 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForeRobo: Unlocking Infinite Simulation Data for 3D Goal-driven Robotic Manipulation
Nov 06, 2025Efficiently leveraging simulation to acquire advanced manipulation skills is both challenging and highly significant. We introduce \textit{ForeRobo}, a generative robotic agent that utilizes generative simulations to autonomously acquire manipulation skills driven by envisioned goal states. Instead of directly learning low-level policies, we advocate integrating generative paradigms with classical control. Our approach equips a robotic agent with a self-guided \textit{propose-generate-learn-actuate} cycle. The agent first proposes the skills to be acquired and constructs the corresponding simulation environments; it then configures objects into appropriate arrangements to generate skill-consistent goal states (\textit{ForeGen}). Subsequently, the virtually infinite data produced by ForeGen are used to train the proposed state generation model (\textit{ForeFormer}), which establishes point-wise correspondences by predicting the 3D goal position of every point in the current state, based on the scene state and task instructions. Finally, classical control algorithms are employed to drive the robot in real-world environments to execute actions based on the envisioned goal states. Compared with end-to-end policy learning methods, ForeFormer offers superior interpretability and execution efficiency. We train and benchmark ForeFormer across a variety of rigid-body and articulated-object manipulation tasks, and observe an average improvement of 56.32\% over the state-of-the-art state generation models, demonstrating strong generality across different manipulation patterns. Moreover, in real-world evaluations involving more than 20 robotic tasks, ForeRobo achieves zero-shot sim-to-real transfer and exhibits remarkable generalization capabilities, attaining an average success rate of 79.28\%.
Goal State Generation for Robotic Manipulation Based on Linguistically Guided Hybrid Gaussian Diffusion
Dec 25, 2024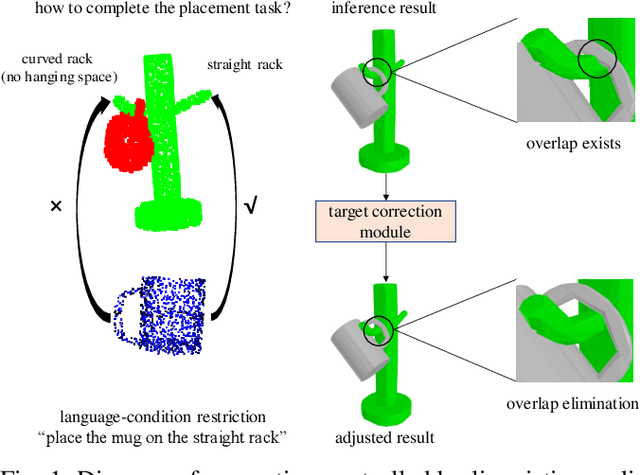
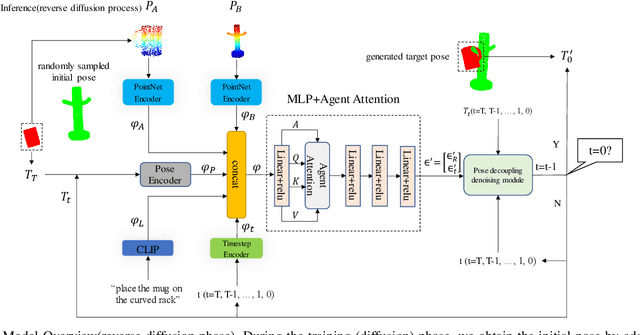
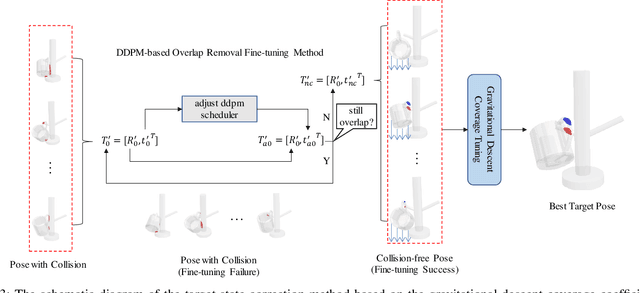

In robotic manipulation tasks, achieving a designated target state for the manipulated object is often essential to facilitate motion planning for robotic arms. Specifically, in tasks such as hanging a mug, the mug must be positioned within a feasible region around the hook. Previous approaches have enabled the generation of multiple feasible target states for mugs; however, these target states are typically generated randomly, lacking control over the specific generation locations. This limitation makes such methods less effective in scenarios where constraints exist, such as hooks already occupied by other mugs or when specific operational objectives must be met. Moreover, due to the frequent physical interactions between the mug and the rack in real-world hanging scenarios, imprecisely generated target states from end-to-end models often result in overlapping point clouds. This overlap adversely impacts subsequent motion planning for the robotic arm. To address these challenges, we propose a Linguistically Guided Hybrid Gaussian Diffusion (LHGD) network for generating manipulation target states, combined with a gravity coverage coefficient-based method for target state refinement. To evaluate our approach under a language-specified distribution setting, we collected multiple feasible target states for 10 types of mugs across 5 different racks with 10 distinct hooks. Additionally, we prepared five unseen mug designs for validation purposes. Experimental results demonstrate that our method achieves the highest success rates across single-mode, multi-mode, and language-specified distribution manipulation tasks. Furthermore, it significantly reduces point cloud overlap, directly producing collision-free target states and eliminating the need for additional obstacle avoidance operations by the robotic arm.
Hierarchical Diffusion Policy: manipulation trajectory generation via contact guidance
Nov 20, 2024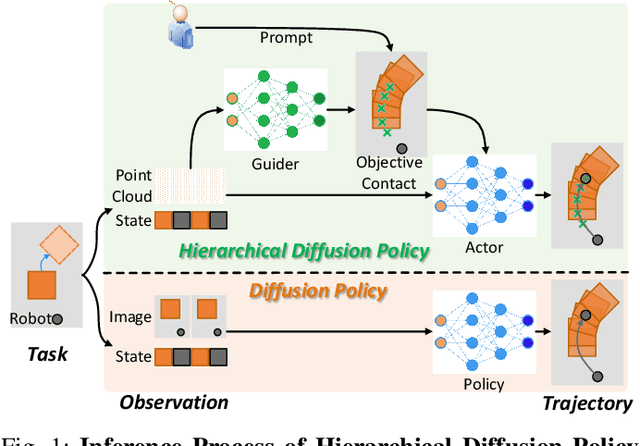


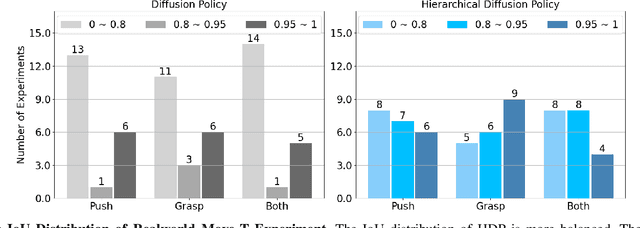
Decision-making in robotics using denoising diffusion processes has increasingly become a hot research topic, but end-to-end policies perform poorly in tasks with rich contact and have limited controllability. This paper proposes Hierarchical Diffusion Policy (HDP), a new imitation learning method of using objective contacts to guide the generation of robot trajectories. The policy is divided into two layers: the high-level policy predicts the contact for the robot's next object manipulation based on 3D information, while the low-level policy predicts the action sequence toward the high-level contact based on the latent variables of observation and contact. We represent both level policies as conditional denoising diffusion processes, and combine behavioral cloning and Q-learning to optimize the low level policy for accurately guiding actions towards contact. We benchmark Hierarchical Diffusion Policy across 6 different tasks and find that it significantly outperforms the existing state of-the-art imitation learning method Diffusion Policy with an average improvement of 20.8%. We find that contact guidance yields significant improvements, including superior performance, greater interpretability, and stronger controllability, especially on contact-rich tasks. To further unlock the potential of HDP, this paper proposes a set of key technical contributions including snapshot gradient optimization, 3D conditioning, and prompt guidance, which improve the policy's optimization efficiency, spatial awareness, and controllability respectively. Finally, real world experiments verify that HDP can handle both rigid and deformable objects.
EraW-Net: Enhance-Refine-Align W-Net for Scene-Associated Driver Attention Estimation
Aug 16, 2024
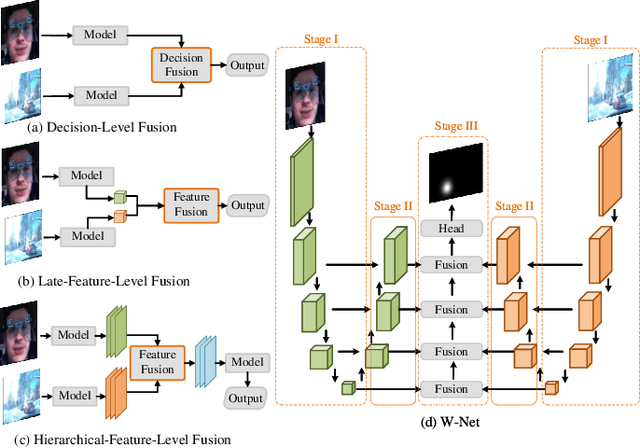
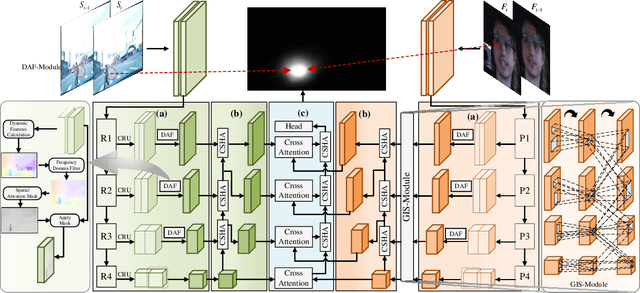
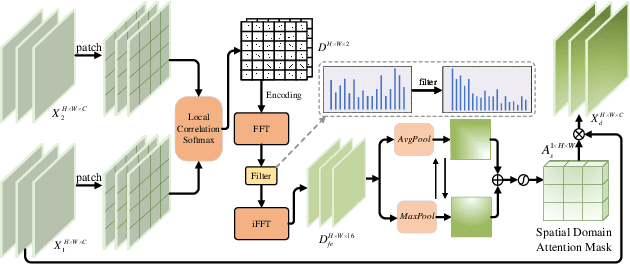
Associating driver attention with driving scene across two fields of views (FOVs) is a hard cross-domain perception problem, which requires comprehensive consideration of cross-view mapping, dynamic driving scene analysis, and driver status tracking. Previous methods typically focus on a single view or map attention to the scene via estimated gaze, failing to exploit the implicit connection between them. Moreover, simple fusion modules are insufficient for modeling the complex relationships between the two views, making information integration challenging. To address these issues, we propose a novel method for end-to-end scene-associated driver attention estimation, called EraW-Net. This method enhances the most discriminative dynamic cues, refines feature representations, and facilitates semantically aligned cross-domain integration through a W-shaped architecture, termed W-Net. Specifically, a Dynamic Adaptive Filter Module (DAF-Module) is proposed to address the challenges of frequently changing driving environments by extracting vital regions. It suppresses the indiscriminately recorded dynamics and highlights crucial ones by innovative joint frequency-spatial analysis, enhancing the model's ability to parse complex dynamics. Additionally, to track driver states during non-fixed facial poses, we propose a Global Context Sharing Module (GCS-Module) to construct refined feature representations by capturing hierarchical features that adapt to various scales of head and eye movements. Finally, W-Net achieves systematic cross-view information integration through its "Encoding-Independent Partial Decoding-Fusion Decoding" structure, addressing semantic misalignment in heterogeneous data integration. Experiments demonstrate that the proposed method robustly and accurately estimates the mapping of driver attention in scene on large public datasets.
Multi-Stage Reinforcement Learning for Non-Prehensile Manipulation
Jul 22, 2023



Manipulating objects without grasping them enables more complex tasks, known as non-prehensile manipulation. Most previous methods only learn one manipulation skill, such as reach or push, and cannot achieve flexible object manipulation.In this work, we introduce MRLM, a Multi-stage Reinforcement Learning approach for non-prehensile Manipulation of objects.MRLM divides the task into multiple stages according to the switching of object poses and contact points.At each stage, the policy takes the point cloud-based state-goal fusion representation as input, and proposes a spatially-continuous action that including the motion of the parallel gripper pose and opening width.To fully unlock the potential of MRLM, we propose a set of technical contributions including the state-goal fusion representation, spatially-reachable distance metric, and automatic buffer compaction.We evaluate MRLM on an Occluded Grasping task which aims to grasp the object in configurations that are initially occluded.Compared with the baselines, the proposed technical contributions improve the success rate by at least 40\% and maximum 100\%, and avoids falling into local optimum.Our method demonstrates strong generalization to unseen object with shapes outside the training distribution.Moreover, MRLM can be transferred to real world with zero-shot transfer, achieving a 95\% success rate.Code and videos can be found at https://sites.google.com/view/mrlm.
On-Policy Pixel-Level Grasping Across the Gap Between Simulation and Reality
Apr 08, 2022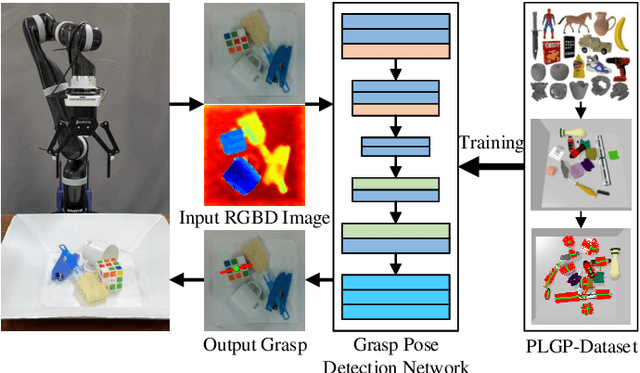
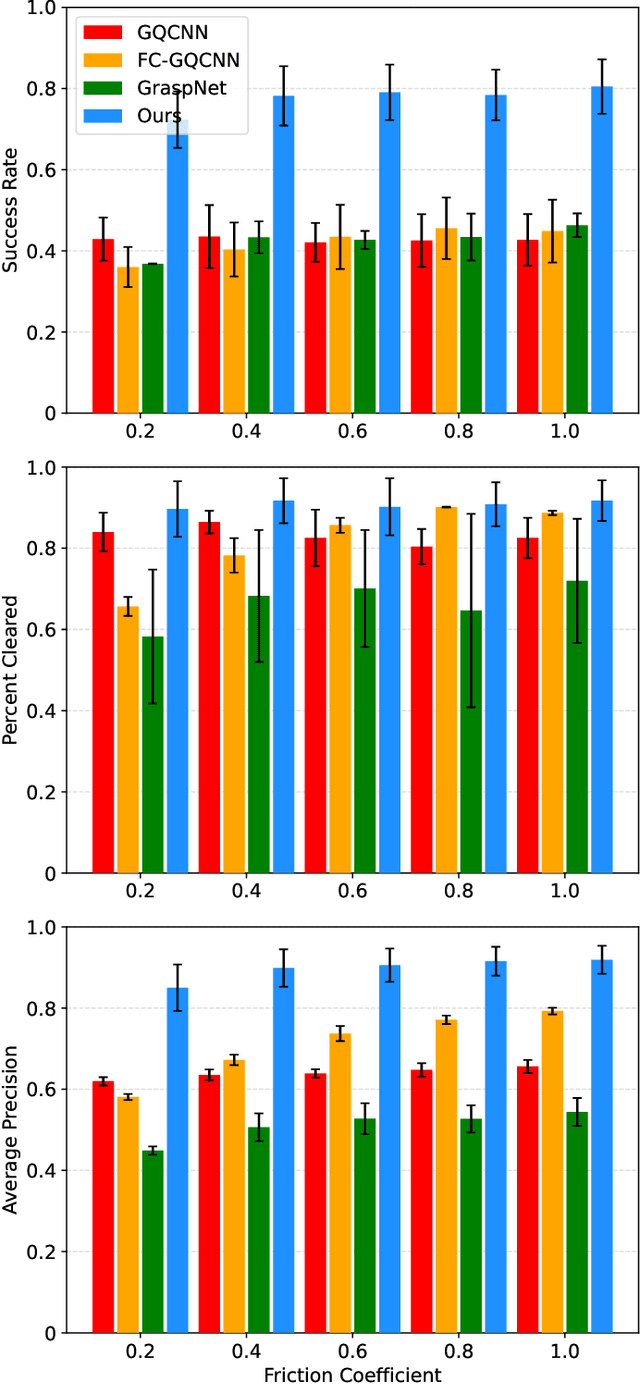


Grasp detection in cluttered scenes is a very challenging task for robots. Generating synthetic grasping data is a popular way to train and test grasp methods, as is Dex-net and GraspNet; yet, these methods generate training grasps on 3D synthetic object models, but evaluate at images or point clouds with different distributions, which reduces performance on real scenes due to sparse grasp labels and covariate shift. To solve existing problems, we propose a novel on-policy grasp detection method, which can train and test on the same distribution with dense pixel-level grasp labels generated on RGB-D images. A Parallel-Depth Grasp Generation (PDG-Generation) method is proposed to generate a parallel depth image through a new imaging model of projecting points in parallel; then this method generates multiple candidate grasps for each pixel and obtains robust grasps through flatness detection, force-closure metric and collision detection. Then, a large comprehensive Pixel-Level Grasp Pose Dataset (PLGP-Dataset) is constructed and released; distinguished with previous datasets with off-policy data and sparse grasp samples, this dataset is the first pixel-level grasp dataset, with the on-policy distribution where grasps are generated based on depth images. Lastly, we build and test a series of pixel-level grasp detection networks with a data augmentation process for imbalance training, which learn grasp poses in a decoupled manner on the input RGB-D images. Extensive experiments show that our on-policy grasp method can largely overcome the gap between simulation and reality, and achieves the state-of-the-art performance. Code and data are provided at https://github.com/liuchunsense/PLGP-Dataset.
Guidance Module Network for Video Captioning
Dec 20, 2020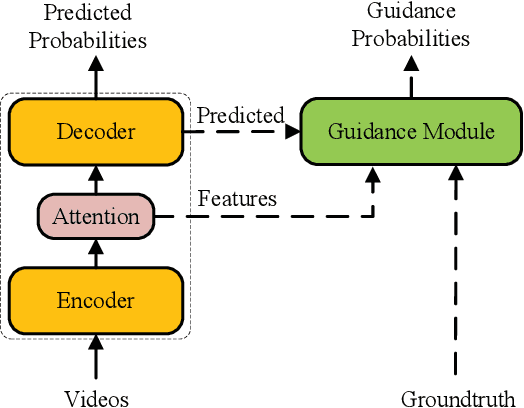
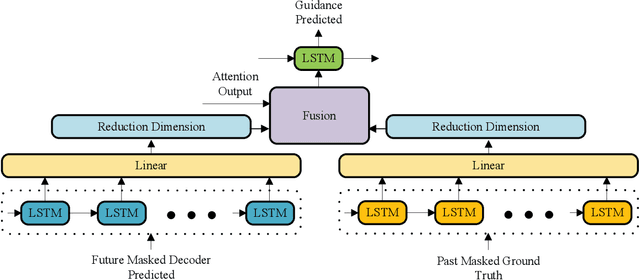
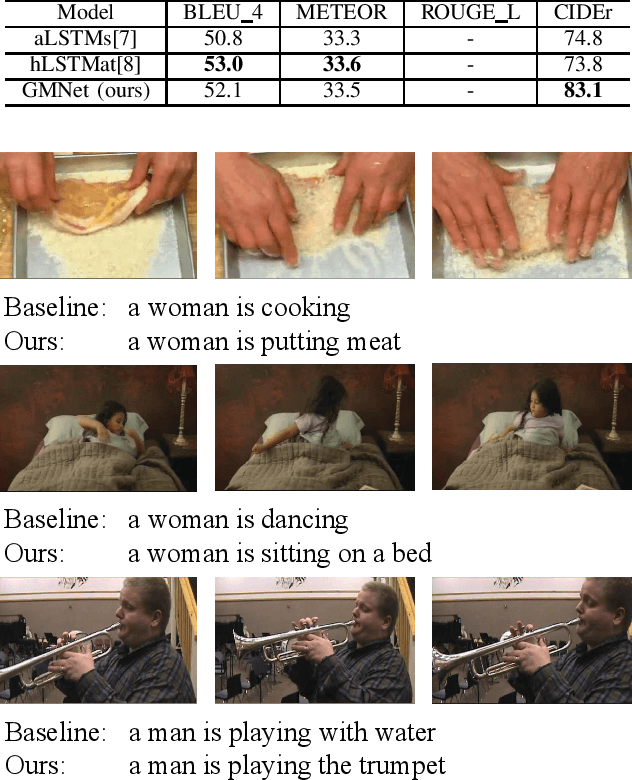
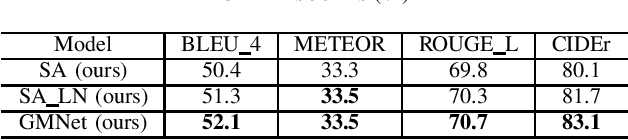
Video captioning has been a challenging and significant task that describes the content of a video clip in a single sentence. The model of video captioning is usually an encoder-decoder. We find that the normalization of extracted video features can improve the final performance of video captioning. Encoder-decoder model is usually trained using teacher-enforced strategies to make the prediction probability of each word close to a 0-1 distribution and ignore other words. In this paper, we present a novel architecture which introduces a guidance module to encourage the encoder-decoder model to generate words related to the past and future words in a caption. Based on the normalization and guidance module, guidance module net (GMNet) is built. Experimental results on commonly used dataset MSVD show that proposed GMNet can improve the performance of the encoder-decoder model on video captioning tasks.
Attention to Head Locations for Crowd Counting
Jun 27, 2018

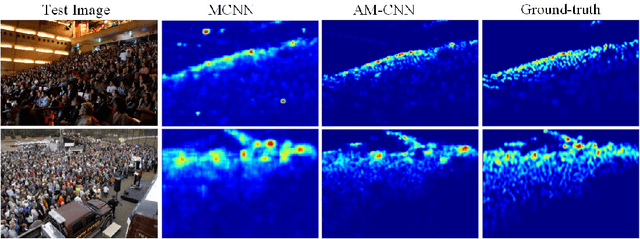
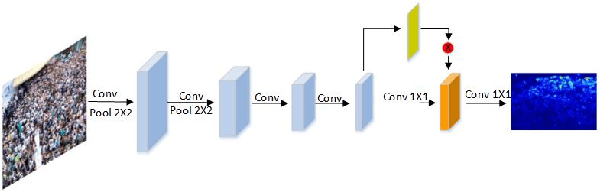
Occlusions, complex backgrounds, scale variations and non-uniform distributions present great challenges for crowd counting in practical applications. In this paper, we propose a novel method using an attention model to exploit head locations which are the most important cue for crowd counting. The attention model estimates a probability map in which high probabilities indicate locations where heads are likely to be present. The estimated probability map is used to suppress non-head regions in feature maps from several multi-scale feature extraction branches of a convolution neural network for crowd density estimation, which makes our method robust to complex backgrounds, scale variations and non-uniform distributions. In addition, we introduce a relative deviation loss to compensate a commonly used training loss, Euclidean distance, to improve the accuracy of sparse crowd density estimation. Experiments on Shanghai-Tech, UCF_CC_50 and World-Expo'10 data sets demonstrate the effectiveness of our method.