 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI as a Double-Edged Sword in Dermatology: The Impact on Clinicians versus The Public
Dec 14, 2025Artificial intelligence (AI) is increasingly permeating healthcare, from physician assistants to consumer applications. Since AI algorithm's opacity challenges human interaction, explainable AI (XAI) addresses this by providing AI decision-making insight, but evidence suggests XAI can paradoxically induce over-reliance or bias. We present results from two large-scale experiments (623 lay people; 153 primary care physicians, PCPs) combining a fairness-based diagnosis AI model and different XAI explanations to examine how XAI assistance, particularly multimodal large language models (LLMs), influences diagnostic performance. AI assistance balanced across skin tones improved accuracy and reduced diagnostic disparities. However, LLM explanations yielded divergent effects: lay users showed higher automation bias - accuracy boosted when AI was correct, reduced when AI erred - while experienced PCPs remained resilient, benefiting irrespective of AI accuracy. Presenting AI suggestions first also led to worse outcomes when the AI was incorrect for both groups. These findings highlight XAI's varying impact based on expertise and timing, underscoring LLMs as a "double-edged sword" in medical AI and informing future human-AI collaborative system design.
WatchGuardian: Enabling User-Defined Personalized Just-in-Time Intervention on Smartwatch
Feb 09, 2025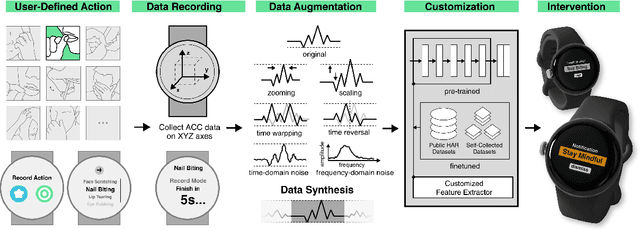
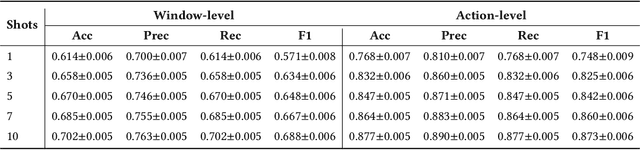
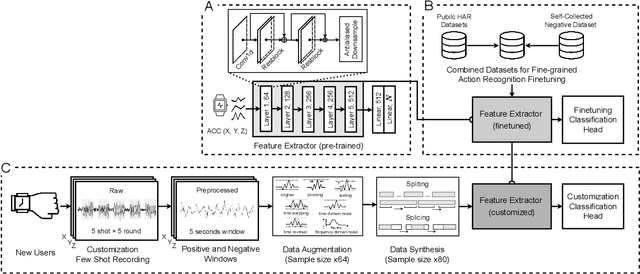
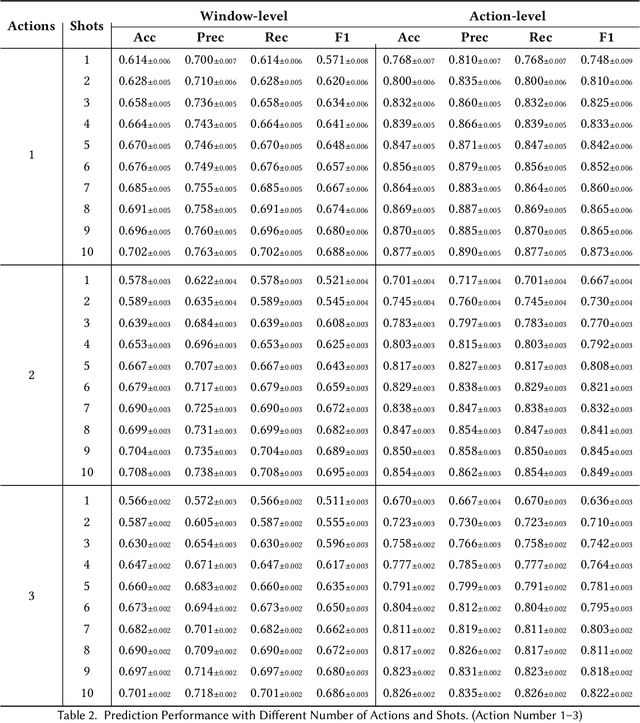
While just-in-time interventions (JITIs) have effectively targeted common health behaviors, individuals often have unique needs to intervene in personal undesirable actions that can negatively affect physical, mental, and social well-being. We present WatchGuardian, a smartwatch-based JITI system that empowers users to define custom interventions for these personal actions with a small number of samples. For the model to detect new actions based on limited new data samples, we developed a few-shot learning pipeline that finetuned a pre-trained inertial measurement unit (IMU) model on public hand-gesture datasets. We then designed a data augmentation and synthesis process to train additional classification layers for customization. Our offline evaluation with 26 participants showed that with three, five, and ten examples, our approach achieved an average accuracy of 76.8%, 84.7%, and 87.7%, and an F1 score of 74.8%, 84.2%, and 87.2% We then conducted a four-hour intervention study to compare WatchGuardian against a rule-based intervention. Our results demonstrated that our system led to a significant reduction by 64.0 +- 22.6% in undesirable actions, substantially outperforming the baseline by 29.0%. Our findings underscore the effectiveness of a customizable, AI-driven JITI system for individuals in need of behavioral intervention in personal undesirable actions. We envision that our work can inspire broader applications of user-defined personalized intervention with advanced AI solutions.
Do People Engage Cognitively with AI? Impact of AI Assistance on Incidental Learning
Feb 11, 2022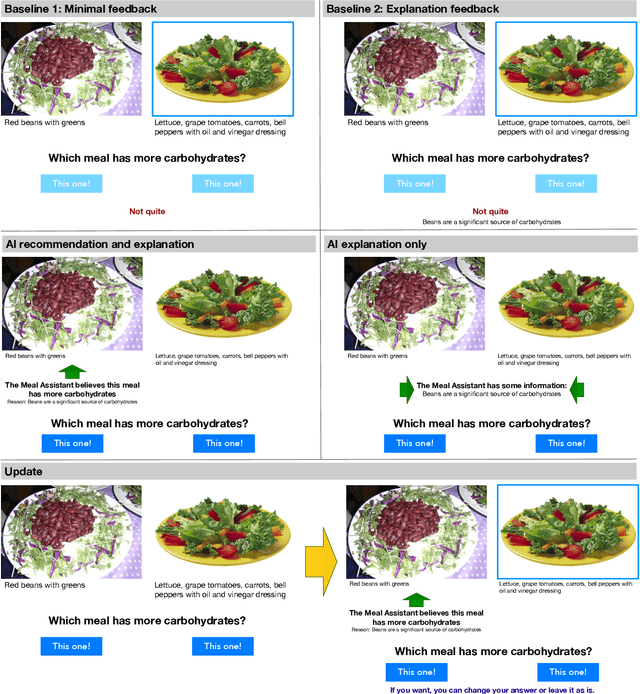
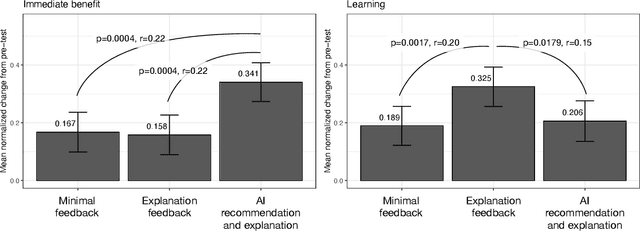
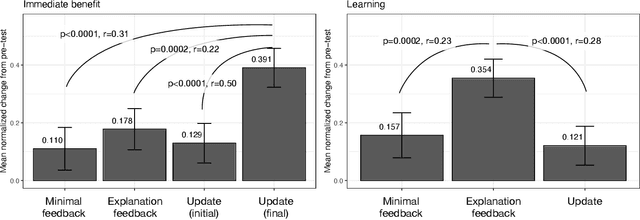
When people receive advice while making difficult decisions, they often make better decisions in the moment and also increase their knowledge in the process. However, such incidental learning can only occur when people cognitively engage with the information they receive and process this information thoughtfully. How do people process the information and advice they receive from AI, and do they engage with it deeply enough to enable learning? To answer these questions, we conducted three experiments in which individuals were asked to make nutritional decisions and received simulated AI recommendations and explanations. In the first experiment, we found that when people were presented with both a recommendation and an explanation before making their choice, they made better decisions than they did when they received no such help, but they did not learn. In the second experiment, participants first made their own choice, and only then saw a recommendation and an explanation from AI; this condition also resulted in improved decisions, but no learning. However, in our third experiment, participants were presented with just an AI explanation but no recommendation and had to arrive at their own decision. This condition led to both more accurate decisions and learning gains. We hypothesize that learning gains in this condition were due to deeper engagement with explanations needed to arrive at the decisions. This work provides some of the most direct evidence to date that it may not be sufficient to include explanations together with AI-generated recommendation to ensure that people engage carefully with the AI-provided information. This work also presents one technique that enables incidental learning and, by implication, can help people process AI recommendations and explanations more carefully.
Behavioral-clinical phenotyping with type 2 diabetes self-monitoring data
Feb 23, 2018
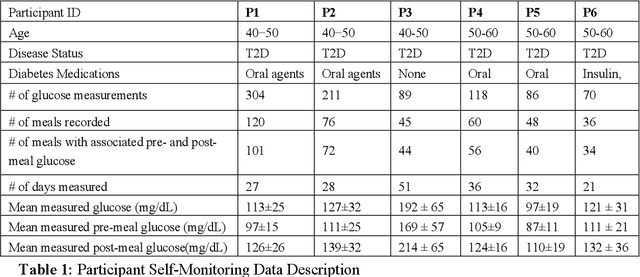
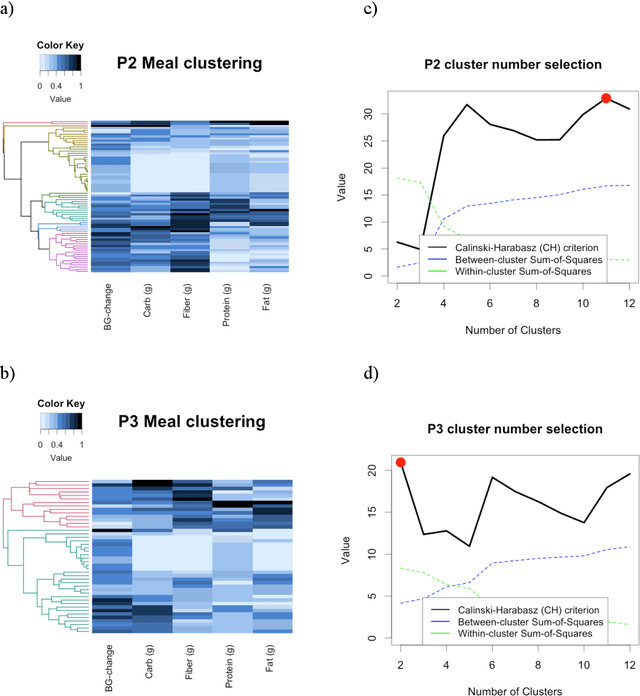

Objective: To evaluate unsupervised clustering methods for identifying individual-level behavioral-clinical phenotypes that relate personal biomarkers and behavioral traits in type 2 diabetes (T2DM) self-monitoring data. Materials and Methods: We used hierarchical clustering (HC) to identify groups of meals with similar nutrition and glycemic impact for 6 individuals with T2DM who collected self-monitoring data. We evaluated clusters on: 1) correspondence to gold standards generated by certified diabetes educators (CDEs) for 3 participants; 2) face validity, rated by CDEs, and 3) impact on CDEs' ability to identify patterns for another 3 participants. Results: Gold standard (GS) included 9 patterns across 3 participants. Of these, all 9 were re-discovered using HC: 4 GS patterns were consistent with patterns identified by HC (over 50% of meals in a cluster followed the pattern); another 5 were included as sub-groups in broader clusers. 50% (9/18) of clusters were rated over 3 on 5-point Likert scale for validity, significance, and being actionable. After reviewing clusters, CDEs identified patterns that were more consistent with data (70% reduction in contradictions between patterns and participants' records). Discussion: Hierarchical clustering of blood glucose and macronutrient consumption appears suitable for discovering behavioral-clinical phenotypes in T2DM. Most clusters corresponded to gold standard and were rated positively by CDEs for face validity. Cluster visualizations helped CDEs identify more robust patterns in nutrition and glycemic impact, creating new possibilities for visual analytic solutions. Conclusion: Machine learning methods can use diabetes self-monitoring data to create personalized behavioral-clinical phenotypes, which may prove useful for delivering personalized medicine.