 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Probabilistic Model Checking with Continuous Reward Domains
Feb 06, 2025Probabilistic model checking traditionally verifies properties on the expected value of a measure of interest. This restriction may fail to capture the quality of service of a significant proportion of a system's runs, especially when the probability distribution of the measure of interest is poorly represented by its expected value due to heavy-tail behaviors or multiple modalities. Recent works inspired by distributional reinforcement learning use discrete histograms to approximate integer reward distribution, but they struggle with continuous reward space and present challenges in balancing accuracy and scalability. We propose a novel method for handling both continuous and discrete reward distributions in Discrete Time Markov Chains using moment matching with Erlang mixtures. By analytically deriving higher-order moments through Moment Generating Functions, our method approximates the reward distribution with theoretically bounded error while preserving the statistical properties of the true distribution. This detailed distributional insight enables the formulation and robust model checking of quality properties based on the entire reward distribution function, rather than restricting to its expected value. We include a theoretical foundation ensuring bounded approximation errors, along with an experimental evaluation demonstrating our method's accuracy and scalability in practical model-checking problems.
Probabilistic Counterexample Guidance for Safer Reinforcement Learning (Extended Version)
Jul 12, 2023Safe exploration aims at addressing the limitations of Reinforcement Learning (RL) in safety-critical scenarios, where failures during trial-and-error learning may incur high costs. Several methods exist to incorporate external knowledge or to use proximal sensor data to limit the exploration of unsafe states. However, reducing exploration risks in unknown environments, where an agent must discover safety threats during exploration, remains challenging. In this paper, we target the problem of safe exploration by guiding the training with counterexamples of the safety requirement. Our method abstracts both continuous and discrete state-space systems into compact abstract models representing the safety-relevant knowledge acquired by the agent during exploration. We then exploit probabilistic counterexample generation to construct minimal simulation submodels eliciting safety requirement violations, where the agent can efficiently train offline to refine its policy towards minimising the risk of safety violations during the subsequent online exploration. We demonstrate our method's effectiveness in reducing safety violations during online exploration in preliminary experiments by an average of 40.3% compared with QL and DQN standard algorithms and 29.1% compared with previous related work, while achieving comparable cumulative rewards with respect to unrestricted exploration and alternative approaches.
SYMPAIS: SYMbolic Parallel Adaptive Importance Sampling for Probabilistic Program Analysis
Oct 10, 2020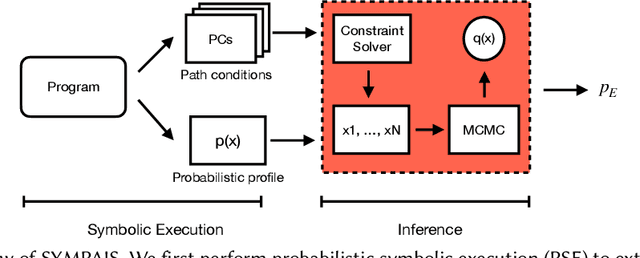
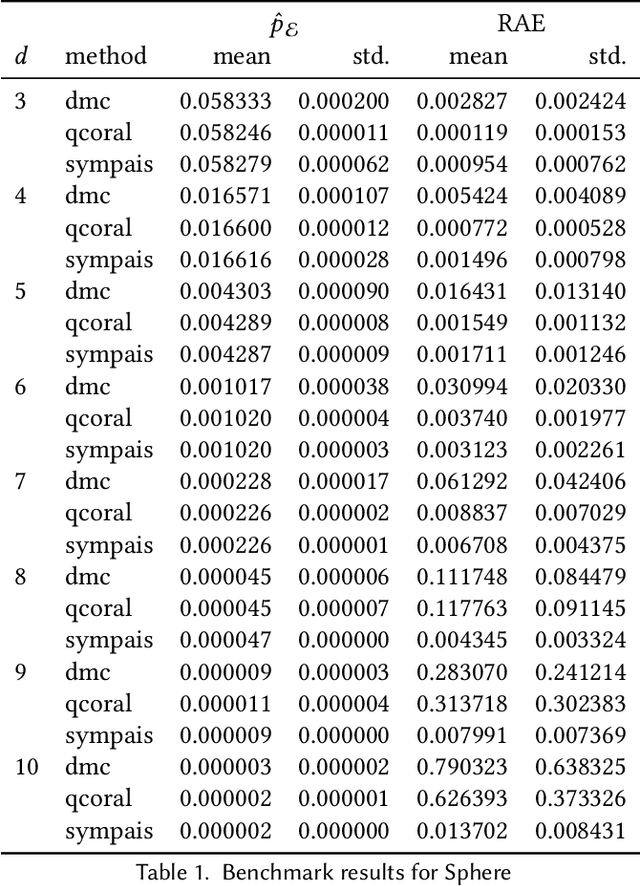
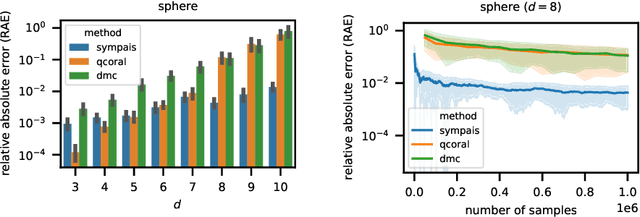
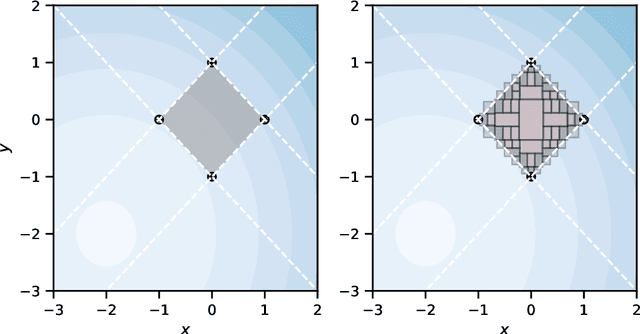
Probabilistic software analysis aims at quantifying the probability of a target event occurring during the execution of a program processing uncertain incoming data or written itself using probabilistic programming constructs. Recent techniques combine classic static analysis methods with inference procedure to obtain accurate quantification of the probability of rare target events, such as failures in a mission-critical system. However, current techniques face several scalability and applicability limitations when analyzing software processing with high-dimensional multivariate distributions. In this paper, we present SYMbolic Parallel Adaptive Importance Sampling (SYMPAIS), a new algorithm that combines symbolic execution with adaptive importance sampling to analyze probabilistic programs. Our method provides a general solution that scales to systems with high-dimensional inputs and demonstrates superior performance in quantifying rare events compared to prior work. Preliminary experimental results support the potential efficacy of our solution.