 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLattice: Generative Guardrails for Conversational Agents
Jan 24, 2026Conversational AI systems require guardrails to prevent harmful outputs, yet existing approaches use static rules that cannot adapt to new threats or deployment contexts. We introduce Lattice, a framework for self-constructing and continuously improving guardrails. Lattice operates in two stages: construction builds initial guardrails from labeled examples through iterative simulation and optimization; continuous improvement autonomously adapts deployed guardrails through risk assessment, adversarial testing, and consolidation. Evaluated on the ProsocialDialog dataset, Lattice achieves 91% F1 on held-out data, outperforming keyword baselines by 43pp, LlamaGuard by 25pp, and NeMo by 4pp. The continuous improvement stage achieves 7pp F1 improvement on cross-domain data through closed-loop optimization. Our framework shows that effective guardrails can be self-constructed through iterative optimization.
How Many Instructions Can LLMs Follow at Once?
Jul 15, 2025Production-grade LLM systems require robust adherence to dozens or even hundreds of instructions simultaneously. However, the instruction-following capabilities of LLMs at high instruction densities have not yet been characterized, as existing benchmarks only evaluate models on tasks with a single or few instructions. We introduce IFScale, a simple benchmark of 500 keyword-inclusion instructions for a business report writing task to measure how instruction-following performance degrades as instruction density increases. We evaluate 20 state-of-the-art models across seven major providers and find that even the best frontier models only achieve 68% accuracy at the max density of 500 instructions. Our analysis reveals model size and reasoning capability to correlate with 3 distinct performance degradation patterns, bias towards earlier instructions, and distinct categories of instruction-following errors. Our insights can help inform design of instruction-dense prompts in real-world applications and highlight important performance-latency tradeoffs. We open-source the benchmark and all results for further analysis at https://distylai.github.io/IFScale.
GenEdit: Compounding Operators and Continuous Improvement to Tackle Text-to-SQL in the Enterprise
Mar 27, 2025
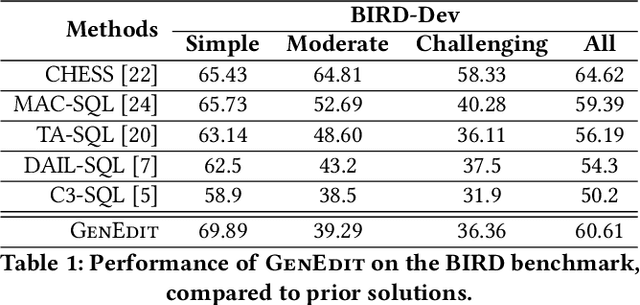


Recent advancements in Text-to-SQL, driven by large language models, are democratizing data access. Despite these advancements, enterprise deployments remain challenging due to the need to capture business-specific knowledge, handle complex queries, and meet expectations of continuous improvements. To address these issues, we designed and implemented GenEdit: our Text-to-SQL generation system that improves with user feedback. GenEdit builds and maintains a company-specific knowledge set, employs a pipeline of operators decomposing SQL generation, and uses feedback to update its knowledge set to improve future SQL generations. We describe GenEdit's architecture made of two core modules: (i) decomposed SQL generation; and (ii) knowledge set edits based on user feedback. For generation, GenEdit leverages compounding operators to improve knowledge retrieval and to create a plan as chain-of-thought steps that guides generation. GenEdit first retrieves relevant examples in an initial retrieval stage where original SQL queries are decomposed into sub-statements, clauses or sub-queries. It then also retrieves instructions and schema elements. Using the retrieved contextual information, GenEdit then generates step-by-step plan in natural language on how to produce the query. Finally, GenEdit uses the plan to generate SQL, minimizing the need for model reasoning, which enhances complex SQL generation. If necessary, GenEdit regenerates the query based on syntactic and semantic errors. The knowledge set edits are recommended through an interactive copilot, allowing users to iterate on their feedback and to regenerate SQL queries as needed. Each generation uses staged edits which update the generation prompt. Once the feedback is submitted, it gets merged after passing regression testing and obtaining an approval, improving future generations.
The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models
Aug 14, 2024


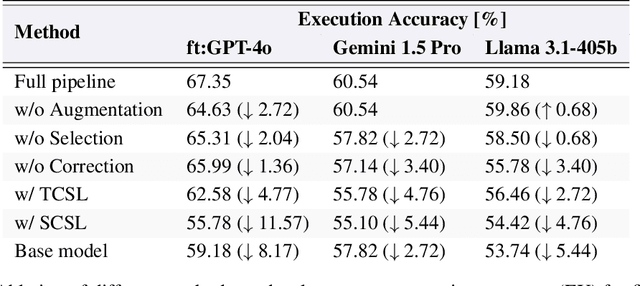
Schema linking is a crucial step in Text-to-SQL pipelines, which translate natural language queries into SQL. The goal of schema linking is to retrieve relevant tables and columns (signal) while disregarding irrelevant ones (noise). However, imperfect schema linking can often exclude essential columns needed for accurate query generation. In this work, we revisit the need for schema linking when using the latest generation of large language models (LLMs). We find empirically that newer models are adept at identifying relevant schema elements during generation, without the need for explicit schema linking. This allows Text-to-SQL pipelines to bypass schema linking entirely and instead pass the full database schema to the LLM, eliminating the risk of excluding necessary information. Furthermore, as alternatives to schema linking, we propose techniques that improve Text-to-SQL accuracy without compromising on essential schema information. Our approach achieves 71.83\% execution accuracy on the BIRD benchmark, ranking first at the time of submission.
End-to-end Text-to-SQL Generation within an Analytics Insight Engine
Jun 17, 2024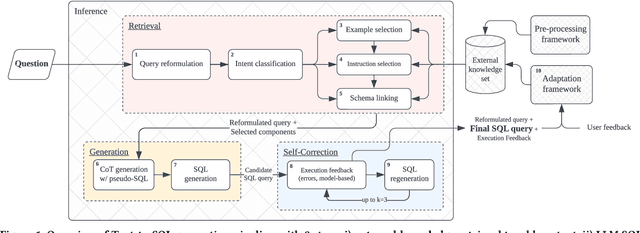
Recent advancements in Text-to-SQL have pushed database management systems towards greater democratization of data access. Today's language models are at the core of these advancements. They enable impressive Text-to-SQL generation as experienced in the development of Distyl AI's Analytics Insight Engine. Its early deployment with enterprise customers has highlighted three core challenges. First, data analysts expect support with authoring SQL queries of very high complexity. Second, requests are ad-hoc and, as such, require low latency. Finally, generation requires an understanding of domain-specific terminology and practices. The design and implementation of our Text-to-SQL generation pipeline, powered by large language models, tackles these challenges. The core tenants of our approach rely on external knowledge that we extract in a pre-processing phase, on retrieving the appropriate external knowledge at query generation time, and on decomposing SQL query generation following a hierarchical CTE-based structure. Finally, an adaptation framework leverages feedback to update the external knowledge, in turn improving query generation over time. We give an overview of our end-to-end approach and highlight the operators generating SQL during inference.