 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models
Paper and Code
Aug 14, 2024


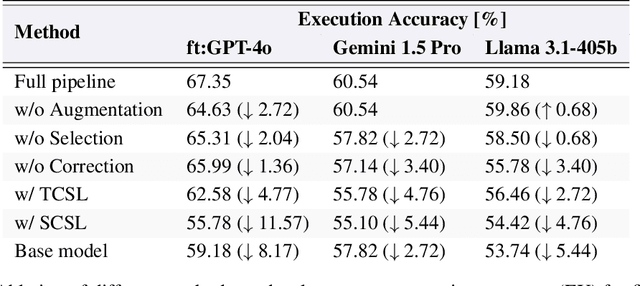
Schema linking is a crucial step in Text-to-SQL pipelines, which translate natural language queries into SQL. The goal of schema linking is to retrieve relevant tables and columns (signal) while disregarding irrelevant ones (noise). However, imperfect schema linking can often exclude essential columns needed for accurate query generation. In this work, we revisit the need for schema linking when using the latest generation of large language models (LLMs). We find empirically that newer models are adept at identifying relevant schema elements during generation, without the need for explicit schema linking. This allows Text-to-SQL pipelines to bypass schema linking entirely and instead pass the full database schema to the LLM, eliminating the risk of excluding necessary information. Furthermore, as alternatives to schema linking, we propose techniques that improve Text-to-SQL accuracy without compromising on essential schema information. Our approach achieves 71.83\% execution accuracy on the BIRD benchmark, ranking first at the time of submission.