 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-WikiRace: Benchmarking Long-term Planning and Reasoning over Real-World Knowledge Graphs
Feb 18, 2026We introduce LLM-Wikirace, a benchmark for evaluating planning, reasoning, and world knowledge in large language models (LLMs). In LLM-Wikirace, models must efficiently navigate Wikipedia hyperlinks step by step to reach a target page from a given source, requiring look-ahead planning and the ability to reason about how concepts are connected in the real world. We evaluate a broad set of open- and closed-source models, including Gemini-3, GPT-5, and Claude Opus 4.5, which achieve the strongest results on the easy level of the task and demonstrate superhuman performance. Despite this, performance drops sharply on hard difficulty: the best-performing model, Gemini-3, succeeds in only 23\% of hard games, highlighting substantial remaining challenges for frontier models. Our analysis shows that world knowledge is a necessary ingredient for success, but only up to a point, beyond this threshold, planning and long-horizon reasoning capabilities become the dominant factors. Trajectory-level analysis further reveals that even the strongest models struggle to replan after failure, frequently entering loops rather than recovering. LLM-Wikirace is a simple benchmark that reveals clear limitations in current reasoning systems, offering an open arena where planning-capable LLMs still have much to prove. Our code and leaderboard available at https:/llmwikirace.github.io.
Multi-Task GRPO: Reliable LLM Reasoning Across Tasks
Feb 05, 2026RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.
Robust Multi-Objective Controlled Decoding of Large Language Models
Mar 11, 2025
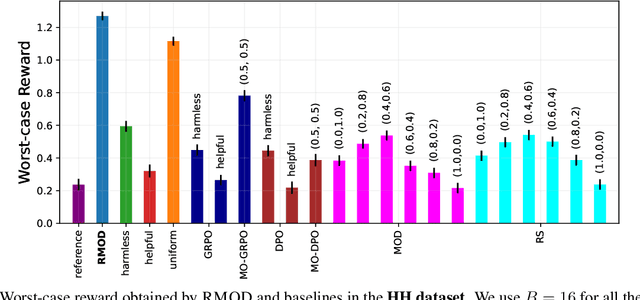
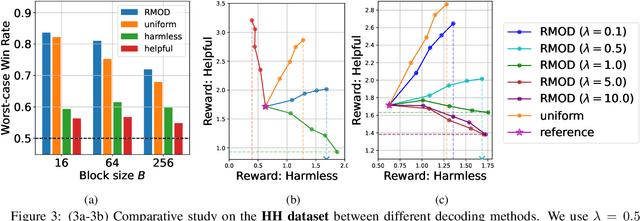
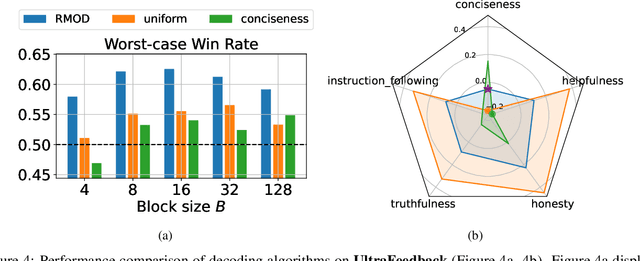
Test-time alignment of Large Language Models (LLMs) to human preferences offers a flexible way to generate responses aligned to diverse objectives without extensive retraining of LLMs. Existing methods achieve alignment to multiple objectives simultaneously (e.g., instruction-following, helpfulness, conciseness) by optimizing their corresponding reward functions. However, they often rely on predefined weights or optimize for averages, sacrificing one objective for another and leading to unbalanced outcomes. To address this, we introduce Robust Multi-Objective Decoding (RMOD), a novel inference-time algorithm that optimizes for improving worst-case rewards. RMOD formalizes the robust decoding problem as a maximin two-player game between reward weights and the sampling policy, solving for the Nash equilibrium. We show that the game reduces to a convex optimization problem to find the worst-case weights, while the best response policy can be computed analytically. We also introduce a practical RMOD variant designed for efficient decoding with contemporary LLMs, incurring minimal computational overhead compared to non-robust Multi-Objective Decoding (MOD) methods. Our experimental results showcase the effectiveness of RMOD in generating responses equitably aligned with diverse objectives, outperforming baselines up to 20%.
Almost Surely Safe Alignment of Large Language Models at Inference-Time
Feb 03, 2025Even highly capable large language models (LLMs) can produce biased or unsafe responses, and alignment techniques, such as RLHF, aimed at mitigating this issue, are expensive and prone to overfitting as they retrain the LLM. This paper introduces a novel inference-time alignment approach that ensures LLMs generate safe responses almost surely, i.e., with a probability approaching one. We achieve this by framing the safe generation of inference-time responses as a constrained Markov decision process within the LLM's latent space. Crucially, we augment a safety state that tracks the evolution of safety constraints and enables us to demonstrate formal safety guarantees upon solving the MDP in the latent space. Building on this foundation, we propose InferenceGuard, a practical implementation that safely aligns LLMs without modifying the model weights. Empirically, we demonstrate InferenceGuard effectively balances safety and task performance, outperforming existing inference-time alignment methods in generating safe and aligned responses.
Group Robust Preference Optimization in Reward-free RLHF
May 30, 2024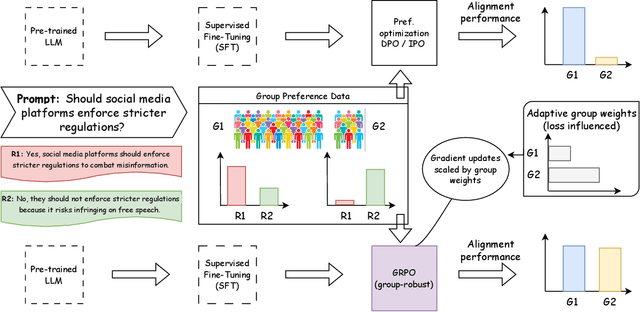
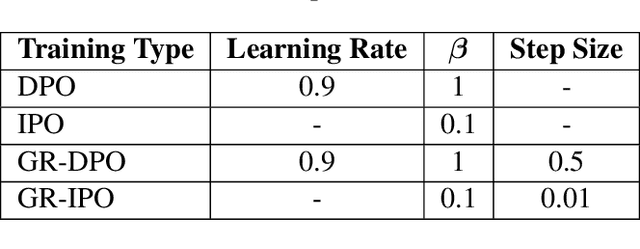
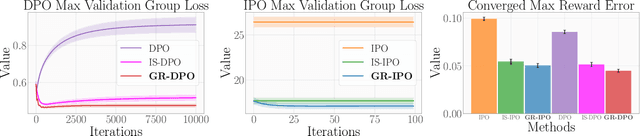

Adapting large language models (LLMs) for specific tasks usually involves fine-tuning through reinforcement learning with human feedback (RLHF) on preference data. While these data often come from diverse labelers' groups (e.g., different demographics, ethnicities, company teams, etc.), traditional RLHF approaches adopt a "one-size-fits-all" approach, i.e., they indiscriminately assume and optimize a single preference model, thus not being robust to unique characteristics and needs of the various groups. To address this limitation, we propose a novel Group Robust Preference Optimization (GRPO) method to align LLMs to individual groups' preferences robustly. Our approach builds upon reward-free direct preference optimization methods, but unlike previous approaches, it seeks a robust policy which maximizes the worst-case group performance. To achieve this, GRPO adaptively and sequentially weights the importance of different groups, prioritizing groups with worse cumulative loss. We theoretically study the feasibility of GRPO and analyze its convergence for the log-linear policy class. By fine-tuning LLMs with GRPO using diverse group-based global opinion data, we significantly improved performance for the worst-performing groups, reduced loss imbalances across groups, and improved probability accuracies compared to non-robust baselines.
Distributionally Robust Model-based Reinforcement Learning with Large State Spaces
Sep 05, 2023Three major challenges in reinforcement learning are the complex dynamical systems with large state spaces, the costly data acquisition processes, and the deviation of real-world dynamics from the training environment deployment. To overcome these issues, we study distributionally robust Markov decision processes with continuous state spaces under the widely used Kullback-Leibler, chi-square, and total variation uncertainty sets. We propose a model-based approach that utilizes Gaussian Processes and the maximum variance reduction algorithm to efficiently learn multi-output nominal transition dynamics, leveraging access to a generative model (i.e., simulator). We further demonstrate the statistical sample complexity of the proposed method for different uncertainty sets. These complexity bounds are independent of the number of states and extend beyond linear dynamics, ensuring the effectiveness of our approach in identifying near-optimal distributionally-robust policies. The proposed method can be further combined with other model-free distributionally robust reinforcement learning methods to obtain a near-optimal robust policy. Experimental results demonstrate the robustness of our algorithm to distributional shifts and its superior performance in terms of the number of samples needed.
Movement Penalized Bayesian Optimization with Application to Wind Energy Systems
Oct 14, 2022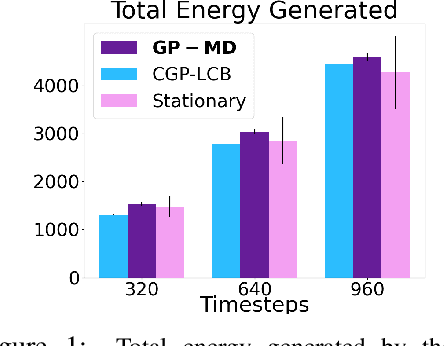
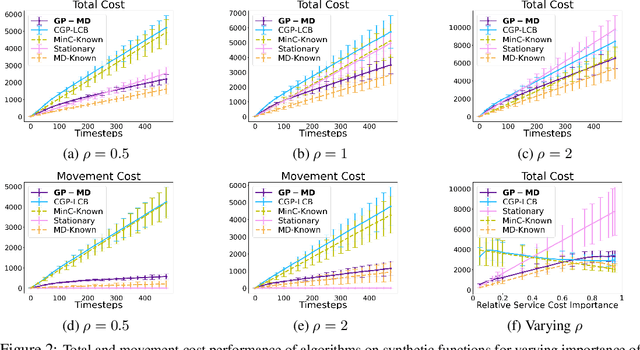
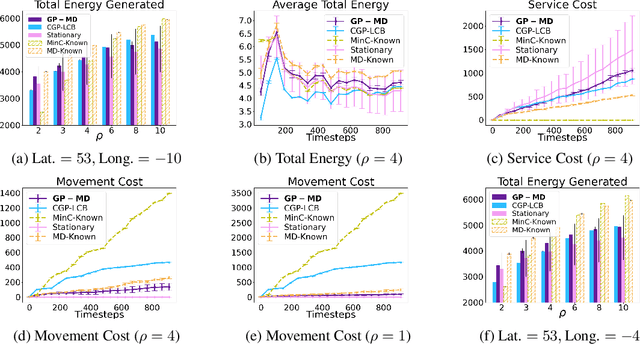
Contextual Bayesian optimization (CBO) is a powerful framework for sequential decision-making given side information, with important applications, e.g., in wind energy systems. In this setting, the learner receives context (e.g., weather conditions) at each round, and has to choose an action (e.g., turbine parameters). Standard algorithms assume no cost for switching their decisions at every round. However, in many practical applications, there is a cost associated with such changes, which should be minimized. We introduce the episodic CBO with movement costs problem and, based on the online learning approach for metrical task systems of Coester and Lee (2019), propose a novel randomized mirror descent algorithm that makes use of Gaussian Process confidence bounds. We compare its performance with the offline optimal sequence for each episode and provide rigorous regret guarantees. We further demonstrate our approach on the important real-world application of altitude optimization for Airborne Wind Energy Systems. In the presence of substantial movement costs, our algorithm consistently outperforms standard CBO algorithms.