 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus on the Positives: Self-Supervised Learning for Biodiversity Monitoring
Paper and Code
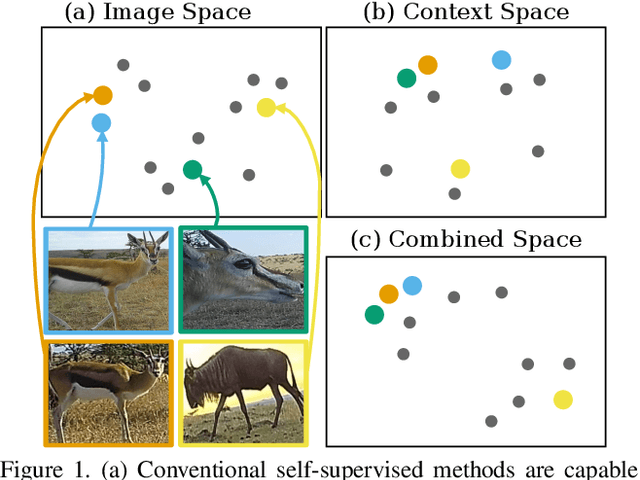


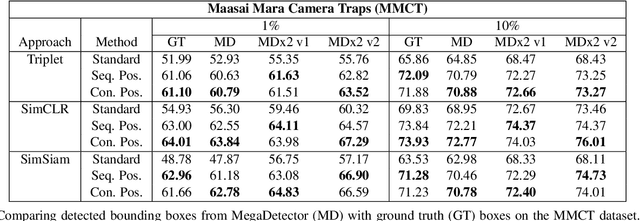
We address the problem of learning self-supervised representations from unlabeled image collections. Unlike existing approaches that attempt to learn useful features by maximizing similarity between augmented versions of each input image or by speculatively picking negative samples, we instead also make use of the natural variation that occurs in image collections that are captured using static monitoring cameras. To achieve this, we exploit readily available context data that encodes information such as the spatial and temporal relationships between the input images. We are able to learn representations that are surprisingly effective for downstream supervised classification, by first identifying high probability positive pairs at training time, i.e. those images that are likely to depict the same visual concept. For the critical task of global biodiversity monitoring, this results in image features that can be adapted to challenging visual species classification tasks with limited human supervision. We present results on four different camera trap image collections, across three different families of self-supervised learning methods, and show that careful image selection at training time results in superior performance compared to existing baselines such as conventional self-supervised training and transfer learning.