 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture of Edge AI in biodiversity monitoring
Feb 13, 20261. Many ecological decisions are slowed by the gap between collecting and analysing biodiversity data. Edge computing moves processing closer to the sensor, with edge artificial intelligence (AI) enabling on-device inference, reducing reliance on data transfer and continuous connectivity. In principle, this shifts biodiversity monitoring from passive logging towards autonomous, responsive sensing systems. In practice, however, adoption remains fragmented, with key architectural trade-offs, performance constraints, and implementation challenges rarely reported systematically. 2. Here, we analyse 82 studies published between 2017 and 2025 that implement edge computing for biodiversity monitoring across acoustic, vision, tracking, and multi-modal systems. We synthesise hardware platforms, AI model optimisation, and wireless communication to critically assess how design choices shape ecological inference, deployment longevity, and operational feasibility. 3. Publications increased from 3 in 2017 to 19 in 2025. We identify four system types: (I) TinyML, low-power microcontrollers (MCUs) for single-taxon or rare-event detection; (II) Edge AI, single-board computers (SBCs) for multi-species classification and real-time alerts; (III) Distributed edge AI; and (IV) Cloud AI for retrospective processing pipelines. Each system type represents context-dependent trade-offs among power consumption, computational capability, and communication requirements. 4. Our analysis reveals the evolution of edge computing systems from proof-of-concept to robust, scalable tools. We argue that edge computing offers opportunities for responsive biodiversity management, but realising this potential requires increased collaboration between ecologists, engineers, and data scientists to align model development and system design with ecological questions, field constraints, and ethical considerations.
acoupi: An Open-Source Python Framework for Deploying Bioacoustic AI Models on Edge Devices
Jan 29, 20251. Passive acoustic monitoring (PAM) coupled with artificial intelligence (AI) is becoming an essential tool for biodiversity monitoring. Traditional PAM systems require manual data offloading and impose substantial demands on storage and computing infrastructure. The combination of on-device AI-based processing and network connectivity enables local data analysis and transmission of only relevant information, greatly reducing storage needs. However, programming these devices for robust operation is challenging, requiring expertise in embedded systems and software engineering. Despite the increase in AI-based models for bioacoustics, their full potential remains unrealized without accessible tools to deploy them on custom hardware and tailor device behaviour to specific monitoring goals. 2. To address this challenge, we develop acoupi, an open-source Python framework that simplifies the creation and deployment of smart bioacoustic devices. acoupi integrates audio recording, AI-based data processing, data management, and real-time wireless messaging into a unified and configurable framework. By modularising key elements of the bioacoustic monitoring workflow, acoupi allows users to easily customise, extend, or select specific components to fit their unique monitoring needs. 3. We demonstrate the flexibility of acoupi by integrating two bioacoustic classifiers: BirdNET, for the classification of bird species, and BatDetect2, for the classification of UK bat species. We test the reliability of acoupi over a month-long deployment of two acoupi-powered devices in a UK urban park. 4. acoupi can be deployed on low-cost hardware such as the Raspberry Pi and can be customised for various applications. acoupi standardised framework and simplified tools facilitate the adoption of AI-powered PAM systems for researchers and conservationists. acoupi is on GitHub at https://github.com/acoupi/acoupi.
INQUIRE: A Natural World Text-to-Image Retrieval Benchmark
Nov 04, 2024We introduce INQUIRE, a text-to-image retrieval benchmark designed to challenge multimodal vision-language models on expert-level queries. INQUIRE includes iNaturalist 2024 (iNat24), a new dataset of five million natural world images, along with 250 expert-level retrieval queries. These queries are paired with all relevant images comprehensively labeled within iNat24, comprising 33,000 total matches. Queries span categories such as species identification, context, behavior, and appearance, emphasizing tasks that require nuanced image understanding and domain expertise. Our benchmark evaluates two core retrieval tasks: (1) INQUIRE-Fullrank, a full dataset ranking task, and (2) INQUIRE-Rerank, a reranking task for refining top-100 retrievals. Detailed evaluation of a range of recent multimodal models demonstrates that INQUIRE poses a significant challenge, with the best models failing to achieve an mAP@50 above 50%. In addition, we show that reranking with more powerful multimodal models can enhance retrieval performance, yet there remains a significant margin for improvement. By focusing on scientifically-motivated ecological challenges, INQUIRE aims to bridge the gap between AI capabilities and the needs of real-world scientific inquiry, encouraging the development of retrieval systems that can assist with accelerating ecological and biodiversity research. Our dataset and code are available at https://inquire-benchmark.github.io
Deep learning-based ecological analysis of camera trap images is impacted by training data quality and size
Aug 26, 2024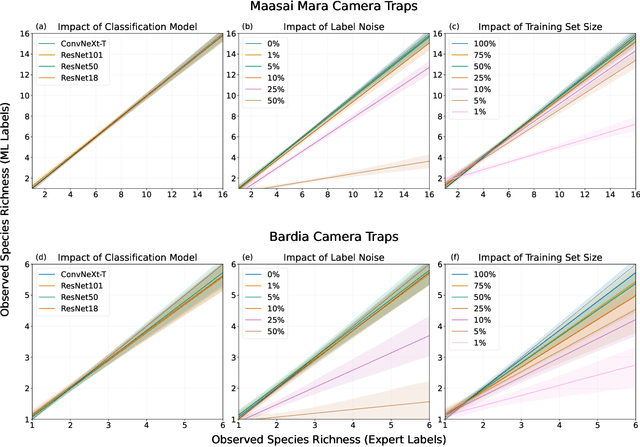
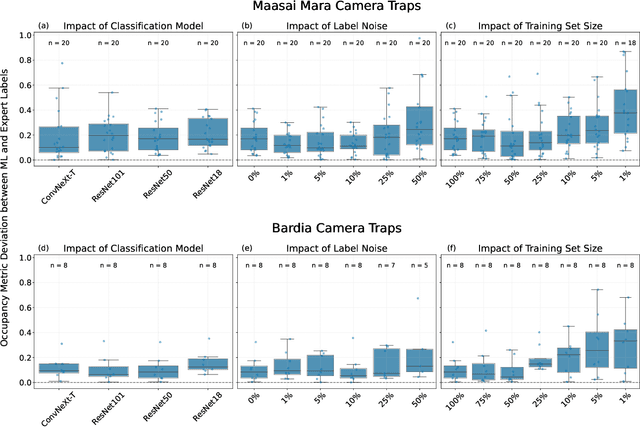
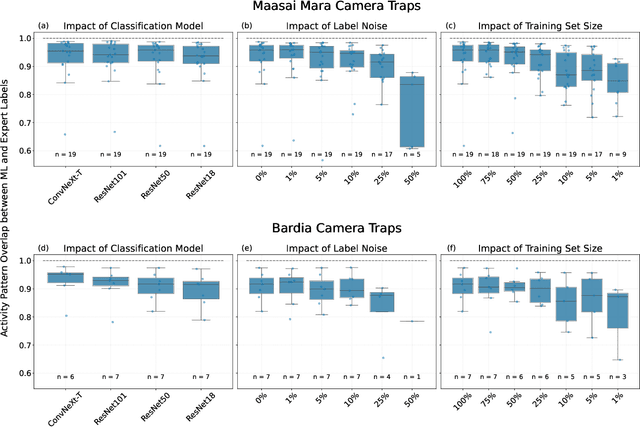
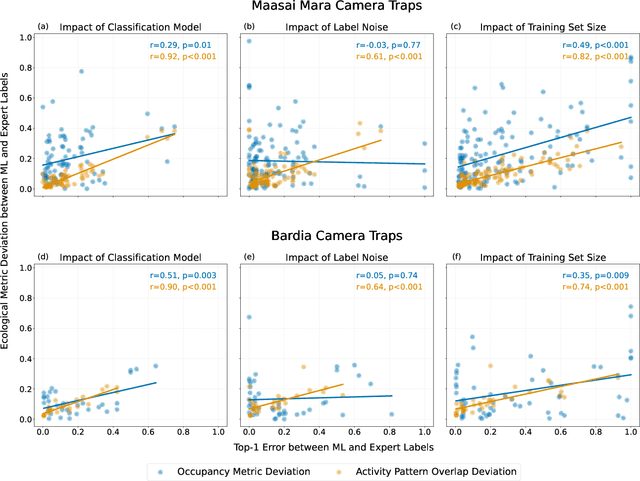
Large wildlife image collections from camera traps are crucial for biodiversity monitoring, offering insights into species richness, occupancy, and activity patterns. However, manual processing of these data is time-consuming, hindering analytical processes. To address this, deep neural networks have been widely adopted to automate image analysis. Despite their growing use, the impact of model training decisions on downstream ecological metrics remains unclear. Here, we analyse camera trap data from an African savannah and an Asian sub-tropical dry forest to compare key ecological metrics derived from expert-generated species identifications with those generated from deep neural networks. We assess the impact of model architecture, training data noise, and dataset size on ecological metrics, including species richness, occupancy, and activity patterns. Our results show that while model architecture has minimal impact, large amounts of noise and reduced dataset size significantly affect these metrics. Nonetheless, estimated ecological metrics are resilient to considerable noise, tolerating up to 10% error in species labels and a 50% reduction in training set size without changing significantly. We also highlight that conventional metrics like classification error may not always be representative of a model's ability to accurately measure ecological metrics. We conclude that ecological metrics derived from deep neural network predictions closely match those calculated from expert labels and remain robust to variations in the factors explored. However, training decisions for deep neural networks can impact downstream ecological analysis. Therefore, practitioners should prioritize creating large, clean training sets and evaluate deep neural network solutions based on their ability to measure the ecological metrics of interest.
Leveraging tropical reef, bird and unrelated sounds for superior transfer learning in marine bioacoustics
Apr 25, 2024



Machine learning has the potential to revolutionize passive acoustic monitoring (PAM) for ecological assessments. However, high annotation and compute costs limit the field's efficacy. Generalizable pretrained networks can overcome these costs, but high-quality pretraining requires vast annotated libraries, limiting its current applicability primarily to bird taxa. Here, we identify the optimum pretraining strategy for a data-deficient domain using coral reef bioacoustics. We assemble ReefSet, a large annotated library of reef sounds, though modest compared to bird libraries at 2% of the sample count. Through testing few-shot transfer learning performance, we observe that pretraining on bird audio provides notably superior generalizability compared to pretraining on ReefSet or unrelated audio alone. However, our key findings show that cross-domain mixing which leverages bird, reef and unrelated audio during pretraining maximizes reef generalizability. SurfPerch, our pretrained network, provides a strong foundation for automated analysis of marine PAM data with minimal annotation and compute costs.
Whombat: An open-source annotation tool for machine learning development in bioacoustics
Aug 24, 2023
1. Automated analysis of bioacoustic recordings using machine learning (ML) methods has the potential to greatly scale biodiversity monitoring efforts. The use of ML for high-stakes applications, such as conservation research, demands a data-centric approach with a focus on utilizing carefully annotated and curated evaluation and training data that is relevant and representative. Creating annotated datasets of sound recordings presents a number of challenges, such as managing large collections of recordings with associated metadata, developing flexible annotation tools that can accommodate the diverse range of vocalization profiles of different organisms, and addressing the scarcity of expert annotators. 2. We present Whombat a user-friendly, browser-based interface for managing audio recordings and annotation projects, with several visualization, exploration, and annotation tools. It enables users to quickly annotate, review, and share annotations, as well as visualize and evaluate a set of machine learning predictions on a dataset. The tool facilitates an iterative workflow where user annotations and machine learning predictions feedback to enhance model performance and annotation quality. 3. We demonstrate the flexibility of Whombat by showcasing two distinct use cases: an project aimed at enhancing automated UK bat call identification at the Bat Conservation Trust (BCT), and a collaborative effort among the USDA Forest Service and Oregon State University researchers exploring bioacoustic applications and extending automated avian classification models in the Pacific Northwest, USA. 4. Whombat is a flexible tool that can effectively address the challenges of annotation for bioacoustic research. It can be used for individual and collaborative work, hosted on a shared server or accessed remotely, or run on a personal computer without the need for coding skills.