 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPCB: A Generation-Assisted Detection Framework for PCB Defect Inspection
May 06, 2026Printed Circuit Board (PCB) defect inspection faces two compounding challenges: scarce and imbalanced defect samples that limit model training, and insufficient feature representation under complex circuit backgrounds. Existing generation methods rely on single-modality conditions with coarse structural control, while detection methods improve architectures without addressing the data bottleneck. To resolve both challenges jointly, we propose a generation-assisted PCB defect inspection framework that integrates controlled defect synthesis with task-specific defect detection. On the generation side, a Multi-modal Condition Generator extracts complementary edge, depth, and text conditions in parallel. A ScaleEncoder then embeds these conditions into the diffusion U-Net at four resolutions, and a Condition Modulation applies FiLM-style spatially-adaptive modulation at each scale, enabling structurally aligned and defect-aware sample synthesis. On the detection side, an Inverted Residual Shift Attention couples self-attention with shift-wise convolution to jointly capture global context and local texture, and a Cross-level Complementary Fusion Block generates pixel-level gates for selective cross-level feature fusion. The synthesized samples directly enrich the detection training set, so that improvements in generation compound with improvements in detection. Extensive experiments on DsPCBSD+ demonstrate that UniPCB achieves mAP@0.5 of 98.0% and mAP@0.5:0.95 of 61.8% on defect detection, surpassing all compared methods, while the generation branch attains an FID of 129.61 and SSIM of 0.619, outperforming existing conditional generation approaches.
Deep-JGAC: End-to-End Deep Joint Geometry and Attribute Compression for Dense Colored Point Clouds
Feb 25, 2025Colored point cloud becomes a fundamental representation in the realm of 3D vision. Effective Point Cloud Compression (PCC) is urgently needed due to huge amount of data. In this paper, we propose an end-to-end Deep Joint Geometry and Attribute point cloud Compression (Deep-JGAC) framework for dense colored point clouds, which exploits the correlation between the geometry and attribute for high compression efficiency. Firstly, we propose a flexible Deep-JGAC framework, where the geometry and attribute sub-encoders are compatible to either learning or non-learning based geometry and attribute encoders. Secondly, we propose an attribute-assisted deep geometry encoder that enhances the geometry latent representation with the help of attribute, where the geometry decoding remains unchanged. Moreover, Attribute Information Fusion Module (AIFM) is proposed to fuse attribute information in geometry coding. Thirdly, to solve the mismatch between the point cloud geometry and attribute caused by the geometry compression distortion, we present an optimized re-colorization module to attach the attribute to the geometrically distorted point cloud for attribute coding. It enhances the colorization and lowers the computational complexity. Extensive experimental results demonstrate that in terms of the geometry quality metric D1-PSNR, the proposed Deep-JGAC achieves an average of 82.96%, 36.46%, 41.72%, and 31.16% bit-rate reductions as compared to the state-of-the-art G-PCC, V-PCC, GRASP, and PCGCv2, respectively. In terms of perceptual joint quality metric MS-GraphSIM, the proposed Deep-JGAC achieves an average of 48.72%, 14.67%, and 57.14% bit-rate reductions compared to the G-PCC, V-PCC, and IT-DL-PCC, respectively. The encoding/decoding time costs are also reduced by 94.29%/24.70%, and 96.75%/91.02% on average as compared with the V-PCC and IT-DL-PCC.
LFIC-DRASC: Deep Light Field Image Compression Using Disentangled Representation and Asymmetrical Strip Convolution
Sep 18, 2024



Light-Field (LF) image is emerging 4D data of light rays that is capable of realistically presenting spatial and angular information of 3D scene. However, the large data volume of LF images becomes the most challenging issue in real-time processing, transmission, and storage. In this paper, we propose an end-to-end deep LF Image Compression method Using Disentangled Representation and Asymmetrical Strip Convolution (LFIC-DRASC) to improve coding efficiency. Firstly, we formulate the LF image compression problem as learning a disentangled LF representation network and an image encoding-decoding network. Secondly, we propose two novel feature extractors that leverage the structural prior of LF data by integrating features across different dimensions. Meanwhile, disentangled LF representation network is proposed to enhance the LF feature disentangling and decoupling. Thirdly, we propose the LFIC-DRASC for LF image compression, where two Asymmetrical Strip Convolution (ASC) operators, i.e. horizontal and vertical, are proposed to capture long-range correlation in LF feature space. These two ASC operators can be combined with the square convolution to further decouple LF features, which enhances the model ability in representing intricate spatial relationships. Experimental results demonstrate that the proposed LFIC-DRASC achieves an average of 20.5\% bit rate reductions comparing with the state-of-the-art methods.
Deep Learning-Based Intra Mode Derivation for Versatile Video Coding
Apr 08, 2022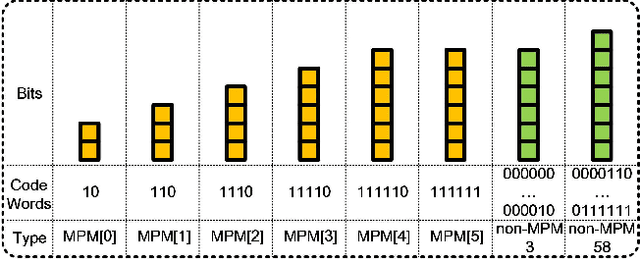
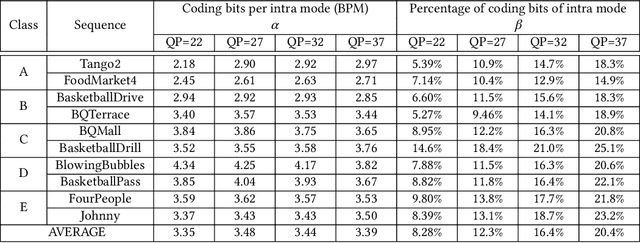
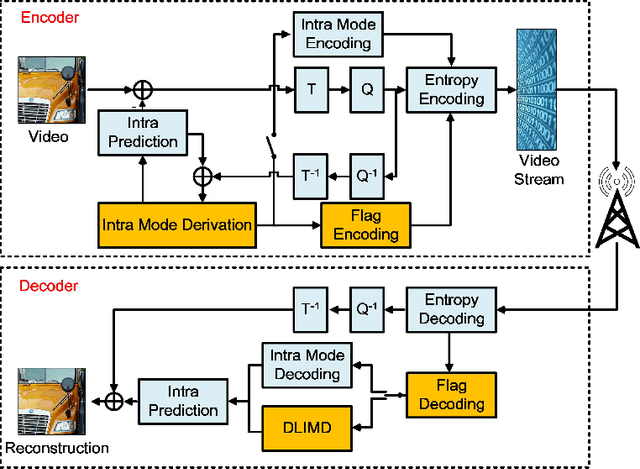
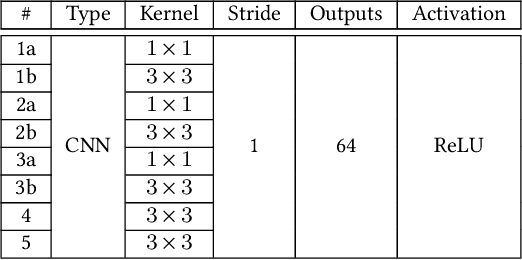
In intra coding, Rate Distortion Optimization (RDO) is performed to achieve the optimal intra mode from a pre-defined candidate list. The optimal intra mode is also required to be encoded and transmitted to the decoder side besides the residual signal, where lots of coding bits are consumed. To further improve the performance of intra coding in Versatile Video Coding (VVC), an intelligent intra mode derivation method is proposed in this paper, termed as Deep Learning based Intra Mode Derivation (DLIMD). In specific, the process of intra mode derivation is formulated as a multi-class classification task, which aims to skip the module of intra mode signaling for coding bits reduction. The architecture of DLIMD is developed to adapt to different quantization parameter settings and variable coding blocks including non-square ones, which are handled by one single trained model. Different from the existing deep learning based classification problems, the hand-crafted features are also fed into the intra mode derivation network besides the learned features from feature learning network. To compete with traditional method, one additional binary flag is utilized in the video codec to indicate the selected scheme with RDO. Extensive experimental results reveal that the proposed method can achieve 2.28%, 1.74%, and 2.18% bit rate reduction on average for Y, U, and V components on the platform of VVC test model, which outperforms the state-of-the-art works.
Distortion-Aware Loop Filtering of Intra 360^o Video Coding with Equirectangular Projection
Feb 20, 2022
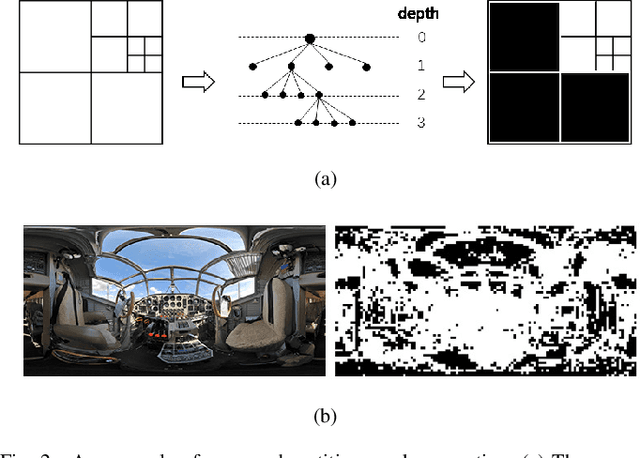
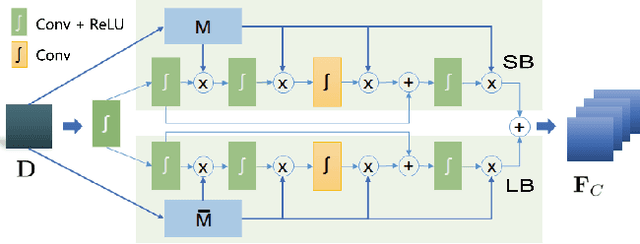
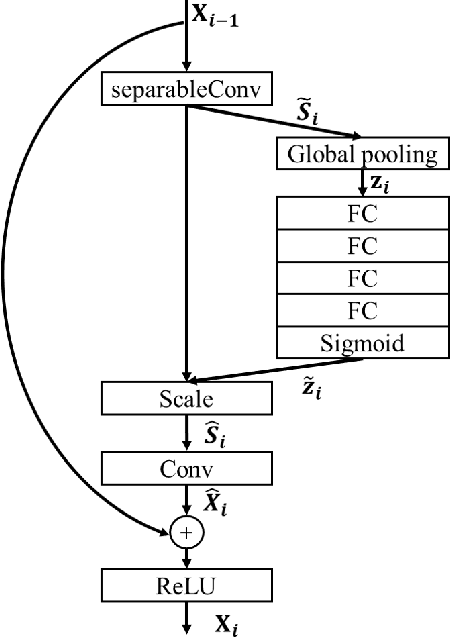
In this paper, we propose a distortion-aware loop filtering model to improve the performance of intra coding for 360$^o$ videos projected via equirectangular projection (ERP) format. To enable the awareness of distortion, our proposed module analyzes content characteristics based on a coding unit (CU) partition mask and processes them through partial convolution to activate the specified area. The feature recalibration module, which leverages cascaded residual channel-wise attention blocks (RCABs) to adjust the inter-channel and intra-channel features automatically, is capable of adapting with different quality levels. The perceptual geometry optimization combining with weighted mean squared error (WMSE) and the perceptual loss guarantees both the local field of view (FoV) and global image reconstruction with high quality. Extensive experimental results show that our proposed scheme achieves significant bitrate savings compared with the anchor (HM + 360Lib), leading to 8.9%, 9.0%, 7.1% and 7.4% on average bit rate reductions in terms of PSNR, WPSNR, and PSNR of two viewports for luminance component of 360^o videos, respectively.
A Survey on Perceptually Optimized Video Coding
Dec 23, 2021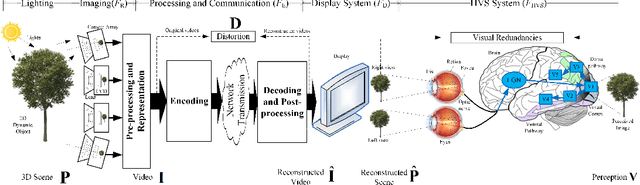
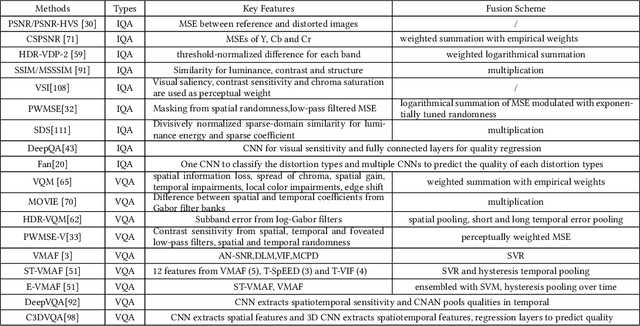
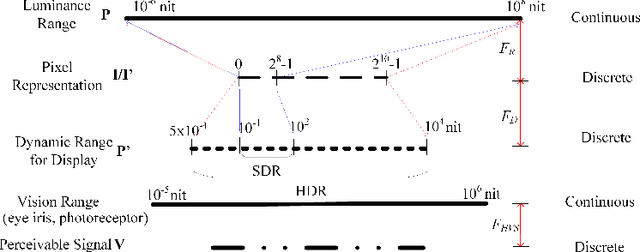
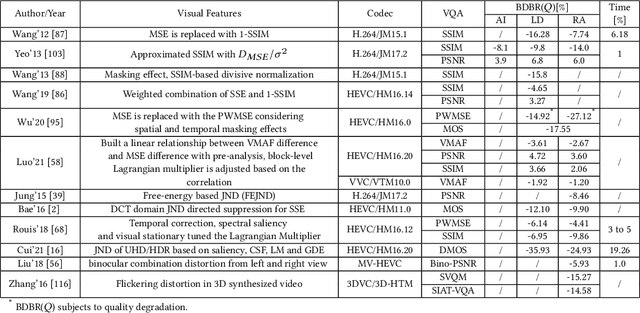
Videos are developing in the trends of Ultra High Definition (UHD), High Frame Rate (HFR), High Dynamic Range (HDR), Wide Color Gammut (WCG) and high fidelity, which provide users with more realistic visual experiences. However, the amount of video data increases exponentially and requires high efficiency video compression for storage and network transmission. Perceptually optimized video coding aims to exploit visual redundancies in videos so as to maximize compression efficiency. In this paper, we present a systematic survey on the recent advances and challenges on perceptually optimized video coding. Firstly, we present problem formulation and framework of perceptually optimized video coding, which includes visual perception modelling, visual quality assessment and perception guided coding optimization. Secondly, the recent advances on visual factors, key computational visual models and quality assessment models are presented. Thirdly, we do systematic review on perceptual video coding optimizations from four key aspects, which includes perceptually optimized bit allocation, rate-distortion optimization, transform and quantization, filtering and enhancement. In each part, problem formulation, working flow, recent advances, advantages and challenges are presented. Fourthly, perceptual coding performance of latest coding standards and tools are experimentally analyzed. Finally, challenging issues and future opportunities on perceptual video coding are identified.
Towards Modality Transferable Visual Information Representation with Optimal Model Compression
Aug 13, 2020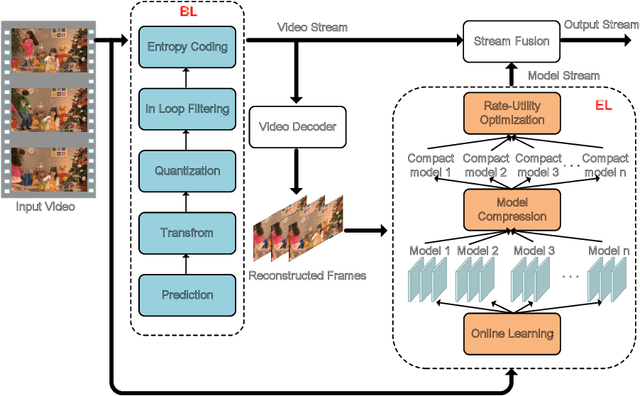

Compactly representing the visual signals is of fundamental importance in various image/video-centered applications. Although numerous approaches were developed for improving the image and video coding performance by removing the redundancies within visual signals, much less work has been dedicated to the transformation of the visual signals to another well-established modality for better representation capability. In this paper, we propose a new scheme for visual signal representation that leverages the philosophy of transferable modality. In particular, the deep learning model, which characterizes and absorbs the statistics of the input scene with online training, could be efficiently represented in the sense of rate-utility optimization to serve as the enhancement layer in the bitstream. As such, the overall performance can be further guaranteed by optimizing the new modality incorporated. The proposed framework is implemented on the state-of-the-art video coding standard (i.e., versatile video coding), and significantly better representation capability has been observed based on extensive evaluations.