 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Explanations That Anticipate Human Misconceptions Can Improve Human Decision-Making Skills
Oct 05, 2024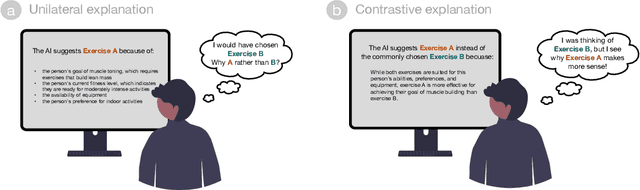
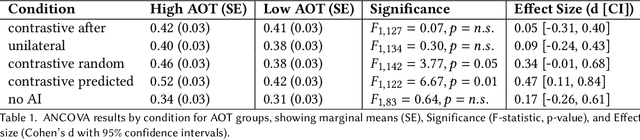


People's decision-making abilities often fail to improve or may even erode when they rely on AI for decision-support, even when the AI provides informative explanations. We argue this is partly because people intuitively seek contrastive explanations, which clarify the difference between the AI's decision and their own reasoning, while most AI systems offer "unilateral" explanations that justify the AI's decision but do not account for users' thinking. To align human-AI knowledge on decision tasks, we introduce a framework for generating human-centered contrastive explanations that explain the difference between AI's choice and a predicted, likely human choice about the same task. Results from a large-scale experiment (N = 628) demonstrate that contrastive explanations significantly enhance users' independent decision-making skills compared to unilateral explanations, without sacrificing decision accuracy. Amid rising deskilling concerns, our research demonstrates that incorporating human reasoning into AI design can foster human skill development.
Towards Optimizing Human-Centric Objectives in AI-Assisted Decision-Making With Offline Reinforcement Learning
Mar 09, 2024



As AI assistance is increasingly infused into decision-making processes, we may seek to optimize human-centric objectives beyond decision accuracy, such as skill improvement or task enjoyment of individuals interacting with these systems. With this aspiration in mind, we propose offline reinforcement learning (RL) as a general approach for modeling human-AI decision-making to optimize such human-centric objectives. Our approach seeks to optimize different objectives by adaptively providing decision support to humans -- the right type of assistance, to the right person, at the right time. We instantiate our approach with two objectives: human-AI accuracy on the decision-making task and human learning about the task, and learn policies that optimize these two objectives from previous human-AI interaction data. We compare the optimized policies against various baselines in AI-assisted decision-making. Across two experiments (N = 316 and N = 964), our results consistently demonstrate that people interacting with policies optimized for accuracy achieve significantly better accuracy -- and even human-AI complementarity -- compared to those interacting with any other type of AI support. Our results further indicate that human learning is more difficult to optimize than accuracy, with participants who interacted with learning-optimized policies showing significant learning improvement only at times. Our research (1) demonstrates offline RL to be a promising approach to model dynamics of human-AI decision-making, leading to policies that may optimize various human-centric objectives and provide novel insights about the AI-assisted decision-making space, and (2) emphasizes the importance of considering human-centric objectives beyond decision accuracy in AI-assisted decision-making, while also opening up the novel research challenge of optimizing such objectives.