 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVL-Adapter: Self-Supervised Adapter for Vision-Language Pretrained Models
Oct 07, 2022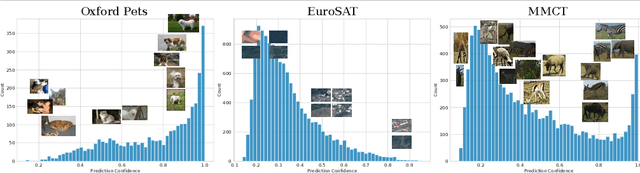
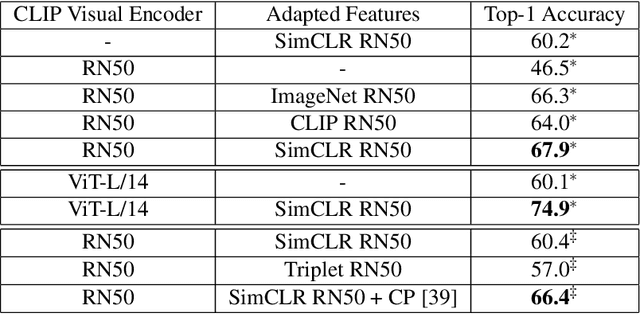
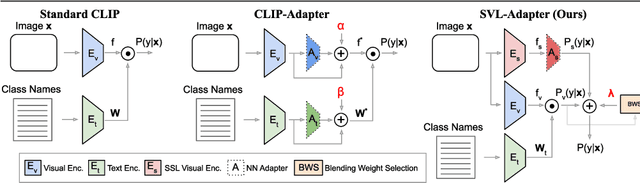
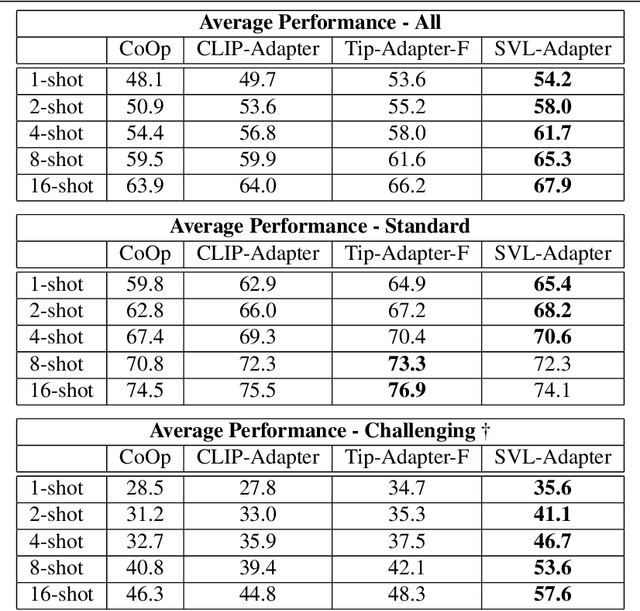
Vision-language models such as CLIP are pretrained on large volumes of internet sourced image and text pairs, and have been shown to sometimes exhibit impressive zero- and low-shot image classification performance. However, due to their size, fine-tuning these models on new datasets can be prohibitively expensive, both in terms of the supervision and compute required. To combat this, a series of light-weight adaptation methods have been proposed to efficiently adapt such models when limited supervision is available. In this work, we show that while effective on internet-style datasets, even those remedies under-deliver on classification tasks with images that differ significantly from those commonly found online. To address this issue, we present a new approach called SVL-Adapter that combines the complementary strengths of both vision-language pretraining and self-supervised representation learning. We report an average classification accuracy improvement of 10% in the low-shot setting when compared to existing methods, on a set of challenging visual classification tasks. Further, we present a fully automatic way of selecting an important blending hyperparameter for our model that does not require any held-out labeled validation data. Code for our project is available here: https://github.com/omipan/svl_adapter.
Focus on the Positives: Self-Supervised Learning for Biodiversity Monitoring
Aug 14, 2021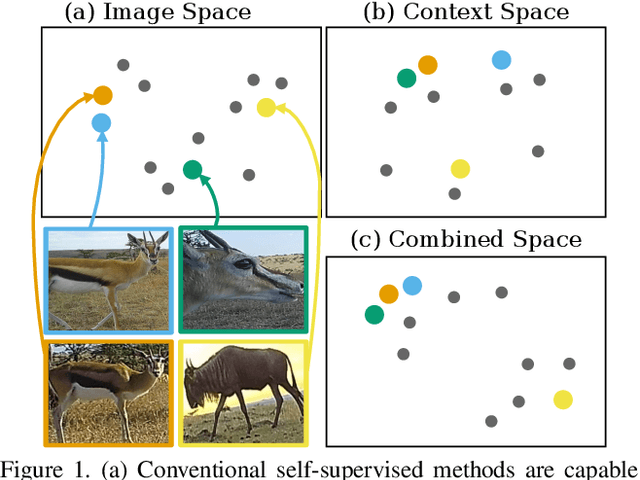


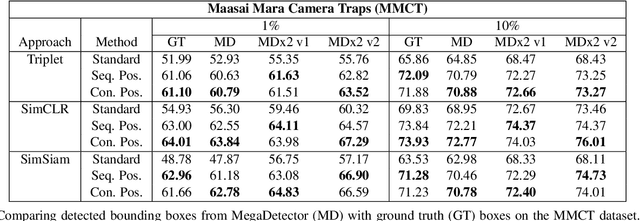
We address the problem of learning self-supervised representations from unlabeled image collections. Unlike existing approaches that attempt to learn useful features by maximizing similarity between augmented versions of each input image or by speculatively picking negative samples, we instead also make use of the natural variation that occurs in image collections that are captured using static monitoring cameras. To achieve this, we exploit readily available context data that encodes information such as the spatial and temporal relationships between the input images. We are able to learn representations that are surprisingly effective for downstream supervised classification, by first identifying high probability positive pairs at training time, i.e. those images that are likely to depict the same visual concept. For the critical task of global biodiversity monitoring, this results in image features that can be adapted to challenging visual species classification tasks with limited human supervision. We present results on four different camera trap image collections, across three different families of self-supervised learning methods, and show that careful image selection at training time results in superior performance compared to existing baselines such as conventional self-supervised training and transfer learning.