 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplorer: Robust Collection of Interactable GUI Elements
Apr 12, 2025Automation of existing Graphical User Interfaces (GUIs) is important but hard to achieve. Upstream of making the GUI user-accessible or somehow scriptable, even the data-collection to understand the original interface poses significant challenges. For example, large quantities of general UI data seem helpful for training general machine learning (ML) models, but accessibility for each person can hinge on the ML's precision on a specific app. We therefore take the perspective that a given user needs confidence, that the relevant UI elements are being detected correctly throughout one app or digital environment. We mostly assume that the target application is known in advance, so that data collection and ML-training can be personalized for the test-time target domain. The proposed Explorer system focuses on detecting on-screen buttons and text-entry fields, i.e. interactables, where the training process has access to a live version of the application. The live application can run on almost any popular platform except iOS phones, and the collection is especially streamlined for Android phones or for desktop Chrome browsers. Explorer also enables the recording of interactive user sessions, and subsequent mapping of how such sessions overlap and sometimes loop back to similar states. We show how having such a map enables a kind of path planning through the GUI, letting a user issue audio commands to get to their destination. Critically, we are releasing our code for Explorer openly at https://github.com/varnelis/Explorer.
Group Robust Preference Optimization in Reward-free RLHF
May 30, 2024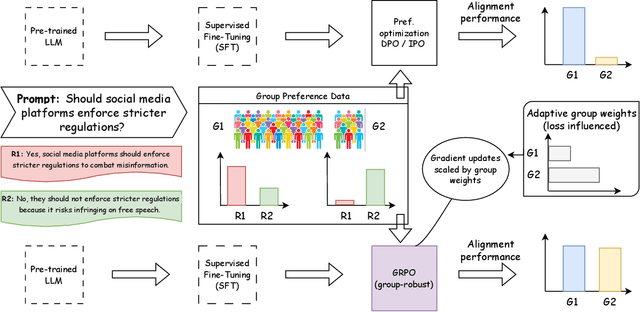
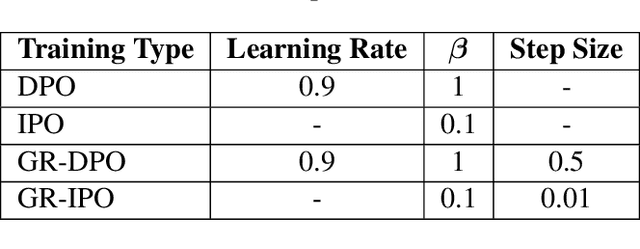
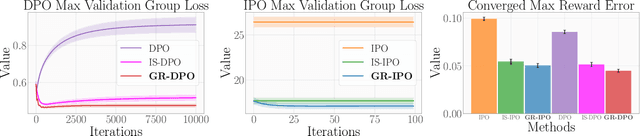

Adapting large language models (LLMs) for specific tasks usually involves fine-tuning through reinforcement learning with human feedback (RLHF) on preference data. While these data often come from diverse labelers' groups (e.g., different demographics, ethnicities, company teams, etc.), traditional RLHF approaches adopt a "one-size-fits-all" approach, i.e., they indiscriminately assume and optimize a single preference model, thus not being robust to unique characteristics and needs of the various groups. To address this limitation, we propose a novel Group Robust Preference Optimization (GRPO) method to align LLMs to individual groups' preferences robustly. Our approach builds upon reward-free direct preference optimization methods, but unlike previous approaches, it seeks a robust policy which maximizes the worst-case group performance. To achieve this, GRPO adaptively and sequentially weights the importance of different groups, prioritizing groups with worse cumulative loss. We theoretically study the feasibility of GRPO and analyze its convergence for the log-linear policy class. By fine-tuning LLMs with GRPO using diverse group-based global opinion data, we significantly improved performance for the worst-performing groups, reduced loss imbalances across groups, and improved probability accuracies compared to non-robust baselines.