 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
Dec 09, 2024Recent advances in learning decision-making policies can largely be attributed to training expressive policy models, largely via imitation learning. While imitation learning discards non-expert data, reinforcement learning (RL) can still learn from suboptimal data. However, instantiating RL training of a new policy class often presents a different challenge: most deep RL machinery is co-developed with assumptions on the policy class and backbone, resulting in poor performance when the policy class changes. For instance, SAC utilizes a low-variance reparameterization policy gradient for Gaussian policies, but this is unstable for diffusion policies and intractable for autoregressive categorical policies. To address this issue, we develop an offline RL and online fine-tuning approach called policy-agnostic RL (PA-RL) that can effectively train multiple policy classes, with varying architectures and sizes. We build off the basic idea that a universal supervised learning loss can replace the policy improvement step in RL, as long as it is applied on "optimized" actions. To obtain these optimized actions, we first sample multiple actions from a base policy, and run global optimization (i.e., re-ranking multiple action samples using the Q-function) and local optimization (i.e., running gradient steps on an action sample) to maximize the critic on these candidates. PA-RL enables fine-tuning diffusion and transformer policies with either autoregressive tokens or continuous action outputs, at different sizes, entirely via actor-critic RL. Moreover, PA-RL improves the performance and sample-efficiency by up to 2 times compared to existing offline RL and online fine-tuning methods. We show the first result that successfully fine-tunes OpenVLA, a 7B generalist robot policy, autonomously with Cal-QL, an online RL fine-tuning algorithm, improving from 40% to 70% in the real world in 40 minutes.
TypeScore: A Text Fidelity Metric for Text-to-Image Generative Models
Nov 02, 2024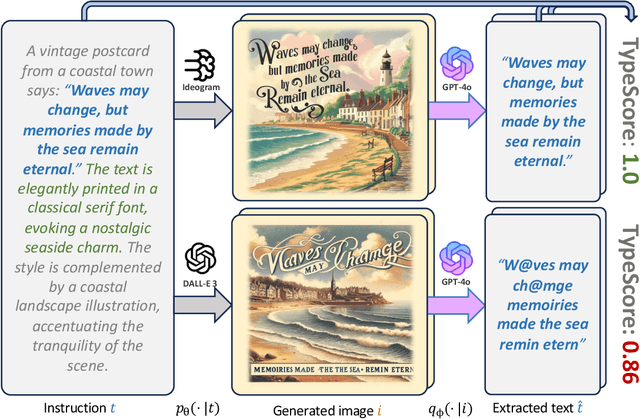



Evaluating text-to-image generative models remains a challenge, despite the remarkable progress being made in their overall performances. While existing metrics like CLIPScore work for coarse evaluations, they lack the sensitivity to distinguish finer differences as model performance rapidly improves. In this work, we focus on the text rendering aspect of these models, which provides a lens for evaluating a generative model's fine-grained instruction-following capabilities. To this end, we introduce a new evaluation framework called TypeScore to sensitively assess a model's ability to generate images with high-fidelity embedded text by following precise instructions. We argue that this text generation capability serves as a proxy for general instruction-following ability in image synthesis. TypeScore uses an additional image description model and leverages an ensemble dissimilarity measure between the original and extracted text to evaluate the fidelity of the rendered text. Our proposed metric demonstrates greater resolution than CLIPScore to differentiate popular image generation models across a range of instructions with diverse text styles. Our study also evaluates how well these vision-language models (VLMs) adhere to stylistic instructions, disentangling style evaluation from embedded-text fidelity. Through human evaluation studies, we quantitatively meta-evaluate the effectiveness of the metric. Comprehensive analysis is conducted to explore factors such as text length, captioning models, and current progress towards human parity on this task. The framework provides insights into remaining gaps in instruction-following for image generation with embedded text.
Automating Program Structure Classification
Jan 15, 2021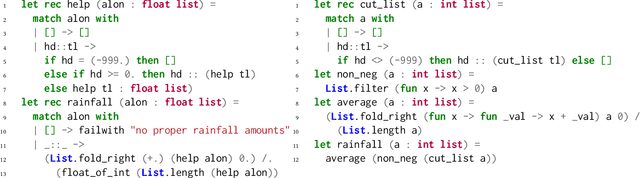

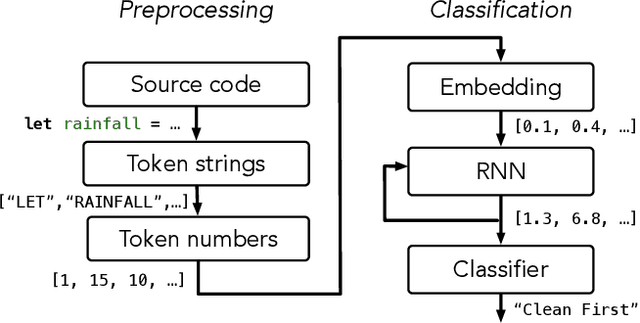
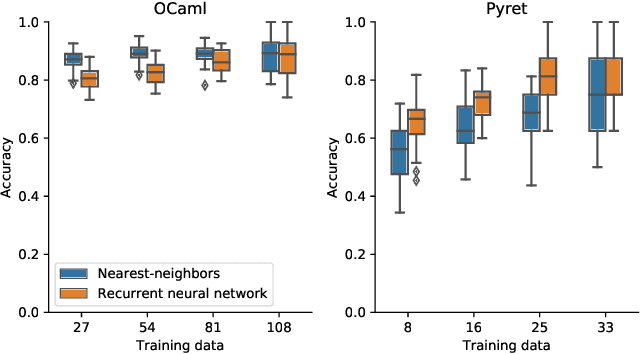
When students write programs, their program structure provides insight into their learning process. However, analyzing program structure by hand is time-consuming, and teachers need better tools for computer-assisted exploration of student solutions. As a first step towards an education-oriented program analysis toolkit, we show how supervised machine learning methods can automatically classify student programs into a predetermined set of high-level structures. We evaluate two models on classifying student solutions to the Rainfall problem: a nearest-neighbors classifier using syntax tree edit distance and a recurrent neural network. We demonstrate that these models can achieve 91% classification accuracy when trained on 108 programs. We further explore the generality, trade-offs, and failure cases of each model.