 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Diffusion Policy: manipulation trajectory generation via contact guidance
Paper and Code
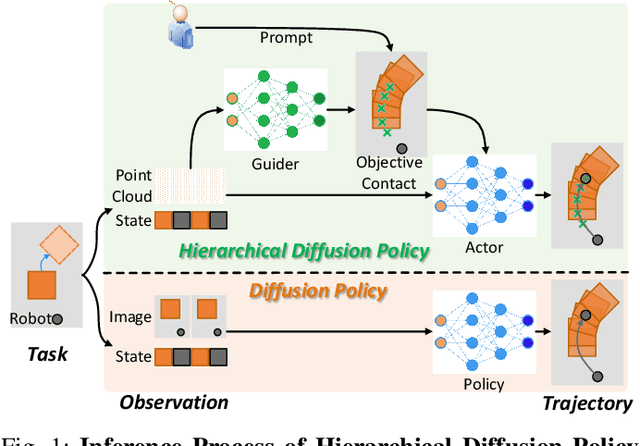


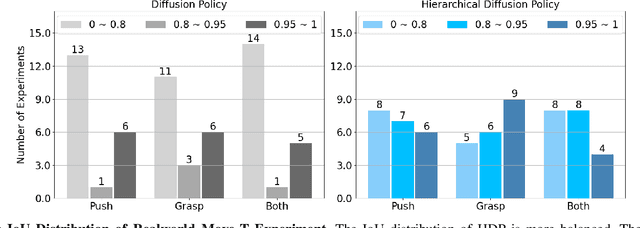
Decision-making in robotics using denoising diffusion processes has increasingly become a hot research topic, but end-to-end policies perform poorly in tasks with rich contact and have limited controllability. This paper proposes Hierarchical Diffusion Policy (HDP), a new imitation learning method of using objective contacts to guide the generation of robot trajectories. The policy is divided into two layers: the high-level policy predicts the contact for the robot's next object manipulation based on 3D information, while the low-level policy predicts the action sequence toward the high-level contact based on the latent variables of observation and contact. We represent both level policies as conditional denoising diffusion processes, and combine behavioral cloning and Q-learning to optimize the low level policy for accurately guiding actions towards contact. We benchmark Hierarchical Diffusion Policy across 6 different tasks and find that it significantly outperforms the existing state of-the-art imitation learning method Diffusion Policy with an average improvement of 20.8%. We find that contact guidance yields significant improvements, including superior performance, greater interpretability, and stronger controllability, especially on contact-rich tasks. To further unlock the potential of HDP, this paper proposes a set of key technical contributions including snapshot gradient optimization, 3D conditioning, and prompt guidance, which improve the policy's optimization efficiency, spatial awareness, and controllability respectively. Finally, real world experiments verify that HDP can handle both rigid and deformable objects.