 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Can Emerge in Tabular Foundation Models From a Single Table
Nov 12, 2025



Deep tabular modelling increasingly relies on in-context learning where, during inference, a model receives a set of $(x,y)$ pairs as context and predicts labels for new inputs without weight updates. We challenge the prevailing view that broad generalization here requires pre-training on large synthetic corpora (e.g., TabPFN priors) or a large collection of real data (e.g., TabDPT training datasets), discovering that a relatively small amount of data suffices for generalization. We find that simple self-supervised pre-training on just a \emph{single} real table can produce surprisingly strong transfer across heterogeneous benchmarks. By systematically pre-training and evaluating on many diverse datasets, we analyze what aspects of the data are most important for building a Tabular Foundation Model (TFM) generalizing across domains. We then connect this to the pre-training procedure shared by most TFMs and show that the number and quality of \emph{tasks} one can construct from a dataset is key to downstream performance.
Semantic Commit: Helping Users Update Intent Specifications for AI Memory at Scale
Apr 12, 2025How do we update AI memory of user intent as intent changes? We consider how an AI interface may assist the integration of new information into a repository of natural language data. Inspired by software engineering concepts like impact analysis, we develop methods and a UI for managing semantic changes with non-local effects, which we call "semantic conflict resolution." The user commits new intent to a project -- makes a "semantic commit" -- and the AI helps the user detect and resolve semantic conflicts within a store of existing information representing their intent (an "intent specification"). We develop an interface, SemanticCommit, to better understand how users resolve conflicts when updating intent specifications such as Cursor Rules and game design documents. A knowledge graph-based RAG pipeline drives conflict detection, while LLMs assist in suggesting resolutions. We evaluate our technique on an initial benchmark. Then, we report a 12 user within-subjects study of SemanticCommit for two task domains -- game design documents, and AI agent memory in the style of ChatGPT memories -- where users integrated new information into an existing list. Half of our participants adopted a workflow of impact analysis, where they would first flag conflicts without AI revisions then resolve conflicts locally, despite having access to a global revision feature. We argue that AI agent interfaces, such as software IDEs like Cursor and Windsurf, should provide affordances for impact analysis and help users validate AI retrieval independently from generation. Our work speaks to how AI agent designers should think about updating memory as a process that involves human feedback and decision-making.
Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB
Apr 01, 2025Knowledge-intensive analytical applications retrieve context from both structured tabular data and unstructured, text-free documents for effective decision-making. Large language models (LLMs) have made it significantly easier to prototype such retrieval and reasoning data pipelines. However, implementing these pipelines efficiently still demands significant effort and has several challenges. This often involves orchestrating heterogeneous data systems, managing data movement, and handling low-level implementation details, e.g., LLM context management. To address these challenges, we introduce FlockMTL: an extension for DBMSs that deeply integrates LLM capabilities and retrieval-augmented generation (RAG). FlockMTL includes model-driven scalar and aggregate functions, enabling chained predictions through tuple-level mappings and reductions. Drawing inspiration from the relational model, FlockMTL incorporates: (i) cost-based optimizations, which seamlessly apply techniques such as batching and caching; and (ii) resource independence, enabled through novel SQL DDL abstractions: PROMPT and MODEL, introduced as first-class schema objects alongside TABLE. FlockMTL streamlines the development of knowledge-intensive analytical applications, and its optimizations ease the implementation burden.
GenEdit: Compounding Operators and Continuous Improvement to Tackle Text-to-SQL in the Enterprise
Mar 27, 2025
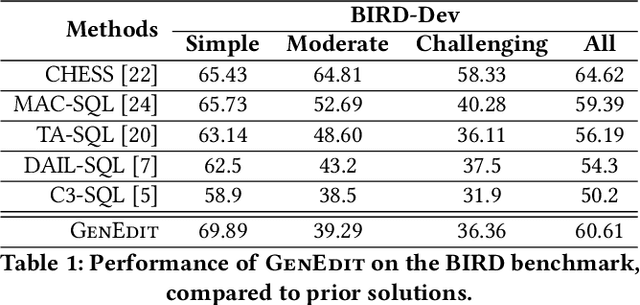


Recent advancements in Text-to-SQL, driven by large language models, are democratizing data access. Despite these advancements, enterprise deployments remain challenging due to the need to capture business-specific knowledge, handle complex queries, and meet expectations of continuous improvements. To address these issues, we designed and implemented GenEdit: our Text-to-SQL generation system that improves with user feedback. GenEdit builds and maintains a company-specific knowledge set, employs a pipeline of operators decomposing SQL generation, and uses feedback to update its knowledge set to improve future SQL generations. We describe GenEdit's architecture made of two core modules: (i) decomposed SQL generation; and (ii) knowledge set edits based on user feedback. For generation, GenEdit leverages compounding operators to improve knowledge retrieval and to create a plan as chain-of-thought steps that guides generation. GenEdit first retrieves relevant examples in an initial retrieval stage where original SQL queries are decomposed into sub-statements, clauses or sub-queries. It then also retrieves instructions and schema elements. Using the retrieved contextual information, GenEdit then generates step-by-step plan in natural language on how to produce the query. Finally, GenEdit uses the plan to generate SQL, minimizing the need for model reasoning, which enhances complex SQL generation. If necessary, GenEdit regenerates the query based on syntactic and semantic errors. The knowledge set edits are recommended through an interactive copilot, allowing users to iterate on their feedback and to regenerate SQL queries as needed. Each generation uses staged edits which update the generation prompt. Once the feedback is submitted, it gets merged after passing regression testing and obtaining an approval, improving future generations.
Towards Optimizing SQL Generation via LLM Routing
Nov 06, 2024Text-to-SQL enables users to interact with databases through natural language, simplifying access to structured data. Although highly capable large language models (LLMs) achieve strong accuracy for complex queries, they incur unnecessary latency and dollar cost for simpler ones. In this paper, we introduce the first LLM routing approach for Text-to-SQL, which dynamically selects the most cost-effective LLM capable of generating accurate SQL for each query. We present two routing strategies (score- and classification-based) that achieve accuracy comparable to the most capable LLM while reducing costs. We design the routers for ease of training and efficient inference. In our experiments, we highlight a practical and explainable accuracy-cost trade-off on the BIRD dataset.
The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models
Aug 14, 2024


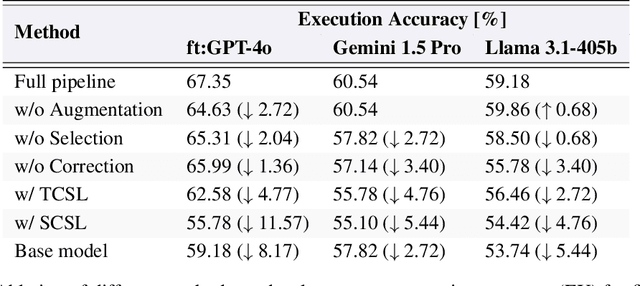
Schema linking is a crucial step in Text-to-SQL pipelines, which translate natural language queries into SQL. The goal of schema linking is to retrieve relevant tables and columns (signal) while disregarding irrelevant ones (noise). However, imperfect schema linking can often exclude essential columns needed for accurate query generation. In this work, we revisit the need for schema linking when using the latest generation of large language models (LLMs). We find empirically that newer models are adept at identifying relevant schema elements during generation, without the need for explicit schema linking. This allows Text-to-SQL pipelines to bypass schema linking entirely and instead pass the full database schema to the LLM, eliminating the risk of excluding necessary information. Furthermore, as alternatives to schema linking, we propose techniques that improve Text-to-SQL accuracy without compromising on essential schema information. Our approach achieves 71.83\% execution accuracy on the BIRD benchmark, ranking first at the time of submission.
End-to-end Text-to-SQL Generation within an Analytics Insight Engine
Jun 17, 2024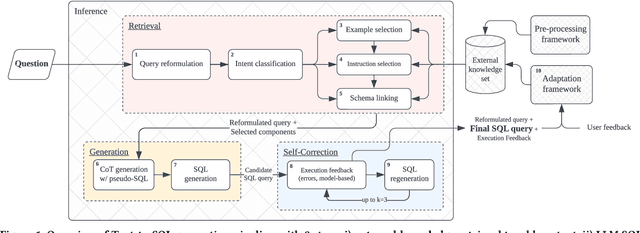
Recent advancements in Text-to-SQL have pushed database management systems towards greater democratization of data access. Today's language models are at the core of these advancements. They enable impressive Text-to-SQL generation as experienced in the development of Distyl AI's Analytics Insight Engine. Its early deployment with enterprise customers has highlighted three core challenges. First, data analysts expect support with authoring SQL queries of very high complexity. Second, requests are ad-hoc and, as such, require low latency. Finally, generation requires an understanding of domain-specific terminology and practices. The design and implementation of our Text-to-SQL generation pipeline, powered by large language models, tackles these challenges. The core tenants of our approach rely on external knowledge that we extract in a pre-processing phase, on retrieving the appropriate external knowledge at query generation time, and on decomposing SQL query generation following a hierarchical CTE-based structure. Finally, an adaptation framework leverages feedback to update the external knowledge, in turn improving query generation over time. We give an overview of our end-to-end approach and highlight the operators generating SQL during inference.