 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Document Embeddings via Self-Contrastive Bregman Divergence Learning
May 25, 2023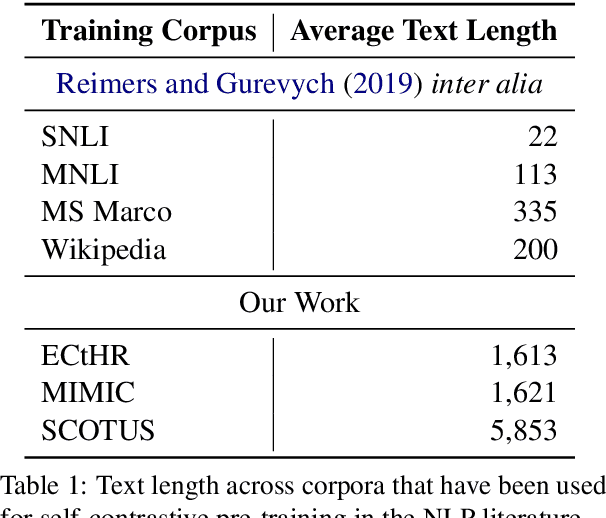
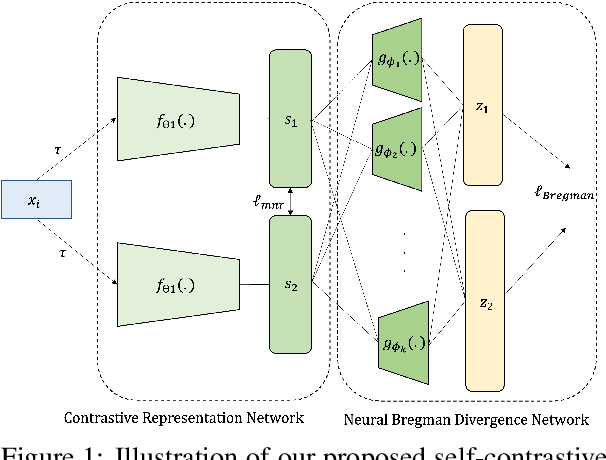
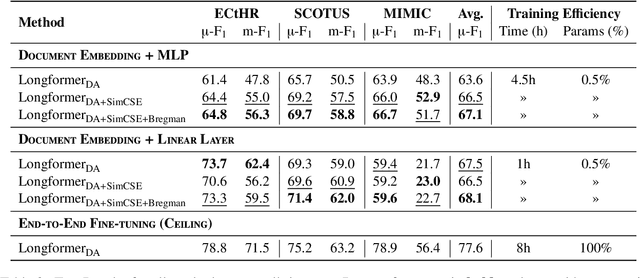

Learning quality document embeddings is a fundamental problem in natural language processing (NLP), information retrieval (IR), recommendation systems, and search engines. Despite recent advances in the development of transformer-based models that produce sentence embeddings with self-contrastive learning, the encoding of long documents (Ks of words) is still challenging with respect to both efficiency and quality considerations. Therefore, we train Longfomer-based document encoders using a state-of-the-art unsupervised contrastive learning method (SimCSE). Further on, we complement the baseline method -- siamese neural network -- with additional convex neural networks based on functional Bregman divergence aiming to enhance the quality of the output document representations. We show that overall the combination of a self-contrastive siamese network and our proposed neural Bregman network outperforms the baselines in two linear classification settings on three long document topic classification tasks from the legal and biomedical domains.