 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task GRPO: Reliable LLM Reasoning Across Tasks
Feb 05, 2026RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.
Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening
Jan 29, 2026Reinforcement learning (RL) post-training is a dominant approach for improving the reasoning performance of large language models (LLMs), yet growing evidence suggests that its gains arise primarily from distribution sharpening rather than the acquisition of new capabilities. Recent work has shown that sampling from the power distribution of LLMs using Markov chain Monte Carlo (MCMC) can recover performance comparable to RL post-training without relying on external rewards; however, the high computational cost of MCMC makes such approaches impractical for widespread adoption. In this work, we propose a theoretically grounded alternative that eliminates the need for iterative MCMC. We derive a novel formulation showing that the global power distribution can be approximated by a token-level scaled low-temperature one, where the scaling factor captures future trajectory quality. Leveraging this insight, we introduce a training-free and verifier-free algorithm that sharpens the base model's generative distribution autoregressively. Empirically, we evaluate our method on math, QA, and code tasks across four LLMs, and show that our method matches or surpasses one-shot GRPO without relying on any external rewards, while reducing inference latency by over 10x compared to MCMC-based sampling.
KFS-Bench: Comprehensive Evaluation of Key Frame Sampling in Long Video Understanding
Dec 16, 2025We propose KFS-Bench, the first benchmark for key frame sampling in long video question answering (QA), featuring multi-scene annotations to enable direct and robust evaluation of sampling strategies. Key frame sampling is crucial for efficient long-form video understanding. In long video QA, selecting informative frames enables multimodal large language models (MLLMs) to improve both accuracy and efficiency. KFS-Bench addresses the limitation of prior works that only indirectly assess frame selection quality via QA accuracy. By providing ground-truth annotations of multiple disjoint scenes required per question, KFS-Bench allows us to directly analyze how different sampling approaches capture essential content across an entire long video. Using KFS-Bench, we conduct a comprehensive study of key frame sampling methods and identify that not only sampling precision but also scene coverage and sampling balance are the key factors influencing QA performance. Regarding all the factors, we design a novel sampling quality metric that correlates with QA accuracy. Furthermore, we develop a novel key frame sampling method that leverages question-video relevance to balance sampling diversity against question-frame similarity, thereby improving coverage of relevant scenes. Our adaptively balanced sampling approach achieves superior performance in both key frame sampling and QA performance. The benchmark is available at https://github.com/NEC-VID/KFS-Bench.
Enhancing Reliability of Medical Image Diagnosis through Top-rank Learning with Rejection Module
Aug 11, 2025In medical image processing, accurate diagnosis is of paramount importance. Leveraging machine learning techniques, particularly top-rank learning, shows significant promise by focusing on the most crucial instances. However, challenges arise from noisy labels and class-ambiguous instances, which can severely hinder the top-rank objective, as they may be erroneously placed among the top-ranked instances. To address these, we propose a novel approach that enhances toprank learning by integrating a rejection module. Cooptimized with the top-rank loss, this module identifies and mitigates the impact of outliers that hinder training effectiveness. The rejection module functions as an additional branch, assessing instances based on a rejection function that measures their deviation from the norm. Through experimental validation on a medical dataset, our methodology demonstrates its efficacy in detecting and mitigating outliers, improving the reliability and accuracy of medical image diagnoses.
Bourbaki: Self-Generated and Goal-Conditioned MDPs for Theorem Proving
Jul 03, 2025Reasoning remains a challenging task for large language models (LLMs), especially within the logically constrained environment of automated theorem proving (ATP), due to sparse rewards and the vast scale of proofs. These challenges are amplified in benchmarks like PutnamBench, which contains university-level problems requiring complex, multi-step reasoning. To address this, we introduce self-generated goal-conditioned MDPs (sG-MDPs), a new framework in which agents generate and pursue their subgoals based on the evolving proof state. Given this more structured generation of goals, the resulting problem becomes more amenable to search. We then apply Monte Carlo Tree Search (MCTS)-like algorithms to solve the sG-MDP, instantiating our approach in Bourbaki (7B), a modular system that can ensemble multiple 7B LLMs for subgoal generation and tactic synthesis. On PutnamBench, Bourbaki (7B) solves 26 problems, achieving new state-of-the-art results with models at this scale.
Robust Probabilistic Model Checking with Continuous Reward Domains
Feb 06, 2025Probabilistic model checking traditionally verifies properties on the expected value of a measure of interest. This restriction may fail to capture the quality of service of a significant proportion of a system's runs, especially when the probability distribution of the measure of interest is poorly represented by its expected value due to heavy-tail behaviors or multiple modalities. Recent works inspired by distributional reinforcement learning use discrete histograms to approximate integer reward distribution, but they struggle with continuous reward space and present challenges in balancing accuracy and scalability. We propose a novel method for handling both continuous and discrete reward distributions in Discrete Time Markov Chains using moment matching with Erlang mixtures. By analytically deriving higher-order moments through Moment Generating Functions, our method approximates the reward distribution with theoretically bounded error while preserving the statistical properties of the true distribution. This detailed distributional insight enables the formulation and robust model checking of quality properties based on the entire reward distribution function, rather than restricting to its expected value. We include a theoretical foundation ensuring bounded approximation errors, along with an experimental evaluation demonstrating our method's accuracy and scalability in practical model-checking problems.
Almost Surely Safe Alignment of Large Language Models at Inference-Time
Feb 03, 2025Even highly capable large language models (LLMs) can produce biased or unsafe responses, and alignment techniques, such as RLHF, aimed at mitigating this issue, are expensive and prone to overfitting as they retrain the LLM. This paper introduces a novel inference-time alignment approach that ensures LLMs generate safe responses almost surely, i.e., with a probability approaching one. We achieve this by framing the safe generation of inference-time responses as a constrained Markov decision process within the LLM's latent space. Crucially, we augment a safety state that tracks the evolution of safety constraints and enables us to demonstrate formal safety guarantees upon solving the MDP in the latent space. Building on this foundation, we propose InferenceGuard, a practical implementation that safely aligns LLMs without modifying the model weights. Empirically, we demonstrate InferenceGuard effectively balances safety and task performance, outperforming existing inference-time alignment methods in generating safe and aligned responses.
Probabilistic Counterexample Guidance for Safer Reinforcement Learning (Extended Version)
Jul 12, 2023Safe exploration aims at addressing the limitations of Reinforcement Learning (RL) in safety-critical scenarios, where failures during trial-and-error learning may incur high costs. Several methods exist to incorporate external knowledge or to use proximal sensor data to limit the exploration of unsafe states. However, reducing exploration risks in unknown environments, where an agent must discover safety threats during exploration, remains challenging. In this paper, we target the problem of safe exploration by guiding the training with counterexamples of the safety requirement. Our method abstracts both continuous and discrete state-space systems into compact abstract models representing the safety-relevant knowledge acquired by the agent during exploration. We then exploit probabilistic counterexample generation to construct minimal simulation submodels eliciting safety requirement violations, where the agent can efficiently train offline to refine its policy towards minimising the risk of safety violations during the subsequent online exploration. We demonstrate our method's effectiveness in reducing safety violations during online exploration in preliminary experiments by an average of 40.3% compared with QL and DQN standard algorithms and 29.1% compared with previous related work, while achieving comparable cumulative rewards with respect to unrestricted exploration and alternative approaches.
Revealing Reliable Signatures by Learning Top-Rank Pairs
Mar 17, 2022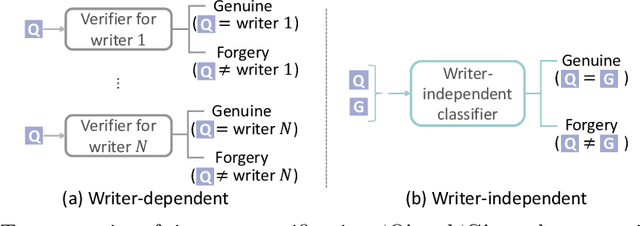
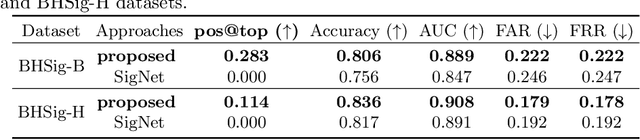
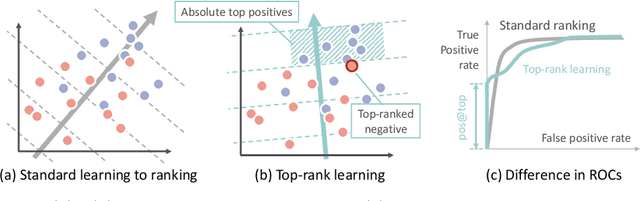
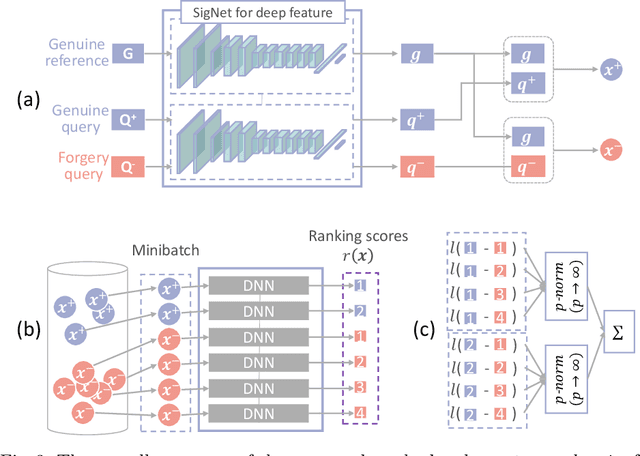
Signature verification, as a crucial practical documentation analysis task, has been continuously studied by researchers in machine learning and pattern recognition fields. In specific scenarios like confirming financial documents and legal instruments, ensuring the absolute reliability of signatures is of top priority. In this work, we proposed a new method to learn "top-rank pairs" for writer-independent offline signature verification tasks. By this scheme, it is possible to maximize the number of absolutely reliable signatures. More precisely, our method to learn top-rank pairs aims at pushing positive samples beyond negative samples, after pairing each of them with a genuine reference signature. In the experiment, BHSig-B and BHSig-H datasets are used for evaluation, on which the proposed model achieves overwhelming better pos@top (the ratio of absolute top positive samples to all of the positive samples) while showing encouraging performance on both Area Under the Curve (AUC) and accuracy.
Optimal Rejection Function Meets Character Recognition Tasks
Mar 17, 2022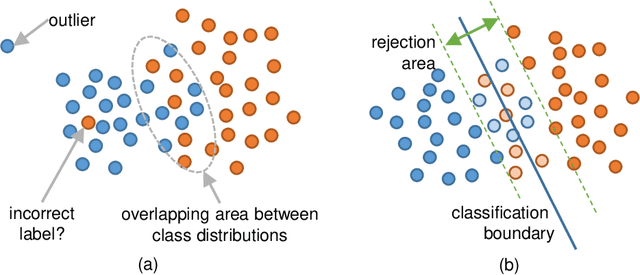
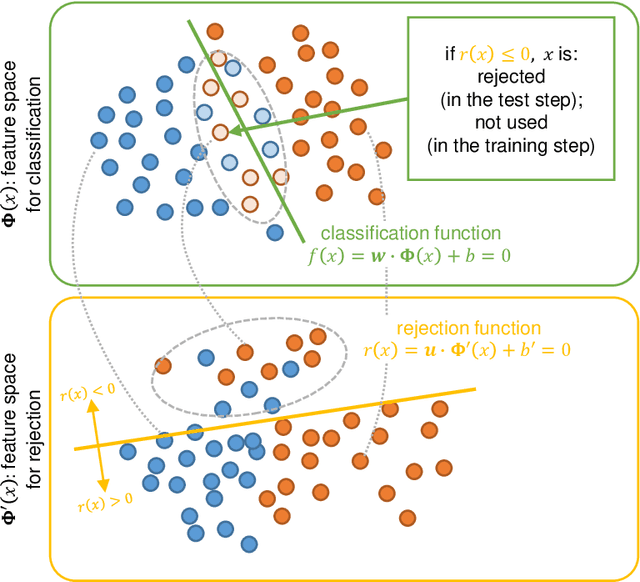


In this paper, we propose an optimal rejection method for rejecting ambiguous samples by a rejection function. This rejection function is trained together with a classification function under the framework of Learning-with-Rejection (LwR). The highlights of LwR are: (1) the rejection strategy is not heuristic but has a strong background from a machine learning theory, and (2) the rejection function can be trained on an arbitrary feature space which is different from the feature space for classification. The latter suggests we can choose a feature space that is more suitable for rejection. Although the past research on LwR focused only on its theoretical aspect, we propose to utilize LwR for practical pattern classification tasks. Moreover, we propose to use features from different CNN layers for classification and rejection. Our extensive experiments of notMNIST classification and character/non-character classification demonstrate that the proposed method achieves better performance than traditional rejection strategies.