 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCI-ICM: Channel Importance-driven Learned Image Coding for Machines
Apr 07, 2026Traditional human vision-centric image compression methods are suboptimal for machine vision centric compression due to different visual properties and feature characteristics. To address this problem, we propose a Channel Importance-driven learned Image Coding for Machines (CI-ICM), aiming to maximize the performance of machine vision tasks at a given bitrate constraint. First, we propose a Channel Importance Generation (CIG) module to quantify channel importance in machine vision and develop a channel order loss to rank channels in descending order. Second, to properly allocate bitrate among feature channels, we propose a Feature Channel Grouping and Scaling (FCGS) module that non-uniformly groups the feature channels based on their importance and adjusts the dynamic range of each group. Based on FCGS, we further propose a Channel Importance-based Context (CI-CTX) module to allocate bits among feature groups and to preserve higher fidelity in critical channels. Third, to adapt to multiple machine tasks, we propose a Task-Specific Channel Adaptation (TSCA) module to adaptively enhance features for multiple downstream machine tasks. Experimental results on the COCO2017 dataset show that the proposed CI-ICM achieves BD-mAP@50:95 gains of 16.25$\%$ in object detection and 13.72$\%$ in instance segmentation over the established baseline codec. Ablation studies validate the effectiveness of each contribution, and computation complexity analysis reveals the practicability of the CI-ICM. This work establishes feature channel optimization for machine vision-centric compression, bridging the gap between image coding and machine perception.
WaterMamba: Visual State Space Model for Underwater Image Enhancement
May 14, 2024Underwater imaging often suffers from low quality due to factors affecting light propagation and absorption in water. To improve image quality, some underwater image enhancement (UIE) methods based on convolutional neural networks (CNN) and Transformer have been proposed. However, CNN-based UIE methods are limited in modeling long-range dependencies, and Transformer-based methods involve a large number of parameters and complex self-attention mechanisms, posing efficiency challenges. Considering computational complexity and severe underwater image degradation, a state space model (SSM) with linear computational complexity for UIE, named WaterMamba, is proposed. We propose spatial-channel omnidirectional selective scan (SCOSS) blocks comprising spatial-channel coordinate omnidirectional selective scan (SCCOSS) modules and a multi-scale feedforward network (MSFFN). The SCOSS block models pixel and channel information flow, addressing dependencies. The MSFFN facilitates information flow adjustment and promotes synchronized operations within SCCOSS modules. Extensive experiments showcase WaterMamba's cutting-edge performance with reduced parameters and computational resources, outperforming state-of-the-art methods on various datasets, validating its effectiveness and generalizability. The code will be released on GitHub after acceptance.
Reinforced Swin-Convs Transformer for Underwater Image Enhancement
May 01, 2022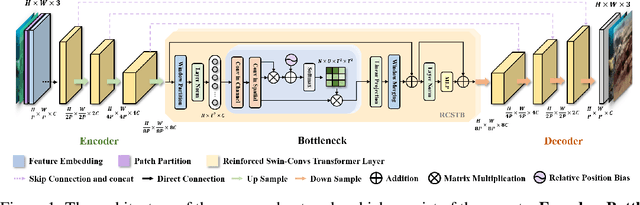
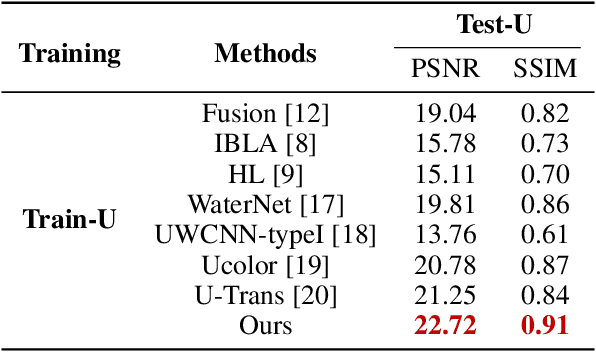
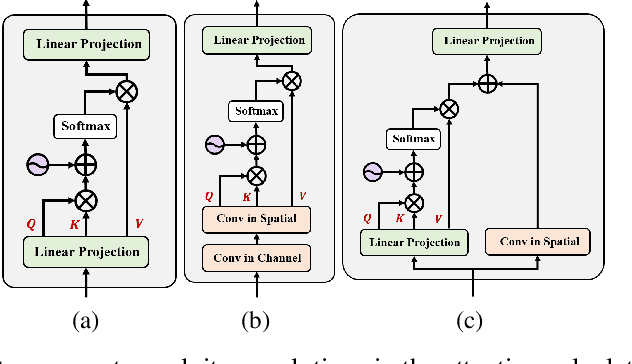
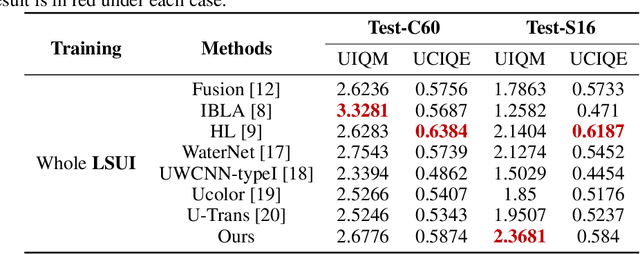
Underwater Image Enhancement (UIE) technology aims to tackle the challenge of restoring the degraded underwater images due to light absorption and scattering. To address problems, a novel U-Net based Reinforced Swin-Convs Transformer for the Underwater Image Enhancement method (URSCT-UIE) is proposed. Specifically, with the deficiency of U-Net based on pure convolutions, we embedded the Swin Transformer into U-Net for improving the ability to capture the global dependency. Then, given the inadequacy of the Swin Transformer capturing the local attention, the reintroduction of convolutions may capture more local attention. Thus, we provide an ingenious manner for the fusion of convolutions and the core attention mechanism to build a Reinforced Swin-Convs Transformer Block (RSCTB) for capturing more local attention, which is reinforced in the channel and the spatial attention of the Swin Transformer. Finally, the experimental results on available datasets demonstrate that the proposed URSCT-UIE achieves state-of-the-art performance compared with other methods in terms of both subjective and objective evaluations. The code will be released on GitHub after acceptance.
Deep Learning-Based Intra Mode Derivation for Versatile Video Coding
Apr 08, 2022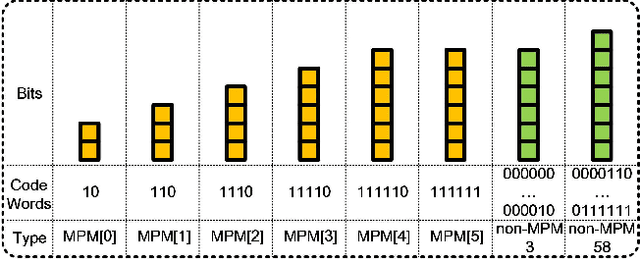
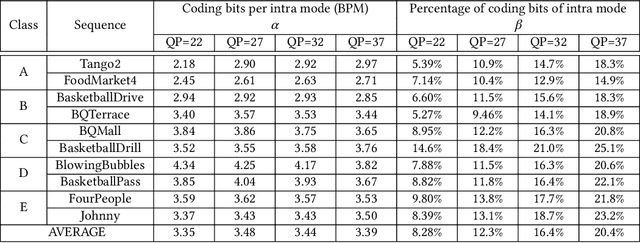
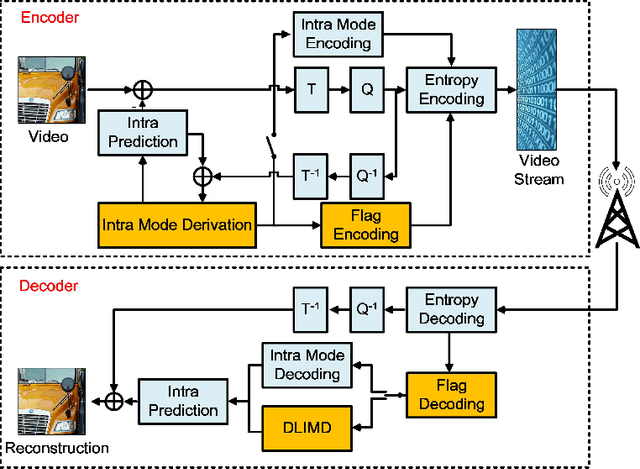
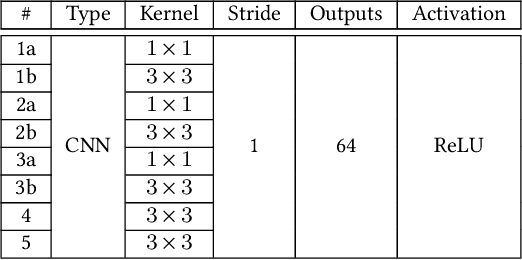
In intra coding, Rate Distortion Optimization (RDO) is performed to achieve the optimal intra mode from a pre-defined candidate list. The optimal intra mode is also required to be encoded and transmitted to the decoder side besides the residual signal, where lots of coding bits are consumed. To further improve the performance of intra coding in Versatile Video Coding (VVC), an intelligent intra mode derivation method is proposed in this paper, termed as Deep Learning based Intra Mode Derivation (DLIMD). In specific, the process of intra mode derivation is formulated as a multi-class classification task, which aims to skip the module of intra mode signaling for coding bits reduction. The architecture of DLIMD is developed to adapt to different quantization parameter settings and variable coding blocks including non-square ones, which are handled by one single trained model. Different from the existing deep learning based classification problems, the hand-crafted features are also fed into the intra mode derivation network besides the learned features from feature learning network. To compete with traditional method, one additional binary flag is utilized in the video codec to indicate the selected scheme with RDO. Extensive experimental results reveal that the proposed method can achieve 2.28%, 1.74%, and 2.18% bit rate reduction on average for Y, U, and V components on the platform of VVC test model, which outperforms the state-of-the-art works.
A Survey on Perceptually Optimized Video Coding
Dec 23, 2021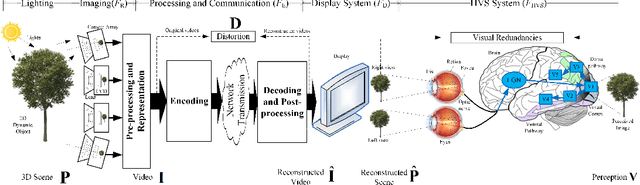
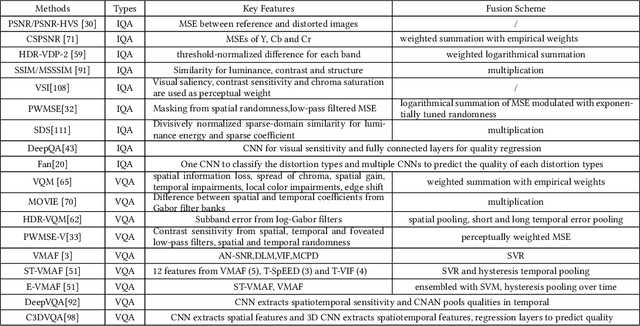
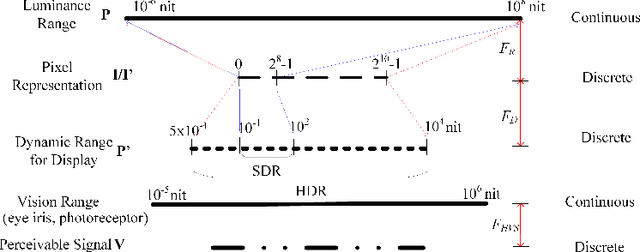
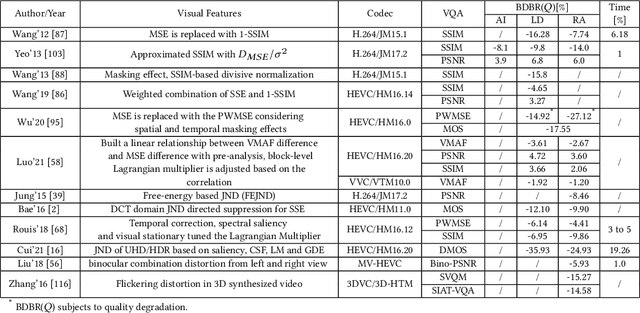
Videos are developing in the trends of Ultra High Definition (UHD), High Frame Rate (HFR), High Dynamic Range (HDR), Wide Color Gammut (WCG) and high fidelity, which provide users with more realistic visual experiences. However, the amount of video data increases exponentially and requires high efficiency video compression for storage and network transmission. Perceptually optimized video coding aims to exploit visual redundancies in videos so as to maximize compression efficiency. In this paper, we present a systematic survey on the recent advances and challenges on perceptually optimized video coding. Firstly, we present problem formulation and framework of perceptually optimized video coding, which includes visual perception modelling, visual quality assessment and perception guided coding optimization. Secondly, the recent advances on visual factors, key computational visual models and quality assessment models are presented. Thirdly, we do systematic review on perceptual video coding optimizations from four key aspects, which includes perceptually optimized bit allocation, rate-distortion optimization, transform and quantization, filtering and enhancement. In each part, problem formulation, working flow, recent advances, advantages and challenges are presented. Fourthly, perceptual coding performance of latest coding standards and tools are experimentally analyzed. Finally, challenging issues and future opportunities on perceptual video coding are identified.
Varifocal Multiview Images: Capturing and Visual Tasks
Nov 19, 2021
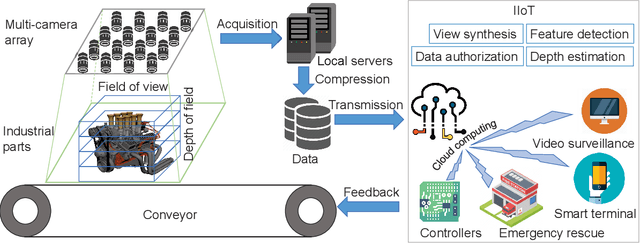


Multiview images have flexible field of view (FoV) but inflexible depth of field (DoF). To overcome the limitation of multiview images on visual tasks, in this paper, we present varifocal multiview (VFMV) images with flexible DoF. VFMV images are captured by focusing a scene on distinct depths by varying focal planes, and each view only focused on one single plane.Therefore, VFMV images contain more information in focal dimension than multiview images, and can provide a rich representation for 3D scene by considering both FoV and DoF. The characteristics of VFMV images are useful for visual tasks to achieve high quality scene representation. Two experiments are conducted to validate the advantages of VFMV images in 4D light field feature detection and 3D reconstruction. Experiment results show that VFMV images can detect more light field features and achieve higher reconstruction quality due to informative focus cues. This work demonstrates that VFMV images have definite advantages over multiview images in visual tasks.