 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Intermediate Layers Know: Detecting Jailbreaks from Entropy Dynamics
Jun 23, 2026Jailbreak attacks reveal a persistent weakness in aligned Large Language Models: carefully crafted prompts can elicit policy-violating responses despite safety training. While most defenses operate at the prompt or output level, it remains unclear how harmful intent is encoded within the model's internal representations. We investigate this question by analyzing token-level predictive entropy trajectories across layers of a frozen LLM using the logit lens. We find that static aggregate statistics of prompt-level entropy (e.g., mean, variance) carry little discriminative signal, whereas features capturing how entropy evolves across token positions, such as monotonic rank-based trend scores, are substantially more informative. Importantly, this signal is not uniform across model depth: it is concentrated in intermediate layers and degrades at the final layer, indicating that jailbreak-relevant structure is most pronounced in mid-network representations rather than at the output head. Across multiple models (Llama, Qwen, Gemma) and adversarial benchmarks, these entropy dynamics provide architecture-consistent separation without additional training. Together, our findings show that jailbreak behavior is reflected in structured intermediate uncertainty dynamics, clarifying both which entropy-derived features encode harmful intent and where in the network that signal is most pronounced.
Structured Credal Learning
Mar 14, 2026Real-world learning tasks often encounter uncertainty due to covariate shift and noisy or inconsistent labels. However, existing robust learning methods merge these effects into a single distributional uncertainty set. In this work, we introduce a novel structured credal learning framework that explicitly separates these two sources. Specifically, we derive geometric bounds on the total variation diameter of structured credal sets and demonstrate how this quantity decomposes into contributions from covariate shift and expected label disagreement. This decomposition reveals a gating effect: covariate modulates how much label disagreement contributes to the joint uncertainty, such that seemingly benign covariate shifts can substantially increase the effective uncertainty. We also establish finite-sample concentration bounds in a fixed covariate regime and demonstrate that this quantity can be efficiently estimated. Lastly, we show that robust optimization over these structured credal sets reduces to a tractable discrete min-max problem, avoiding ad-hoc robustness parameters. Overall, our approach provides a principled and practical foundation for robust learning under combined covariate and label mechanism ambiguity.
crossMoDA Challenge: Evolution of Cross-Modality Domain Adaptation Techniques for Vestibular Schwannoma and Cochlea Segmentation from 2021 to 2023
Jun 13, 2025The cross-Modality Domain Adaptation (crossMoDA) challenge series, initiated in 2021 in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), focuses on unsupervised cross-modality segmentation, learning from contrast-enhanced T1 (ceT1) and transferring to T2 MRI. The task is an extreme example of domain shift chosen to serve as a meaningful and illustrative benchmark. From a clinical application perspective, it aims to automate Vestibular Schwannoma (VS) and cochlea segmentation on T2 scans for more cost-effective VS management. Over time, the challenge objectives have evolved to enhance its clinical relevance. The challenge evolved from using single-institutional data and basic segmentation in 2021 to incorporating multi-institutional data and Koos grading in 2022, and by 2023, it included heterogeneous routine data and sub-segmentation of intra- and extra-meatal tumour components. In this work, we report the findings of the 2022 and 2023 editions and perform a retrospective analysis of the challenge progression over the years. The observations from the successive challenge contributions indicate that the number of outliers decreases with an expanding dataset. This is notable since the diversity of scanning protocols of the datasets concurrently increased. The winning approach of the 2023 edition reduced the number of outliers on the 2021 and 2022 testing data, demonstrating how increased data heterogeneity can enhance segmentation performance even on homogeneous data. However, the cochlea Dice score declined in 2023, likely due to the added complexity from tumour sub-annotations affecting overall segmentation performance. While progress is still needed for clinically acceptable VS segmentation, the plateauing performance suggests that a more challenging cross-modal task may better serve future benchmarking.
Calibrating LLMs with Information-Theoretic Evidential Deep Learning
Feb 10, 2025Fine-tuned large language models (LLMs) often exhibit overconfidence, particularly when trained on small datasets, resulting in poor calibration and inaccurate uncertainty estimates. Evidential Deep Learning (EDL), an uncertainty-aware approach, enables uncertainty estimation in a single forward pass, making it a promising method for calibrating fine-tuned LLMs. However, despite its computational efficiency, EDL is prone to overfitting, as its training objective can result in overly concentrated probability distributions. To mitigate this, we propose regularizing EDL by incorporating an information bottleneck (IB). Our approach IB-EDL suppresses spurious information in the evidence generated by the model and encourages truly predictive information to influence both the predictions and uncertainty estimates. Extensive experiments across various fine-tuned LLMs and tasks demonstrate that IB-EDL outperforms both existing EDL and non-EDL approaches. By improving the trustworthiness of LLMs, IB-EDL facilitates their broader adoption in domains requiring high levels of confidence calibration. Code is available at https://github.com/sandylaker/ib-edl.
FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models
May 28, 2024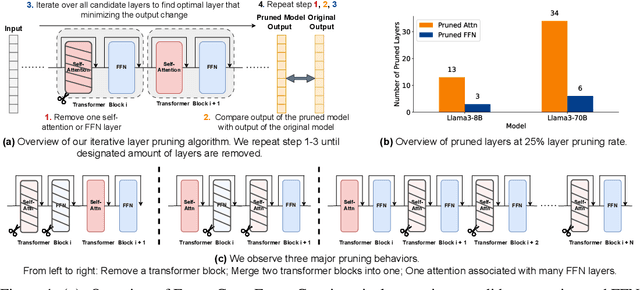
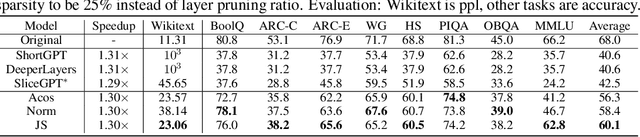
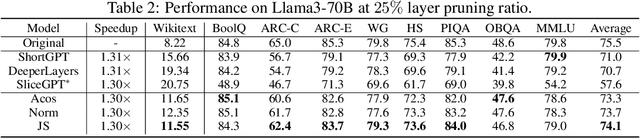
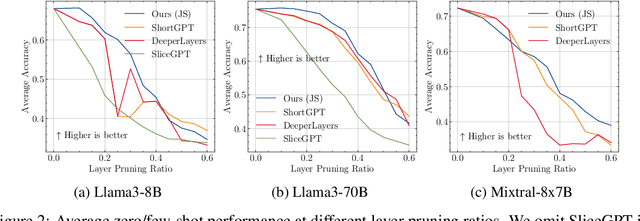
Overparametrized transformer networks are the state-of-the-art architecture for Large Language Models (LLMs). However, such models contain billions of parameters making large compute a necessity, while raising environmental concerns. To address these issues, we propose FinerCut, a new form of fine-grained layer pruning, which in contrast to prior work at the transformer block level, considers all self-attention and feed-forward network (FFN) layers within blocks as individual pruning candidates. FinerCut prunes layers whose removal causes minimal alternation to the model's output -- contributing to a new, lean, interpretable, and task-agnostic pruning method. Tested across 9 benchmarks, our approach retains 90% performance of Llama3-8B with 25% layers removed, and 95% performance of Llama3-70B with 30% layers removed, all without fine-tuning or post-pruning reconstruction. Strikingly, we observe intriguing results with FinerCut: 42% (34 out of 80) of the self-attention layers in Llama3-70B can be removed while preserving 99% of its performance -- without additional fine-tuning after removal. Moreover, FinerCut provides a tool to inspect the types and locations of pruned layers, allowing to observe interesting pruning behaviors. For instance, we observe a preference for pruning self-attention layers, often at deeper consecutive decoder layers. We hope our insights inspire future efficient LLM architecture designs.
Stochastic Vision Transformers with Wasserstein Distance-Aware Attention
Nov 30, 2023



Self-supervised learning is one of the most promising approaches to acquiring knowledge from limited labeled data. Despite the substantial advancements made in recent years, self-supervised models have posed a challenge to practitioners, as they do not readily provide insight into the model's confidence and uncertainty. Tackling this issue is no simple feat, primarily due to the complexity involved in implementing techniques that can make use of the latent representations learned during pre-training without relying on explicit labels. Motivated by this, we introduce a new stochastic vision transformer that integrates uncertainty and distance awareness into self-supervised learning (SSL) pipelines. Instead of the conventional deterministic vector embedding, our novel stochastic vision transformer encodes image patches into elliptical Gaussian distributional embeddings. Notably, the attention matrices of these stochastic representational embeddings are computed using Wasserstein distance-based attention, effectively capitalizing on the distributional nature of these embeddings. Additionally, we propose a regularization term based on Wasserstein distance for both pre-training and fine-tuning processes, thereby incorporating distance awareness into latent representations. We perform extensive experiments across different tasks such as in-distribution generalization, out-of-distribution detection, dataset corruption, semi-supervised settings, and transfer learning to other datasets and tasks. Our proposed method achieves superior accuracy and calibration, surpassing the self-supervised baseline in a wide range of experiments on a variety of datasets.
AttributionLab: Faithfulness of Feature Attribution Under Controllable Environments
Oct 10, 2023



Feature attribution explains neural network outputs by identifying relevant input features. How do we know if the identified features are indeed relevant to the network? This notion is referred to as faithfulness, an essential property that reflects the alignment between the identified (attributed) features and the features used by the model. One recent trend to test faithfulness is to design the data such that we know which input features are relevant to the label and then train a model on the designed data. Subsequently, the identified features are evaluated by comparing them with these designed ground truth features. However, this idea has the underlying assumption that the neural network learns to use all and only these designed features, while there is no guarantee that the learning process trains the network in this way. In this paper, we solve this missing link by explicitly designing the neural network by manually setting its weights, along with designing data, so we know precisely which input features in the dataset are relevant to the designed network. Thus, we can test faithfulness in AttributionLab, our designed synthetic environment, which serves as a sanity check and is effective in filtering out attribution methods. If an attribution method is not faithful in a simple controlled environment, it can be unreliable in more complex scenarios. Furthermore, the AttributionLab environment serves as a laboratory for controlled experiments through which we can study feature attribution methods, identify issues, and suggest potential improvements.
Probabilistic Self-supervised Learning via Scoring Rules Minimization
Sep 05, 2023In this paper, we propose a novel probabilistic self-supervised learning via Scoring Rule Minimization (ProSMIN), which leverages the power of probabilistic models to enhance representation quality and mitigate collapsing representations. Our proposed approach involves two neural networks; the online network and the target network, which collaborate and learn the diverse distribution of representations from each other through knowledge distillation. By presenting the input samples in two augmented formats, the online network is trained to predict the target network representation of the same sample under a different augmented view. The two networks are trained via our new loss function based on proper scoring rules. We provide a theoretical justification for ProSMIN's convergence, demonstrating the strict propriety of its modified scoring rule. This insight validates the method's optimization process and contributes to its robustness and effectiveness in improving representation quality. We evaluate our probabilistic model on various downstream tasks, such as in-distribution generalization, out-of-distribution detection, dataset corruption, low-shot learning, and transfer learning. Our method achieves superior accuracy and calibration, surpassing the self-supervised baseline in a wide range of experiments on large-scale datasets like ImageNet-O and ImageNet-C, ProSMIN demonstrates its scalability and real-world applicability.
Diversified Ensemble of Independent Sub-Networks for Robust Self-Supervised Representation Learning
Sep 01, 2023Ensembling a neural network is a widely recognized approach to enhance model performance, estimate uncertainty, and improve robustness in deep supervised learning. However, deep ensembles often come with high computational costs and memory demands. In addition, the efficiency of a deep ensemble is related to diversity among the ensemble members which is challenging for large, over-parameterized deep neural networks. Moreover, ensemble learning has not yet seen such widespread adoption, and it remains a challenging endeavor for self-supervised or unsupervised representation learning. Motivated by these challenges, we present a novel self-supervised training regime that leverages an ensemble of independent sub-networks, complemented by a new loss function designed to encourage diversity. Our method efficiently builds a sub-model ensemble with high diversity, leading to well-calibrated estimates of model uncertainty, all achieved with minimal computational overhead compared to traditional deep self-supervised ensembles. To evaluate the effectiveness of our approach, we conducted extensive experiments across various tasks, including in-distribution generalization, out-of-distribution detection, dataset corruption, and semi-supervised settings. The results demonstrate that our method significantly improves prediction reliability. Our approach not only achieves excellent accuracy but also enhances calibration, surpassing baseline performance across a wide range of self-supervised architectures in computer vision, natural language processing, and genomics data.
A Dual-Perspective Approach to Evaluating Feature Attribution Methods
Aug 17, 2023

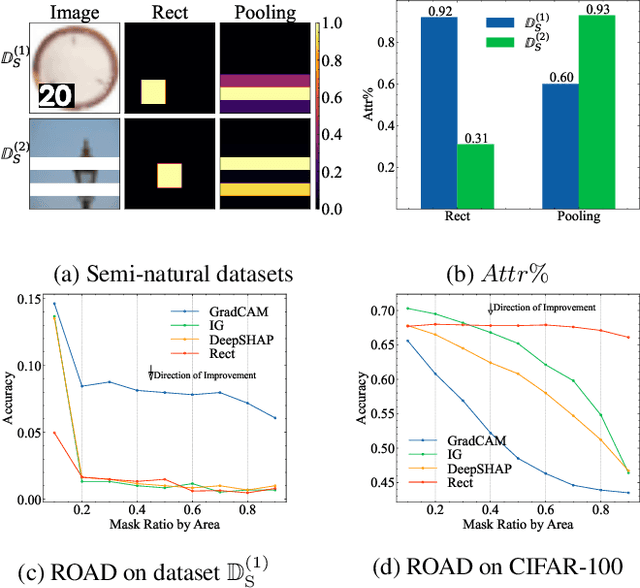

Feature attribution methods attempt to explain neural network predictions by identifying relevant features. However, establishing a cohesive framework for assessing feature attribution remains a challenge. There are several views through which we can evaluate attributions. One principal lens is to observe the effect of perturbing attributed features on the model's behavior (i.e., faithfulness). While providing useful insights, existing faithfulness evaluations suffer from shortcomings that we reveal in this paper. In this work, we propose two new perspectives within the faithfulness paradigm that reveal intuitive properties: soundness and completeness. Soundness assesses the degree to which attributed features are truly predictive features, while completeness examines how well the resulting attribution reveals all the predictive features. The two perspectives are based on a firm mathematical foundation and provide quantitative metrics that are computable through efficient algorithms. We apply these metrics to mainstream attribution methods, offering a novel lens through which to analyze and compare feature attribution methods.