 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models
Paper and Code
May 28, 2024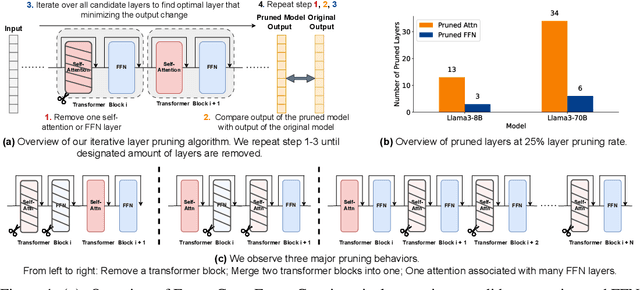
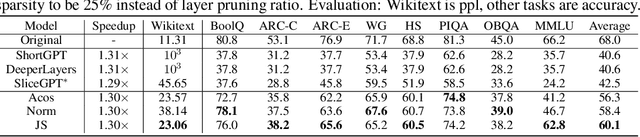
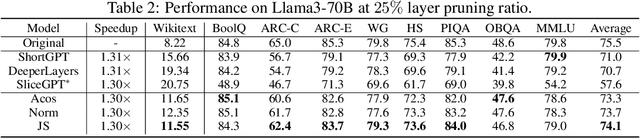
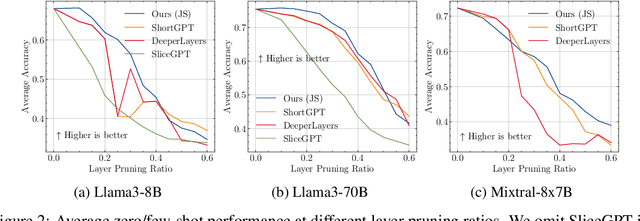
Overparametrized transformer networks are the state-of-the-art architecture for Large Language Models (LLMs). However, such models contain billions of parameters making large compute a necessity, while raising environmental concerns. To address these issues, we propose FinerCut, a new form of fine-grained layer pruning, which in contrast to prior work at the transformer block level, considers all self-attention and feed-forward network (FFN) layers within blocks as individual pruning candidates. FinerCut prunes layers whose removal causes minimal alternation to the model's output -- contributing to a new, lean, interpretable, and task-agnostic pruning method. Tested across 9 benchmarks, our approach retains 90% performance of Llama3-8B with 25% layers removed, and 95% performance of Llama3-70B with 30% layers removed, all without fine-tuning or post-pruning reconstruction. Strikingly, we observe intriguing results with FinerCut: 42% (34 out of 80) of the self-attention layers in Llama3-70B can be removed while preserving 99% of its performance -- without additional fine-tuning after removal. Moreover, FinerCut provides a tool to inspect the types and locations of pruned layers, allowing to observe interesting pruning behaviors. For instance, we observe a preference for pruning self-attention layers, often at deeper consecutive decoder layers. We hope our insights inspire future efficient LLM architecture designs.