 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEraW-Net: Enhance-Refine-Align W-Net for Scene-Associated Driver Attention Estimation
Aug 16, 2024
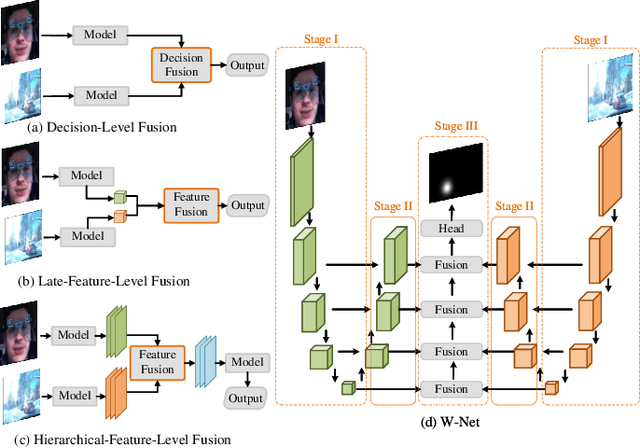
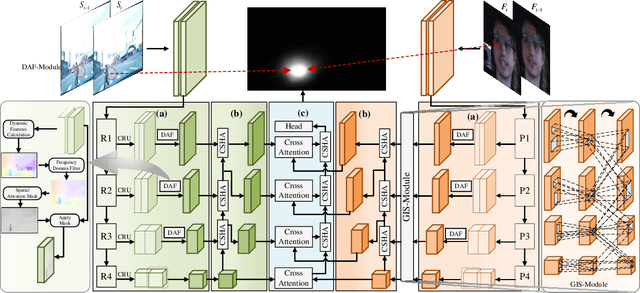
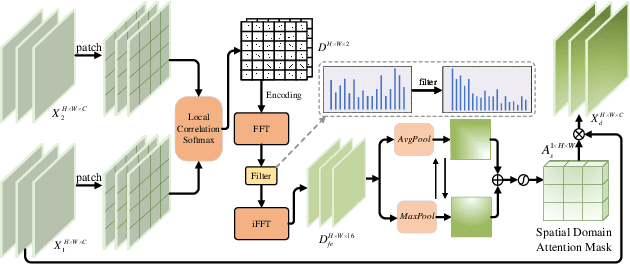
Associating driver attention with driving scene across two fields of views (FOVs) is a hard cross-domain perception problem, which requires comprehensive consideration of cross-view mapping, dynamic driving scene analysis, and driver status tracking. Previous methods typically focus on a single view or map attention to the scene via estimated gaze, failing to exploit the implicit connection between them. Moreover, simple fusion modules are insufficient for modeling the complex relationships between the two views, making information integration challenging. To address these issues, we propose a novel method for end-to-end scene-associated driver attention estimation, called EraW-Net. This method enhances the most discriminative dynamic cues, refines feature representations, and facilitates semantically aligned cross-domain integration through a W-shaped architecture, termed W-Net. Specifically, a Dynamic Adaptive Filter Module (DAF-Module) is proposed to address the challenges of frequently changing driving environments by extracting vital regions. It suppresses the indiscriminately recorded dynamics and highlights crucial ones by innovative joint frequency-spatial analysis, enhancing the model's ability to parse complex dynamics. Additionally, to track driver states during non-fixed facial poses, we propose a Global Context Sharing Module (GCS-Module) to construct refined feature representations by capturing hierarchical features that adapt to various scales of head and eye movements. Finally, W-Net achieves systematic cross-view information integration through its "Encoding-Independent Partial Decoding-Fusion Decoding" structure, addressing semantic misalignment in heterogeneous data integration. Experiments demonstrate that the proposed method robustly and accurately estimates the mapping of driver attention in scene on large public datasets.