 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Egocentric Procedural AI Assistant: Methods, Benchmarks, and Challenges
Nov 17, 2025Driven by recent advances in vision language models (VLMs) and egocentric perception research, we introduce the concept of an egocentric procedural AI assistant (EgoProceAssist) tailored to step-by-step support daily procedural tasks in a first-person view. In this work, we start by identifying three core tasks: egocentric procedural error detection, egocentric procedural learning, and egocentric procedural question answering. These tasks define the essential functions of EgoProceAssist within a new taxonomy. Specifically, our work encompasses a comprehensive review of current techniques, relevant datasets, and evaluation metrics across these three core areas. To clarify the gap between the proposed EgoProceAssist and existing VLM-based AI assistants, we introduce novel experiments and provide a comprehensive evaluation of representative VLM-based methods. Based on these findings and our technical analysis, we discuss the challenges ahead and suggest future research directions. Furthermore, an exhaustive list of this study is publicly available in an active repository that continuously collects the latest work: https://github.com/z1oong/Building-Egocentric-Procedural-AI-Assistant
Towards Blind Bitstream-corrupted Video Recovery via a Visual Foundation Model-driven Framework
Jul 30, 2025Video signals are vulnerable in multimedia communication and storage systems, as even slight bitstream-domain corruption can lead to significant pixel-domain degradation. To recover faithful spatio-temporal content from corrupted inputs, bitstream-corrupted video recovery has recently emerged as a challenging and understudied task. However, existing methods require time-consuming and labor-intensive annotation of corrupted regions for each corrupted video frame, resulting in a large workload in practice. In addition, high-quality recovery remains difficult as part of the local residual information in corrupted frames may mislead feature completion and successive content recovery. In this paper, we propose the first blind bitstream-corrupted video recovery framework that integrates visual foundation models with a recovery model, which is adapted to different types of corruption and bitstream-level prompts. Within the framework, the proposed Detect Any Corruption (DAC) model leverages the rich priors of the visual foundation model while incorporating bitstream and corruption knowledge to enhance corruption localization and blind recovery. Additionally, we introduce a novel Corruption-aware Feature Completion (CFC) module, which adaptively processes residual contributions based on high-level corruption understanding. With VFM-guided hierarchical feature augmentation and high-level coordination in a mixture-of-residual-experts (MoRE) structure, our method suppresses artifacts and enhances informative residuals. Comprehensive evaluations show that the proposed method achieves outstanding performance in bitstream-corrupted video recovery without requiring a manually labeled mask sequence. The demonstrated effectiveness will help to realize improved user experience, wider application scenarios, and more reliable multimedia communication and storage systems.
ByteNet: Rethinking Multimedia File Fragment Classification through Visual Perspectives
Oct 28, 2024Multimedia file fragment classification (MFFC) aims to identify file fragment types, e.g., image/video, audio, and text without system metadata. It is of vital importance in multimedia storage and communication. Existing MFFC methods typically treat fragments as 1D byte sequences and emphasize the relations between separate bytes (interbytes) for classification. However, the more informative relations inside bytes (intrabytes) are overlooked and seldom investigated. By looking inside bytes, the bit-level details of file fragments can be accessed, enabling a more accurate classification. Motivated by this, we first propose Byte2Image, a novel visual representation model that incorporates previously overlooked intrabyte information into file fragments and reinterprets these fragments as 2D grayscale images. This model involves a sliding byte window to reveal the intrabyte information and a rowwise stacking of intrabyte ngrams for embedding fragments into a 2D space. Thus, complex interbyte and intrabyte correlations can be mined simultaneously using powerful vision networks. Additionally, we propose an end-to-end dual-branch network ByteNet to enhance robust correlation mining and feature representation. ByteNet makes full use of the raw 1D byte sequence and the converted 2D image through a shallow byte branch feature extraction (BBFE) and a deep image branch feature extraction (IBFE) network. In particular, the BBFE, composed of a single fully-connected layer, adaptively recognizes the co-occurrence of several some specific bytes within the raw byte sequence, while the IBFE, built on a vision Transformer, effectively mines the complex interbyte and intrabyte correlations from the converted image. Experiments on the two representative benchmarks, including 14 cases, validate that our proposed method outperforms state-of-the-art approaches on different cases by up to 12.2%.
Extending Depth of Field for Varifocal Multiview Images
Sep 28, 2024Optical imaging systems are generally limited by the depth of field because of the nature of the optics. Therefore, extending depth of field (EDoF) is a fundamental task for meeting the requirements of emerging visual applications. To solve this task, the common practice is using multi-focus images from a single viewpoint. This method can obtain acceptable quality of EDoF under the condition of fixed field of view, but it is only applicable to static scenes and the field of view is limited and fixed. An emerging data type, varifocal multiview images have the potential to become a new paradigm for solving the EDoF, because the data contains more field of view information than multi-focus images. To realize EDoF of varifocal multiview images, we propose an end-to-end method for the EDoF, including image alignment, image optimization and image fusion. Experimental results demonstrate the efficiency of the proposed method.
Video sentence grounding with temporally global textual knowledge
Apr 21, 2024Temporal sentence grounding involves the retrieval of a video moment with a natural language query. Many existing works directly incorporate the given video and temporally localized query for temporal grounding, overlooking the inherent domain gap between different modalities. In this paper, we utilize pseudo-query features containing extensive temporally global textual knowledge sourced from the same video-query pair, to enhance the bridging of domain gaps and attain a heightened level of similarity between multi-modal features. Specifically, we propose a Pseudo-query Intermediary Network (PIN) to achieve an improved alignment of visual and comprehensive pseudo-query features within the feature space through contrastive learning. Subsequently, we utilize learnable prompts to encapsulate the knowledge of pseudo-queries, propagating them into the textual encoder and multi-modal fusion module, further enhancing the feature alignment between visual and language for better temporal grounding. Extensive experiments conducted on the Charades-STA and ActivityNet-Captions datasets demonstrate the effectiveness of our method.
Bitstream-Corrupted Video Recovery: A Novel Benchmark Dataset and Method
Sep 26, 2023The past decade has witnessed great strides in video recovery by specialist technologies, like video inpainting, completion, and error concealment. However, they typically simulate the missing content by manual-designed error masks, thus failing to fill in the realistic video loss in video communication (e.g., telepresence, live streaming, and internet video) and multimedia forensics. To address this, we introduce the bitstream-corrupted video (BSCV) benchmark, the first benchmark dataset with more than 28,000 video clips, which can be used for bitstream-corrupted video recovery in the real world. The BSCV is a collection of 1) a proposed three-parameter corruption model for video bitstream, 2) a large-scale dataset containing rich error patterns, multiple corruption levels, and flexible dataset branches, and 3) a plug-and-play module in video recovery framework that serves as a benchmark. We evaluate state-of-the-art video inpainting methods on the BSCV dataset, demonstrating existing approaches' limitations and our framework's advantages in solving the bitstream-corrupted video recovery problem. The benchmark and dataset are released at https://github.com/LIUTIGHE/BSCV-Dataset.
A Byte Sequence is Worth an Image: CNN for File Fragment Classification Using Bit Shift and n-Gram Embeddings
Apr 14, 2023File fragment classification (FFC) on small chunks of memory is essential in memory forensics and Internet security. Existing methods mainly treat file fragments as 1d byte signals and utilize the captured inter-byte features for classification, while the bit information within bytes, i.e., intra-byte information, is seldom considered. This is inherently inapt for classifying variable-length coding files whose symbols are represented as the variable number of bits. Conversely, we propose Byte2Image, a novel data augmentation technique, to introduce the neglected intra-byte information into file fragments and re-treat them as 2d gray-scale images, which allows us to capture both inter-byte and intra-byte correlations simultaneously through powerful convolutional neural networks (CNNs). Specifically, to convert file fragments to 2d images, we employ a sliding byte window to expose the neglected intra-byte information and stack their n-gram features row by row. We further propose a byte sequence \& image fusion network as a classifier, which can jointly model the raw 1d byte sequence and the converted 2d image to perform FFC. Experiments on FFT-75 dataset validate that our proposed method can achieve notable accuracy improvements over state-of-the-art methods in nearly all scenarios. The code will be released at https://github.com/wenyang001/Byte2Image.
Varifocal Multiview Images: Capturing and Visual Tasks
Nov 19, 2021
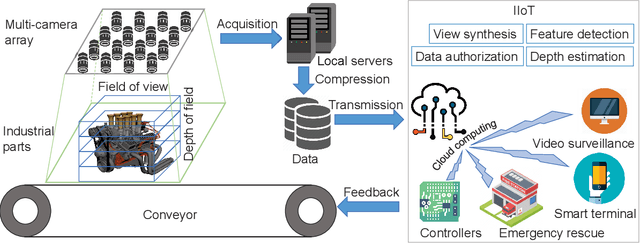


Multiview images have flexible field of view (FoV) but inflexible depth of field (DoF). To overcome the limitation of multiview images on visual tasks, in this paper, we present varifocal multiview (VFMV) images with flexible DoF. VFMV images are captured by focusing a scene on distinct depths by varying focal planes, and each view only focused on one single plane.Therefore, VFMV images contain more information in focal dimension than multiview images, and can provide a rich representation for 3D scene by considering both FoV and DoF. The characteristics of VFMV images are useful for visual tasks to achieve high quality scene representation. Two experiments are conducted to validate the advantages of VFMV images in 4D light field feature detection and 3D reconstruction. Experiment results show that VFMV images can detect more light field features and achieve higher reconstruction quality due to informative focus cues. This work demonstrates that VFMV images have definite advantages over multiview images in visual tasks.