 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVL-Adapter: Self-Supervised Adapter for Vision-Language Pretrained Models
Paper and Code
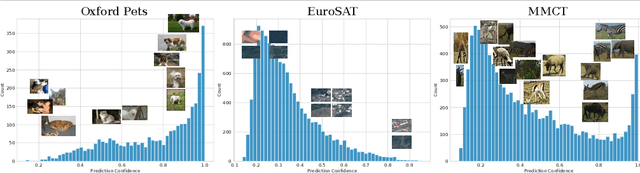
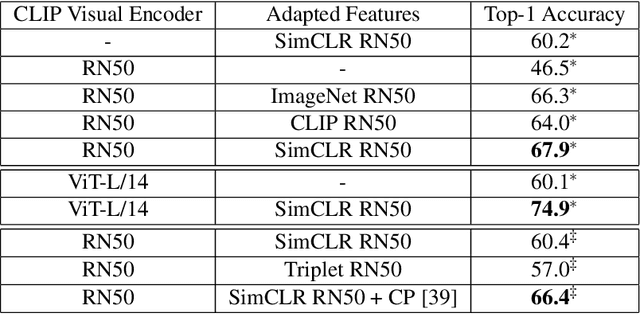
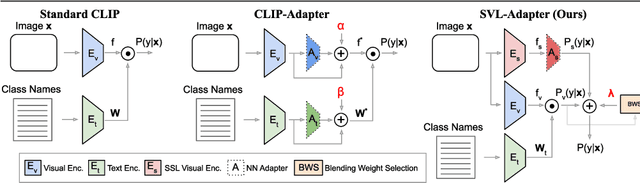
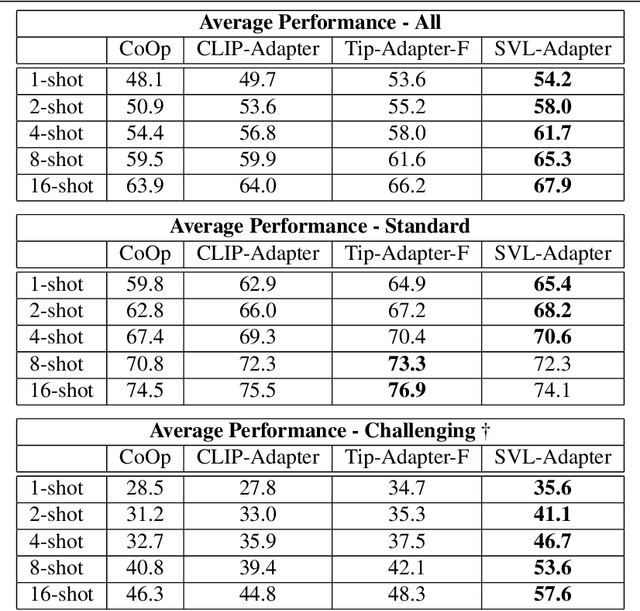
Vision-language models such as CLIP are pretrained on large volumes of internet sourced image and text pairs, and have been shown to sometimes exhibit impressive zero- and low-shot image classification performance. However, due to their size, fine-tuning these models on new datasets can be prohibitively expensive, both in terms of the supervision and compute required. To combat this, a series of light-weight adaptation methods have been proposed to efficiently adapt such models when limited supervision is available. In this work, we show that while effective on internet-style datasets, even those remedies under-deliver on classification tasks with images that differ significantly from those commonly found online. To address this issue, we present a new approach called SVL-Adapter that combines the complementary strengths of both vision-language pretraining and self-supervised representation learning. We report an average classification accuracy improvement of 10% in the low-shot setting when compared to existing methods, on a set of challenging visual classification tasks. Further, we present a fully automatic way of selecting an important blending hyperparameter for our model that does not require any held-out labeled validation data. Code for our project is available here: https://github.com/omipan/svl_adapter.