 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Modality-Experts with Holistic Token Learning for Fine-Grained Multimodal Visual Analytics in Driver Action Recognition
Apr 07, 2026Robust multimodal visual analytics remains challenging when heterogeneous modalities provide complementary but input-dependent evidence for decision-making.Existing multimodal learning methods mainly rely on fixed fusion modules or predefined cross-modal interactions, which are often insufficient to adapt to changing modality reliability and to capture fine-grained action cues. To address this issue, we propose a Mixture-of-Modality-Experts (MoME) framework with a Holistic Token Learning (HTL) strategy. MoME enables adaptive collaboration among modality-specific experts, while HTL improves both intra-expert refinement and inter-expert knowledge transfer through class tokens and spatio-temporal tokens. In this way, our method forms a knowledge-centric multimodal learning framework that improves expert specialization while reducing ambiguity in multimodal fusion.We validate the proposed framework on driver action recognition as a representative multimodal understanding taskThe experimental results on the public benchmark show that the proposed MoME framework and the HTL strategy jointly outperform representative single-modal and multimodal baselines. Additional ablation, validation, and visualization results further verify that the proposed HTL strategy improves subtle multimodal understanding and offers better interpretability.
DAOS: A Multimodal In-cabin Behavior Monitoring with Driver Action-Object Synergy Dataset
Jan 17, 2026In driver activity monitoring, movements are mostly limited to the upper body, which makes many actions look similar. To tell these actions apart, human often rely on the objects the driver is using, such as holding a phone compared with gripping the steering wheel. However, most existing driver-monitoring datasets lack accurate object-location annotations or do not link objects to their associated actions, leaving a critical gap for reliable action recognition. To address this, we introduce the Driver Action with Object Synergy (DAOS) dataset, comprising 9,787 video clips annotated with 36 fine-grained driver actions and 15 object classes, totaling more than 2.5 million corresponding object instances. DAOS offers multi-modal, multi-view data (RGB, IR, and depth) from front, face, left, and right perspectives. Although DAOS captures a wide range of cabin objects, only a few are directly relevant to each action for prediction, so focusing on task-specific human-object relations is essential. To tackle this challenge, we propose the Action-Object-Relation Network (AOR-Net). AOR-Net comprehends complex driver actions through multi-level reasoning and a chain-of-action prompting mechanism that models the logical relationships among actions, objects, and their relations. Additionally, the Mixture of Thoughts module is introduced to dynamically select essential knowledge at each stage, enhancing robustness in object-rich and object-scarce conditions. Extensive experiments demonstrate that our model outperforms other state-of-the-art methods on various datasets.
Visual Spatial Tuning
Nov 07, 2025Capturing spatial relationships from visual inputs is a cornerstone of human-like general intelligence. Several previous studies have tried to enhance the spatial awareness of Vision-Language Models (VLMs) by adding extra expert encoders, which brings extra overhead and usually harms general capabilities. To enhance the spatial ability in general architectures, we introduce Visual Spatial Tuning (VST), a comprehensive framework to cultivate VLMs with human-like visuospatial abilities, from spatial perception to reasoning. We first attempt to enhance spatial perception in VLMs by constructing a large-scale dataset termed VST-P, which comprises 4.1 million samples spanning 19 skills across single views, multiple images, and videos. Then, we present VST-R, a curated dataset with 135K samples that instruct models to reason in space. In particular, we adopt a progressive training pipeline: supervised fine-tuning to build foundational spatial knowledge, followed by reinforcement learning to further improve spatial reasoning abilities. Without the side-effect to general capabilities, the proposed VST consistently achieves state-of-the-art results on several spatial benchmarks, including $34.8\%$ on MMSI-Bench and $61.2\%$ on VSIBench. It turns out that the Vision-Language-Action models can be significantly enhanced with the proposed spatial tuning paradigm, paving the way for more physically grounded AI.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Open World Object Detection: A Survey
Oct 15, 2024



Exploring new knowledge is a fundamental human ability that can be mirrored in the development of deep neural networks, especially in the field of object detection. Open world object detection (OWOD) is an emerging area of research that adapts this principle to explore new knowledge. It focuses on recognizing and learning from objects absent from initial training sets, thereby incrementally expanding its knowledge base when new class labels are introduced. This survey paper offers a thorough review of the OWOD domain, covering essential aspects, including problem definitions, benchmark datasets, source codes, evaluation metrics, and a comparative study of existing methods. Additionally, we investigate related areas like open set recognition (OSR) and incremental learning (IL), underlining their relevance to OWOD. Finally, the paper concludes by addressing the limitations and challenges faced by current OWOD algorithms and proposes directions for future research. To our knowledge, this is the first comprehensive survey of the emerging OWOD field with over one hundred references, marking a significant step forward for object detection technology. A comprehensive source code and benchmarks are archived and concluded at https://github.com/ArminLee/OWOD Review.
TDS-CLIP: Temporal Difference Side Network for Image-to-Video Transfer Learning
Aug 20, 2024
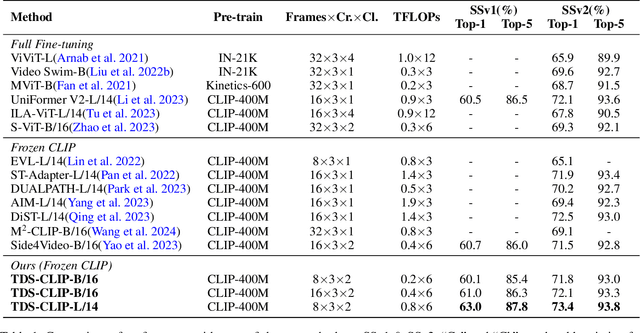

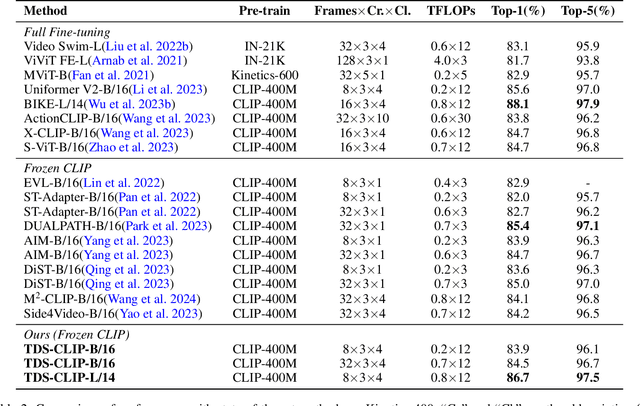
Recently, large-scale pre-trained vision-language models (e.g., CLIP), have garnered significant attention thanks to their powerful representative capabilities. This inspires researchers in transferring the knowledge from these large pre-trained models to other task-specific models, e.g., Video Action Recognition (VAR) models, via particularly leveraging side networks to enhance the efficiency of parameter-efficient fine-tuning (PEFT). However, current transferring approaches in VAR tend to directly transfer the frozen knowledge from large pre-trained models to action recognition networks with minimal cost, instead of exploiting the temporal modeling capabilities of the action recognition models themselves. Therefore, in this paper, we propose a memory-efficient Temporal Difference Side Network (TDS-CLIP) to balance knowledge transferring and temporal modeling, avoiding backpropagation in frozen parameter models. Specifically, we introduce a Temporal Difference Adapter (TD-Adapter), which can effectively capture local temporal differences in motion features to strengthen the model's global temporal modeling capabilities. Furthermore, we designed a Side Motion Enhancement Adapter (SME-Adapter) to guide the proposed side network in efficiently learning the rich motion information in videos, thereby improving the side network's ability to capture and learn motion information. Extensive experiments are conducted on three benchmark datasets, including Something-Something V1\&V2, and Kinetics-400. Experimental results demonstrate that our approach achieves competitive performance.
EraW-Net: Enhance-Refine-Align W-Net for Scene-Associated Driver Attention Estimation
Aug 16, 2024
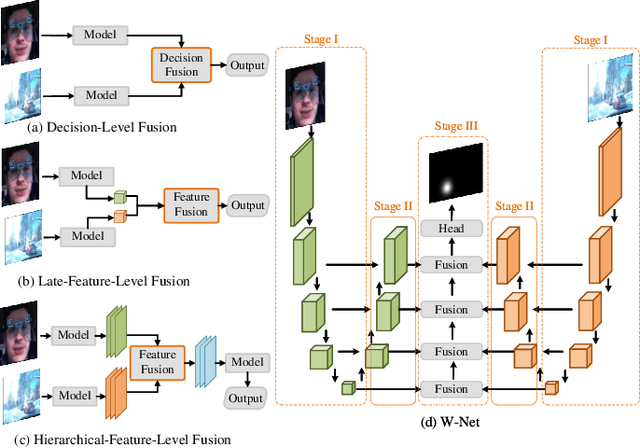
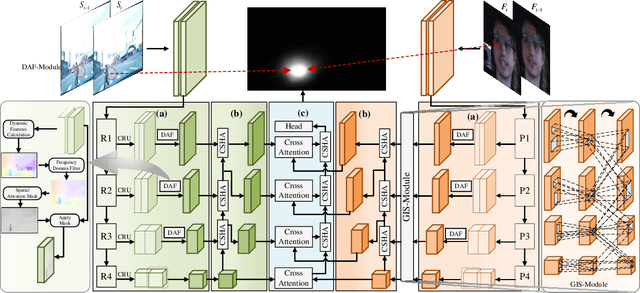
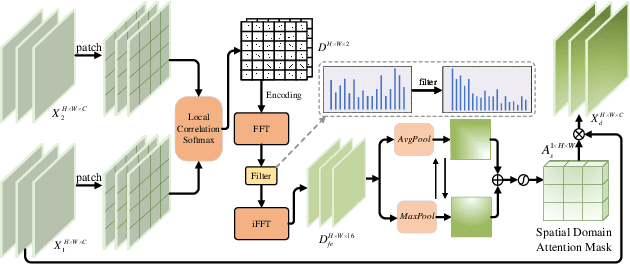
Associating driver attention with driving scene across two fields of views (FOVs) is a hard cross-domain perception problem, which requires comprehensive consideration of cross-view mapping, dynamic driving scene analysis, and driver status tracking. Previous methods typically focus on a single view or map attention to the scene via estimated gaze, failing to exploit the implicit connection between them. Moreover, simple fusion modules are insufficient for modeling the complex relationships between the two views, making information integration challenging. To address these issues, we propose a novel method for end-to-end scene-associated driver attention estimation, called EraW-Net. This method enhances the most discriminative dynamic cues, refines feature representations, and facilitates semantically aligned cross-domain integration through a W-shaped architecture, termed W-Net. Specifically, a Dynamic Adaptive Filter Module (DAF-Module) is proposed to address the challenges of frequently changing driving environments by extracting vital regions. It suppresses the indiscriminately recorded dynamics and highlights crucial ones by innovative joint frequency-spatial analysis, enhancing the model's ability to parse complex dynamics. Additionally, to track driver states during non-fixed facial poses, we propose a Global Context Sharing Module (GCS-Module) to construct refined feature representations by capturing hierarchical features that adapt to various scales of head and eye movements. Finally, W-Net achieves systematic cross-view information integration through its "Encoding-Independent Partial Decoding-Fusion Decoding" structure, addressing semantic misalignment in heterogeneous data integration. Experiments demonstrate that the proposed method robustly and accurately estimates the mapping of driver attention in scene on large public datasets.
MultiFuser: Multimodal Fusion Transformer for Enhanced Driver Action Recognition
Aug 03, 2024Driver action recognition, aiming to accurately identify drivers' behaviours, is crucial for enhancing driver-vehicle interactions and ensuring driving safety. Unlike general action recognition, drivers' environments are often challenging, being gloomy and dark, and with the development of sensors, various cameras such as IR and depth cameras have emerged for analyzing drivers' behaviors. Therefore, in this paper, we propose a novel multimodal fusion transformer, named MultiFuser, which identifies cross-modal interrelations and interactions among multimodal car cabin videos and adaptively integrates different modalities for improved representations. Specifically, MultiFuser comprises layers of Bi-decomposed Modules to model spatiotemporal features, with a modality synthesizer for multimodal features integration. Each Bi-decomposed Module includes a Modal Expertise ViT block for extracting modality-specific features and a Patch-wise Adaptive Fusion block for efficient cross-modal fusion. Extensive experiments are conducted on Drive&Act dataset and the results demonstrate the efficacy of our proposed approach.
CM2-Net: Continual Cross-Modal Mapping Network for Driver Action Recognition
Jun 18, 2024Driver action recognition has significantly advanced in enhancing driver-vehicle interactions and ensuring driving safety by integrating multiple modalities, such as infrared and depth. Nevertheless, compared to RGB modality only, it is always laborious and costly to collect extensive data for all types of non-RGB modalities in car cabin environments. Therefore, previous works have suggested independently learning each non-RGB modality by fine-tuning a model pre-trained on RGB videos, but these methods are less effective in extracting informative features when faced with newly-incoming modalities due to large domain gaps. In contrast, we propose a Continual Cross-Modal Mapping Network (CM2-Net) to continually learn each newly-incoming modality with instructive prompts from the previously-learned modalities. Specifically, we have developed Accumulative Cross-modal Mapping Prompting (ACMP), to map the discriminative and informative features learned from previous modalities into the feature space of newly-incoming modalities. Then, when faced with newly-incoming modalities, these mapped features are able to provide effective prompts for which features should be extracted and prioritized. These prompts are accumulating throughout the continual learning process, thereby boosting further recognition performances. Extensive experiments conducted on the Drive&Act dataset demonstrate the performance superiority of CM2-Net on both uni- and multi-modal driver action recognition.
UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles
Apr 12, 2021
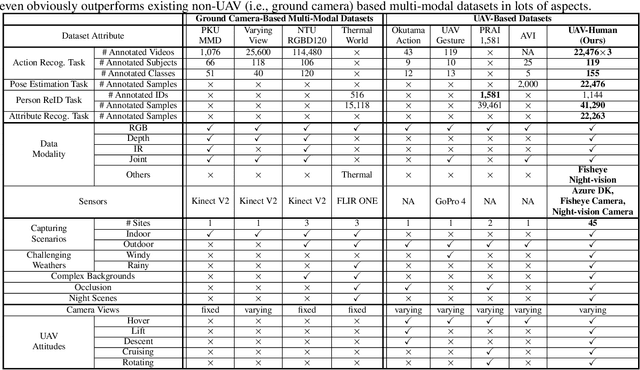


Human behavior understanding with unmanned aerial vehicles (UAVs) is of great significance for a wide range of applications, which simultaneously brings an urgent demand of large, challenging, and comprehensive benchmarks for the development and evaluation of UAV-based models. However, existing benchmarks have limitations in terms of the amount of captured data, types of data modalities, categories of provided tasks, and diversities of subjects and environments. Here we propose a new benchmark - UAVHuman - for human behavior understanding with UAVs, which contains 67,428 multi-modal video sequences and 119 subjects for action recognition, 22,476 frames for pose estimation, 41,290 frames and 1,144 identities for person re-identification, and 22,263 frames for attribute recognition. Our dataset was collected by a flying UAV in multiple urban and rural districts in both daytime and nighttime over three months, hence covering extensive diversities w.r.t subjects, backgrounds, illuminations, weathers, occlusions, camera motions, and UAV flying attitudes. Such a comprehensive and challenging benchmark shall be able to promote the research of UAV-based human behavior understanding, including action recognition, pose estimation, re-identification, and attribute recognition. Furthermore, we propose a fisheye-based action recognition method that mitigates the distortions in fisheye videos via learning unbounded transformations guided by flat RGB videos. Experiments show the efficacy of our method on the UAV-Human dataset. The project page: https://github.com/SUTDCV/UAV-Human