 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-based ecological analysis of camera trap images is impacted by training data quality and size
Aug 26, 2024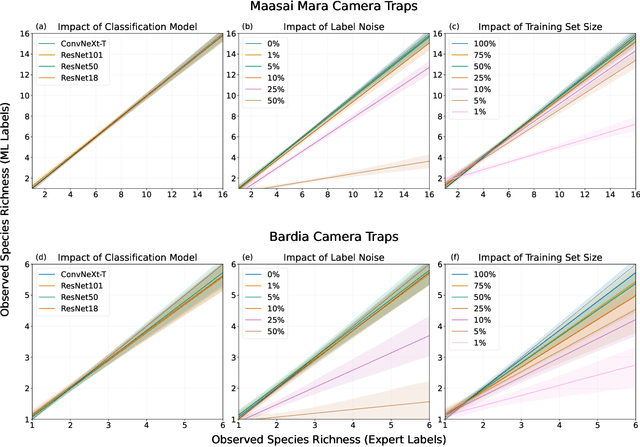
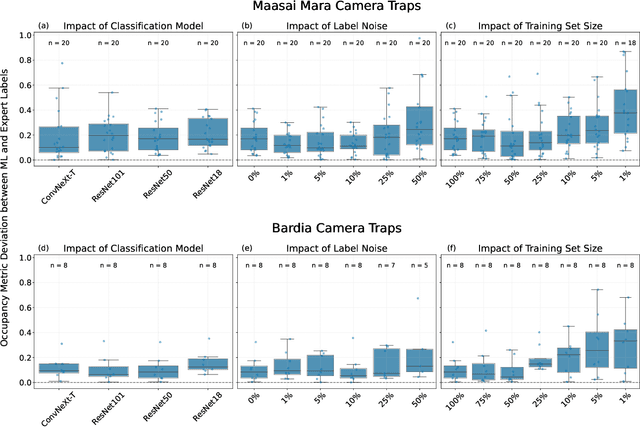
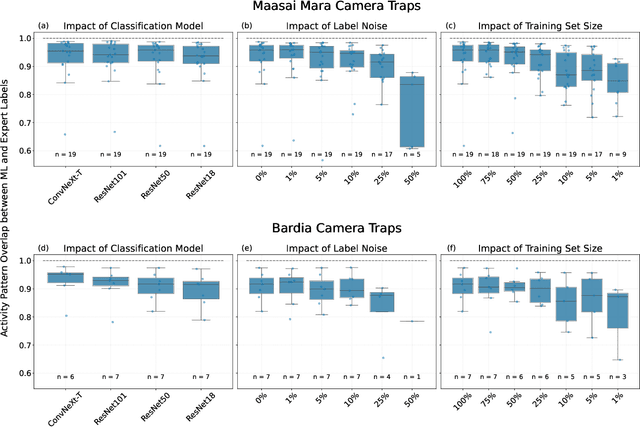
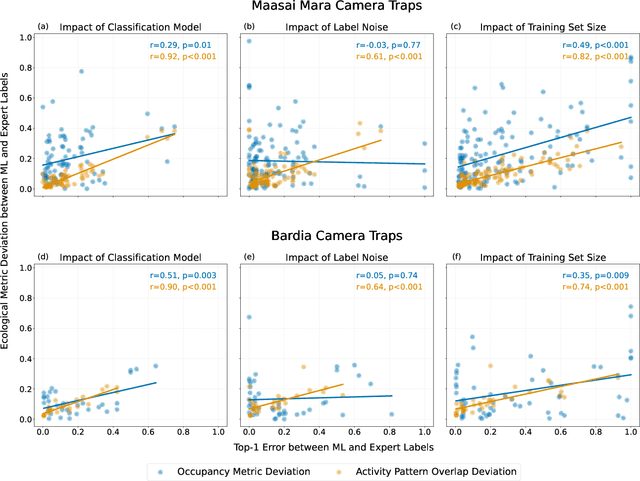
Large wildlife image collections from camera traps are crucial for biodiversity monitoring, offering insights into species richness, occupancy, and activity patterns. However, manual processing of these data is time-consuming, hindering analytical processes. To address this, deep neural networks have been widely adopted to automate image analysis. Despite their growing use, the impact of model training decisions on downstream ecological metrics remains unclear. Here, we analyse camera trap data from an African savannah and an Asian sub-tropical dry forest to compare key ecological metrics derived from expert-generated species identifications with those generated from deep neural networks. We assess the impact of model architecture, training data noise, and dataset size on ecological metrics, including species richness, occupancy, and activity patterns. Our results show that while model architecture has minimal impact, large amounts of noise and reduced dataset size significantly affect these metrics. Nonetheless, estimated ecological metrics are resilient to considerable noise, tolerating up to 10% error in species labels and a 50% reduction in training set size without changing significantly. We also highlight that conventional metrics like classification error may not always be representative of a model's ability to accurately measure ecological metrics. We conclude that ecological metrics derived from deep neural network predictions closely match those calculated from expert labels and remain robust to variations in the factors explored. However, training decisions for deep neural networks can impact downstream ecological analysis. Therefore, practitioners should prioritize creating large, clean training sets and evaluate deep neural network solutions based on their ability to measure the ecological metrics of interest.
Whombat: An open-source annotation tool for machine learning development in bioacoustics
Aug 24, 2023
1. Automated analysis of bioacoustic recordings using machine learning (ML) methods has the potential to greatly scale biodiversity monitoring efforts. The use of ML for high-stakes applications, such as conservation research, demands a data-centric approach with a focus on utilizing carefully annotated and curated evaluation and training data that is relevant and representative. Creating annotated datasets of sound recordings presents a number of challenges, such as managing large collections of recordings with associated metadata, developing flexible annotation tools that can accommodate the diverse range of vocalization profiles of different organisms, and addressing the scarcity of expert annotators. 2. We present Whombat a user-friendly, browser-based interface for managing audio recordings and annotation projects, with several visualization, exploration, and annotation tools. It enables users to quickly annotate, review, and share annotations, as well as visualize and evaluate a set of machine learning predictions on a dataset. The tool facilitates an iterative workflow where user annotations and machine learning predictions feedback to enhance model performance and annotation quality. 3. We demonstrate the flexibility of Whombat by showcasing two distinct use cases: an project aimed at enhancing automated UK bat call identification at the Bat Conservation Trust (BCT), and a collaborative effort among the USDA Forest Service and Oregon State University researchers exploring bioacoustic applications and extending automated avian classification models in the Pacific Northwest, USA. 4. Whombat is a flexible tool that can effectively address the challenges of annotation for bioacoustic research. It can be used for individual and collaborative work, hosted on a shared server or accessed remotely, or run on a personal computer without the need for coding skills.