 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Diffusion-based Video Editing via Heterogeneous Caching: Beyond Full Computing at Sampled Denoising Timestep
Mar 25, 2026Diffusion-based video editing has emerged as an important paradigm for high-quality and flexible content generation. However, despite their generality and strong modeling capacity, Diffusion Transformers (DiT) remain computationally expensive due to the iterative denoising process, posing challenges for practical deployment. Existing video diffusion acceleration methods primarily exploit denoising timestep-level feature reuse, which mitigates the redundancy in denoising process, but overlooks the architectural redundancy within the DiT that many attention operations over spatio-temporal tokens are redundantly executed, offering little to no incremental contribution to the model output. This work introduces HetCache, a training-free diffusion acceleration framework designed to exploit the inherent heterogeneity in diffusion-based masked video-to-video (MV2V) generation and editing. Instead of uniformly reuse or randomly sampling tokens, HetCache assesses the contextual relevance and interaction strength among various types of tokens in designated computing steps. Guided by spatial priors, it divides the spatial-temporal tokens in DiT model into context and generative tokens, and selectively caches the context tokens that exhibit the strongest correlation and most representative semantics with generative ones. This strategy reduces redundant attention operations while maintaining editing consistency and fidelity. Experiments show that HetCache achieves a noticeable acceleration, including a 2.67$\times$ latency speedup and FLOPs reduction over commonly used foundation models, with negligible degradation in editing quality.
SSH-Net: A Self-Supervised and Hybrid Network for Noisy Image Watermark Removal
May 08, 2025Visible watermark removal is challenging due to its inherent complexities and the noise carried within images. Existing methods primarily rely on supervised learning approaches that require paired datasets of watermarked and watermark-free images, which are often impractical to obtain in real-world scenarios. To address this challenge, we propose SSH-Net, a Self-Supervised and Hybrid Network specifically designed for noisy image watermark removal. SSH-Net synthesizes reference watermark-free images using the watermark distribution in a self-supervised manner and adopts a dual-network design to address the task. The upper network, focused on the simpler task of noise removal, employs a lightweight CNN-based architecture, while the lower network, designed to handle the more complex task of simultaneously removing watermarks and noise, incorporates Transformer blocks to model long-range dependencies and capture intricate image features. To enhance the model's effectiveness, a shared CNN-based feature encoder is introduced before dual networks to extract common features that both networks can leverage. Our code will be available at https://github.com/wenyang001/SSH-Net.
CL-HOI: Cross-Level Human-Object Interaction Distillation from Vision Large Language Models
Oct 21, 2024Human-object interaction (HOI) detection has seen advancements with Vision Language Models (VLMs), but these methods often depend on extensive manual annotations. Vision Large Language Models (VLLMs) can inherently recognize and reason about interactions at the image level but are computationally heavy and not designed for instance-level HOI detection. To overcome these limitations, we propose a Cross-Level HOI distillation (CL-HOI) framework, which distills instance-level HOIs from VLLMs image-level understanding without the need for manual annotations. Our approach involves two stages: context distillation, where a Visual Linguistic Translator (VLT) converts visual information into linguistic form, and interaction distillation, where an Interaction Cognition Network (ICN) reasons about spatial, visual, and context relations. We design contrastive distillation losses to transfer image-level context and interaction knowledge from the teacher to the student model, enabling instance-level HOI detection. Evaluations on HICO-DET and V-COCO datasets demonstrate that our CL-HOI surpasses existing weakly supervised methods and VLLM supervised methods, showing its efficacy in detecting HOIs without manual labels.
Empowering Large Language Model for Continual Video Question Answering with Collaborative Prompting
Oct 01, 2024



In recent years, the rapid increase in online video content has underscored the limitations of static Video Question Answering (VideoQA) models trained on fixed datasets, as they struggle to adapt to new questions or tasks posed by newly available content. In this paper, we explore the novel challenge of VideoQA within a continual learning framework, and empirically identify a critical issue: fine-tuning a large language model (LLM) for a sequence of tasks often results in catastrophic forgetting. To address this, we propose Collaborative Prompting (ColPro), which integrates specific question constraint prompting, knowledge acquisition prompting, and visual temporal awareness prompting. These prompts aim to capture textual question context, visual content, and video temporal dynamics in VideoQA, a perspective underexplored in prior research. Experimental results on the NExT-QA and DramaQA datasets show that ColPro achieves superior performance compared to existing approaches, achieving 55.14\% accuracy on NExT-QA and 71.24\% accuracy on DramaQA, highlighting its practical relevance and effectiveness.
MultiFuser: Multimodal Fusion Transformer for Enhanced Driver Action Recognition
Aug 03, 2024Driver action recognition, aiming to accurately identify drivers' behaviours, is crucial for enhancing driver-vehicle interactions and ensuring driving safety. Unlike general action recognition, drivers' environments are often challenging, being gloomy and dark, and with the development of sensors, various cameras such as IR and depth cameras have emerged for analyzing drivers' behaviors. Therefore, in this paper, we propose a novel multimodal fusion transformer, named MultiFuser, which identifies cross-modal interrelations and interactions among multimodal car cabin videos and adaptively integrates different modalities for improved representations. Specifically, MultiFuser comprises layers of Bi-decomposed Modules to model spatiotemporal features, with a modality synthesizer for multimodal features integration. Each Bi-decomposed Module includes a Modal Expertise ViT block for extracting modality-specific features and a Patch-wise Adaptive Fusion block for efficient cross-modal fusion. Extensive experiments are conducted on Drive&Act dataset and the results demonstrate the efficacy of our proposed approach.
CM2-Net: Continual Cross-Modal Mapping Network for Driver Action Recognition
Jun 18, 2024Driver action recognition has significantly advanced in enhancing driver-vehicle interactions and ensuring driving safety by integrating multiple modalities, such as infrared and depth. Nevertheless, compared to RGB modality only, it is always laborious and costly to collect extensive data for all types of non-RGB modalities in car cabin environments. Therefore, previous works have suggested independently learning each non-RGB modality by fine-tuning a model pre-trained on RGB videos, but these methods are less effective in extracting informative features when faced with newly-incoming modalities due to large domain gaps. In contrast, we propose a Continual Cross-Modal Mapping Network (CM2-Net) to continually learn each newly-incoming modality with instructive prompts from the previously-learned modalities. Specifically, we have developed Accumulative Cross-modal Mapping Prompting (ACMP), to map the discriminative and informative features learned from previous modalities into the feature space of newly-incoming modalities. Then, when faced with newly-incoming modalities, these mapped features are able to provide effective prompts for which features should be extracted and prioritized. These prompts are accumulating throughout the continual learning process, thereby boosting further recognition performances. Extensive experiments conducted on the Drive&Act dataset demonstrate the performance superiority of CM2-Net on both uni- and multi-modal driver action recognition.
Video sentence grounding with temporally global textual knowledge
Apr 21, 2024Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
OccluTrack: Rethinking Awareness of Occlusion for Enhancing Multiple Pedestrian Tracking
Sep 19, 2023Multiple pedestrian tracking faces the challenge of tracking pedestrians in the presence of occlusion. Existing methods suffer from inaccurate motion estimation, appearance feature extraction, and association due to occlusion, leading to inadequate Identification F1-Score (IDF1), excessive ID switches (IDSw), and insufficient association accuracy and recall (AssA and AssR). We found that the main reason is abnormal detections caused by partial occlusion. In this paper, we suggest that the key insight is explicit motion estimation, reliable appearance features, and fair association in occlusion scenes. Specifically, we propose an adaptive occlusion-aware multiple pedestrian tracker, OccluTrack. We first introduce an abnormal motion suppression mechanism into the Kalman Filter to adaptively detect and suppress outlier motions caused by partial occlusion. Second, we propose a pose-guided re-ID module to extract discriminative part features for partially occluded pedestrians. Last, we design a new occlusion-aware association method towards fair IoU and appearance embedding distance measurement for occluded pedestrians. Extensive evaluation results demonstrate that our OccluTrack outperforms state-of-the-art methods on MOT-Challenge datasets. Particularly, the improvements on IDF1, IDSw, AssA, and AssR demonstrate the effectiveness of our OccluTrack on tracking and association performance.
Price Interpretability of Prediction Markets: A Convergence Analysis
May 18, 2022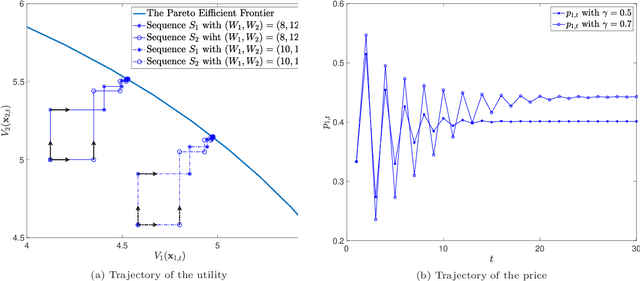
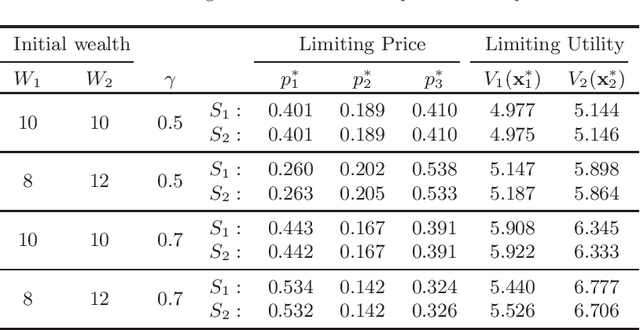
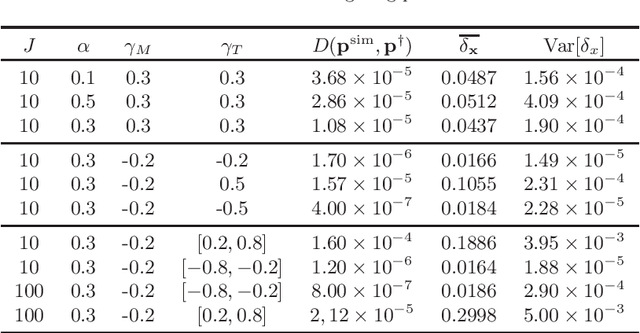
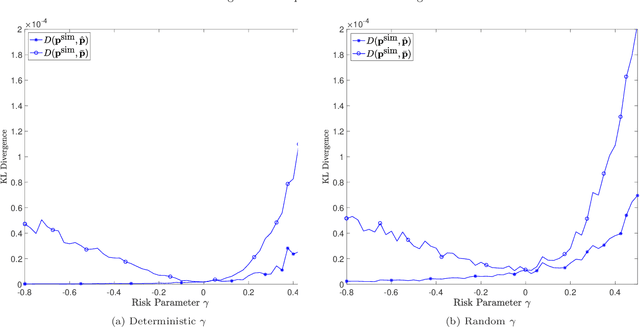
Prediction markets are long known for prediction accuracy. However, there is still a lack of systematic understanding of how prediction markets aggregate information and why they work so well. This work proposes a multivariate utility (MU)-based mechanism that unifies several existing prediction market-making schemes. Based on this mechanism, we derive convergence results for markets with myopic, risk-averse traders who repeatedly interact with the market maker. We show that the resulting limiting wealth distribution lies on the Pareto efficient frontier defined by all market participants' utilities. With the help of this result, we establish both analytical and numerical results for the limiting price for different market models. We show that the limiting price converges to the geometric mean of agents' beliefs for exponential utility-based markets. For risk measure-based markets, we construct a risk measure family that meets the convergence requirements and show that the limiting price can converge to a weighted power mean of agent beliefs. For markets based on hyperbolic absolute risk aversion (HARA) utilities, we show that the limiting price is also a risk-adjusted weighted power mean of agent beliefs, even though the trading order will affect the aggregation weights. We further propose an approximation scheme for the limiting price under the HARA utility family. We show through numerical experiments that our approximation scheme works well in predicting the convergent prices.