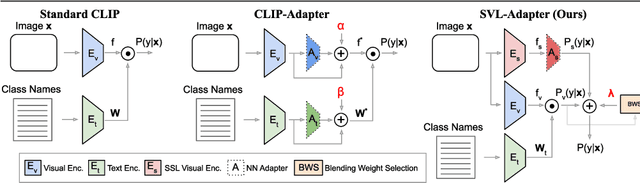
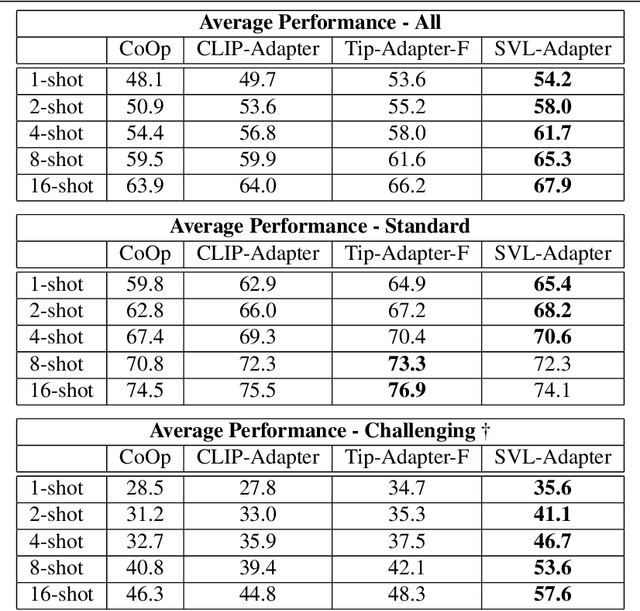
Vision-language models such as CLIP are pretrained on large volumes of internet sourced image and text pairs, and have been shown to sometimes exhibit impressive zero- and low-shot image classification performance. However, due to their size, fine-tuning these models on new datasets can be prohibitively expensive, both in terms of the supervision and compute required. To combat this, a series of light-weight adaptation methods have been proposed to efficiently adapt such models when limited supervision is available. In this work, we show that while effective on internet-style datasets, even those remedies under-deliver on classification tasks with images that differ significantly from those commonly found online. To address this issue, we present a new approach called SVL-Adapter that combines the complementary strengths of both vision-language pretraining and self-supervised representation learning. We report an average classification accuracy improvement of 10% in the low-shot setting when compared to existing methods, on a set of challenging visual classification tasks. Further, we present a fully automatic way of selecting an important blending hyperparameter for our model that does not require any held-out labeled validation data. Code for our project is available here: https://github.com/omipan/svl_adapter.
Matching Multiple Perspectives for Efficient Representation Learning
Aug 16, 2022

Representation learning approaches typically rely on images of objects captured from a single perspective that are transformed using affine transformations. Additionally, self-supervised learning, a successful paradigm of representation learning, relies on instance discrimination and self-augmentations which cannot always bridge the gap between observations of the same object viewed from a different perspective. Viewing an object from multiple perspectives aids holistic understanding of an object which is particularly important in situations where data annotations are limited. In this paper, we present an approach that combines self-supervised learning with a multi-perspective matching technique and demonstrate its effectiveness on learning higher quality representations on data captured by a robotic vacuum with an embedded camera. We show that the availability of multiple views of the same object combined with a variety of self-supervised pretraining algorithms can lead to improved object classification performance without extra labels.
Focus on the Positives: Self-Supervised Learning for Biodiversity Monitoring
Aug 14, 2021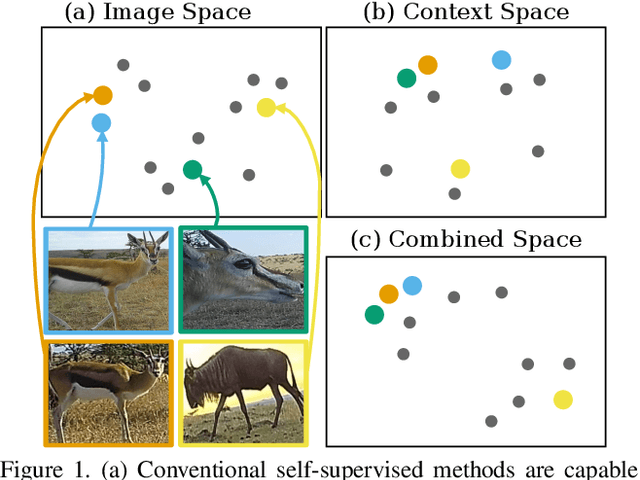


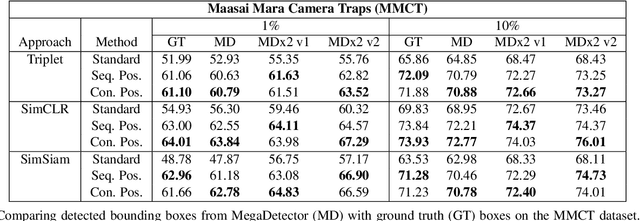
We address the problem of learning self-supervised representations from unlabeled image collections. Unlike existing approaches that attempt to learn useful features by maximizing similarity between augmented versions of each input image or by speculatively picking negative samples, we instead also make use of the natural variation that occurs in image collections that are captured using static monitoring cameras. To achieve this, we exploit readily available context data that encodes information such as the spatial and temporal relationships between the input images. We are able to learn representations that are surprisingly effective for downstream supervised classification, by first identifying high probability positive pairs at training time, i.e. those images that are likely to depict the same visual concept. For the critical task of global biodiversity monitoring, this results in image features that can be adapted to challenging visual species classification tasks with limited human supervision. We present results on four different camera trap image collections, across three different families of self-supervised learning methods, and show that careful image selection at training time results in superior performance compared to existing baselines such as conventional self-supervised training and transfer learning.