 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinTSR: A Windowed Temporal Saliency Rescaling Method for Interpreting Time Series Deep Learning Models
Dec 05, 2024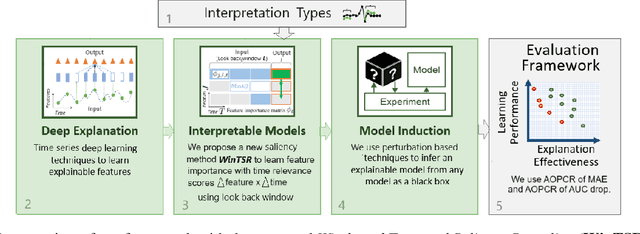


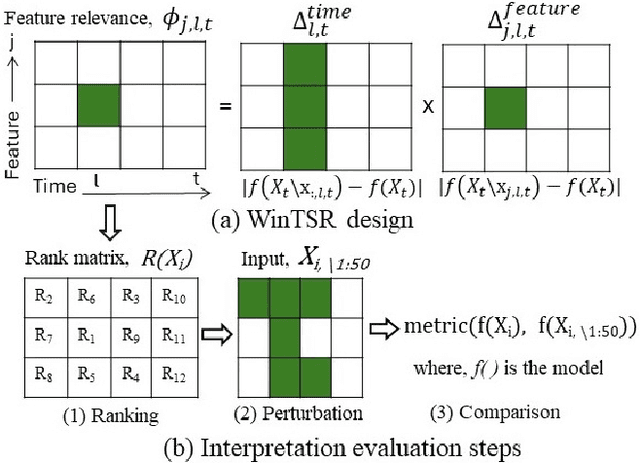
Interpreting complex time series forecasting models is challenging due to the temporal dependencies between time steps and the dynamic relevance of input features over time. Existing interpretation methods are limited by focusing mostly on classification tasks, evaluating using custom baseline models instead of the latest time series models, using simple synthetic datasets, and requiring training another model. We introduce a novel interpretation method called Windowed Temporal Saliency Rescaling (WinTSR) addressing these limitations. WinTSR explicitly captures temporal dependencies among the past time steps and efficiently scales the feature importance with this time importance. We benchmark WinTSR against 10 recent interpretation techniques with 5 state-of-the-art deep-learning models of different architectures, including a time series foundation model. We use 3 real-world datasets for both time-series classification and regression. Our comprehensive analysis shows that WinTSR significantly outranks the other local interpretation methods in overall performance. Finally, we provide a novel and open-source framework to interpret the latest time series transformers and foundation models.
Does Differential Privacy Impact Bias in Pretrained NLP Models?
Oct 24, 2024



Differential privacy (DP) is applied when fine-tuning pre-trained large language models (LLMs) to limit leakage of training examples. While most DP research has focused on improving a model's privacy-utility tradeoff, some find that DP can be unfair to or biased against underrepresented groups. In this work, we show the impact of DP on bias in LLMs through empirical analysis. Differentially private training can increase the model bias against protected groups w.r.t AUC-based bias metrics. DP makes it more difficult for the model to differentiate between the positive and negative examples from the protected groups and other groups in the rest of the population. Our results also show that the impact of DP on bias is not only affected by the privacy protection level but also the underlying distribution of the dataset.
Accepted or Abandoned? Predicting the Fate of Code Changes
Dec 07, 2019



Many mature Open-Source Software (OSS), as well as commercial, organizations have adopted peer code review as an integral part of the development process to ensure the quality of the product. Of particular interest are code changes that end up "abandoned," either because they are rejected, or (more commonly) because they are never accepted at all (at least not through the review tool). Several factors such as resource allocation, job environment, and efficiency mismatch between the author and the reviewer may cause a code change to be abandoned even after months of efforts from the developers and the reviewers. Predicting the review outcome of such code changes can ease the prioritization of tasks and the utilization of limited resources by saving time spent on low-quality code changes. In this paper, we conducted a comprehensive study to predict whether a code change is merged or abandoned and applied various well-known supervised machine learning algorithms. We propose PredCR, a Random Forest based model that predicts the review outcome of a code change with 0.91 f-measure at the beginning of the code change on the test set. Also, it improves predictions of abandoned changes by 27\%-103\% and merged changes by 5\%-11\%. Our model accurately classifies 93\% of the top 25\% code changes (with average 196 days duration) that go longest without being merged. PredCR can also adapt to the changes in feature values at different stages of the review process although it achieves very high performance at the very early stage (within 10\% of the review process). This way, prediction quality for a particular code change can improve as the code review progresses. We also conducted a study to find out the properties of an ideal training set for our tool. We found that training with the instances from the same projects ensures 9\%-25\% performance increase.