 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDressing Avatars: Deep Photorealistic Appearance for Physically Simulated Clothing
Jun 30, 2022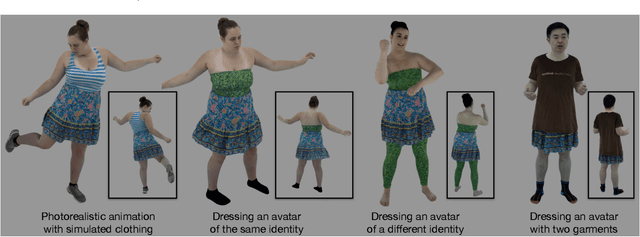
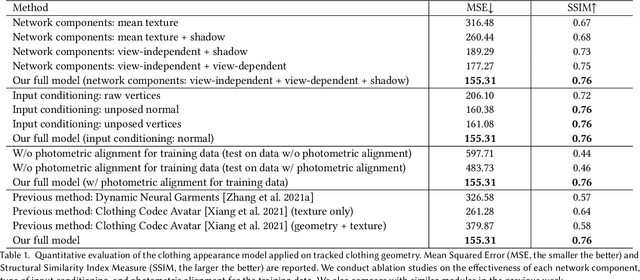
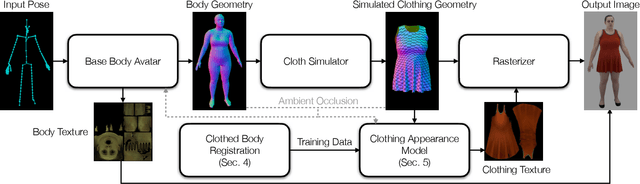
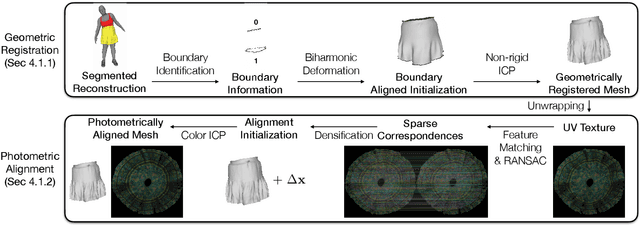
Despite recent progress in developing animatable full-body avatars, realistic modeling of clothing - one of the core aspects of human self-expression - remains an open challenge. State-of-the-art physical simulation methods can generate realistically behaving clothing geometry at interactive rate. Modeling photorealistic appearance, however, usually requires physically-based rendering which is too expensive for interactive applications. On the other hand, data-driven deep appearance models are capable of efficiently producing realistic appearance, but struggle at synthesizing geometry of highly dynamic clothing and handling challenging body-clothing configurations. To this end, we introduce pose-driven avatars with explicit modeling of clothing that exhibit both realistic clothing dynamics and photorealistic appearance learned from real-world data. The key idea is to introduce a neural clothing appearance model that operates on top of explicit geometry: at train time we use high-fidelity tracking, whereas at animation time we rely on physically simulated geometry. Our key contribution is a physically-inspired appearance network, capable of generating photorealistic appearance with view-dependent and dynamic shadowing effects even for unseen body-clothing configurations. We conduct a thorough evaluation of our model and demonstrate diverse animation results on several subjects and different types of clothing. Unlike previous work on photorealistic full-body avatars, our approach can produce much richer dynamics and more realistic deformations even for loose clothing. We also demonstrate that our formulation naturally allows clothing to be used with avatars of different people while staying fully animatable, thus enabling, for the first time, photorealistic avatars with novel clothing.
Active Learning of Neural Collision Handler for Complex 3D Mesh Deformations
Oct 08, 2021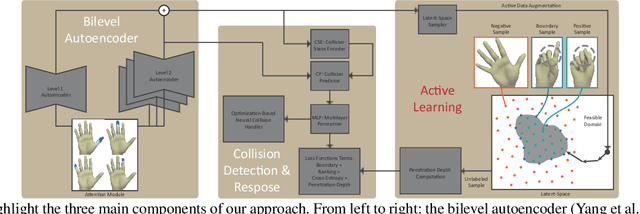
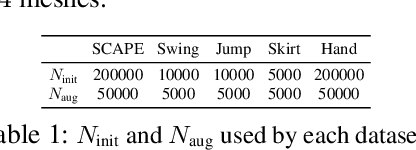
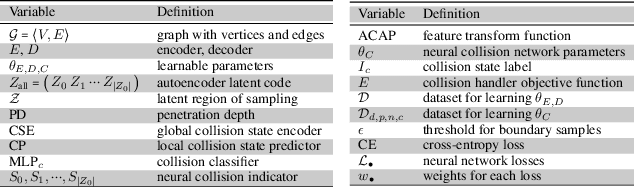
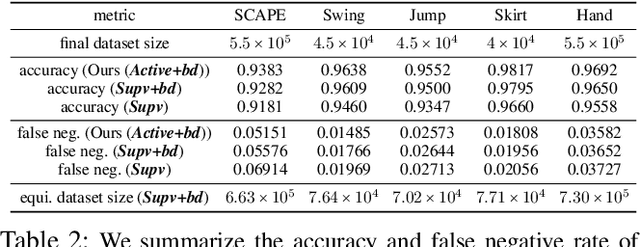
We present a robust learning algorithm to detect and handle collisions in 3D deforming meshes. Our collision detector is represented as a bilevel deep autoencoder with an attention mechanism that identifies colliding mesh sub-parts. We use a numerical optimization algorithm to resolve penetrations guided by the network. Our learned collision handler can resolve collisions for unseen, high-dimensional meshes with thousands of vertices. To obtain stable network performance in such large and unseen spaces, we progressively insert new collision data based on the errors in network inferences. We automatically label these data using an analytical collision detector and progressively fine-tune our detection networks. We evaluate our method for collision handling of complex, 3D meshes coming from several datasets with different shapes and topologies, including datasets corresponding to dressed and undressed human poses, cloth simulations, and human hand poses acquired using multiview capture systems. Our approach outperforms supervised learning methods and achieves $93.8-98.1\%$ accuracy compared to the groundtruth by analytic methods. Compared to prior learning methods, our approach results in a $5.16\%-25.50\%$ lower false negative rate in terms of collision checking and a $9.65\%-58.91\%$ higher success rate in collision handling.