 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Feature Importance-based Bit Allocation for End-to-End Feature Coding for Machines
Mar 25, 2025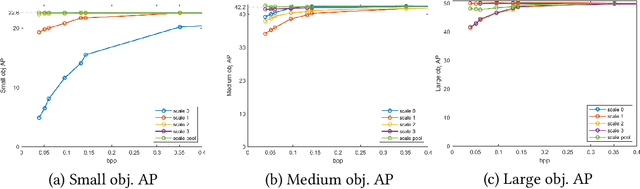

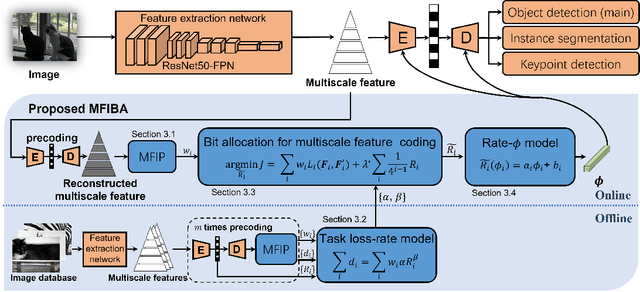

Feature Coding for Machines (FCM) aims to compress intermediate features effectively for remote intelligent analytics, which is crucial for future intelligent visual applications. In this paper, we propose a Multiscale Feature Importance-based Bit Allocation (MFIBA) for end-to-end FCM. First, we find that the importance of features for machine vision tasks varies with the scales, object size, and image instances. Based on this finding, we propose a Multiscale Feature Importance Prediction (MFIP) module to predict the importance weight for each scale of features. Secondly, we propose a task loss-rate model to establish the relationship between the task accuracy losses of using compressed features and the bitrate of encoding these features. Finally, we develop a MFIBA for end-to-end FCM, which is able to assign coding bits of multiscale features more reasonably based on their importance. Experimental results demonstrate that when combined with a retained Efficient Learned Image Compression (ELIC), the proposed MFIBA achieves an average of 38.202% bitrate savings in object detection compared to the anchor ELIC. Moreover, the proposed MFIBA achieves an average of 17.212% and 36.492% feature bitrate savings for instance segmentation and keypoint detection, respectively. When the proposed MFIBA is applied to the LIC-TCM, it achieves an average of 18.103%, 19.866% and 19.597% bit rate savings on three machine vision tasks, respectively, which validates the proposed MFIBA has good generalizability and adaptability to different machine vision tasks and FCM base codecs.
Deep-JGAC: End-to-End Deep Joint Geometry and Attribute Compression for Dense Colored Point Clouds
Feb 25, 2025Colored point cloud becomes a fundamental representation in the realm of 3D vision. Effective Point Cloud Compression (PCC) is urgently needed due to huge amount of data. In this paper, we propose an end-to-end Deep Joint Geometry and Attribute point cloud Compression (Deep-JGAC) framework for dense colored point clouds, which exploits the correlation between the geometry and attribute for high compression efficiency. Firstly, we propose a flexible Deep-JGAC framework, where the geometry and attribute sub-encoders are compatible to either learning or non-learning based geometry and attribute encoders. Secondly, we propose an attribute-assisted deep geometry encoder that enhances the geometry latent representation with the help of attribute, where the geometry decoding remains unchanged. Moreover, Attribute Information Fusion Module (AIFM) is proposed to fuse attribute information in geometry coding. Thirdly, to solve the mismatch between the point cloud geometry and attribute caused by the geometry compression distortion, we present an optimized re-colorization module to attach the attribute to the geometrically distorted point cloud for attribute coding. It enhances the colorization and lowers the computational complexity. Extensive experimental results demonstrate that in terms of the geometry quality metric D1-PSNR, the proposed Deep-JGAC achieves an average of 82.96%, 36.46%, 41.72%, and 31.16% bit-rate reductions as compared to the state-of-the-art G-PCC, V-PCC, GRASP, and PCGCv2, respectively. In terms of perceptual joint quality metric MS-GraphSIM, the proposed Deep-JGAC achieves an average of 48.72%, 14.67%, and 57.14% bit-rate reductions compared to the G-PCC, V-PCC, and IT-DL-PCC, respectively. The encoding/decoding time costs are also reduced by 94.29%/24.70%, and 96.75%/91.02% on average as compared with the V-PCC and IT-DL-PCC.