 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJetPrism: diagnosing convergence for generative simulation and inverse problems in nuclear physics
Apr 01, 2026High-fidelity Monte Carlo simulations and complex inverse problems, such as mapping smeared experimental observations to ground-truth states, are computationally intensive yet essential for robust data analysis. Conditional Flow Matching (CFM) offers a mathematically robust approach to accelerating these tasks, but we demonstrate its standard training loss is fundamentally misleading. In rigorous physics applications, CFM loss plateaus prematurely, serving as an unreliable indicator of true convergence and physical fidelity. To investigate this disconnect, we designed JetPrism, a configurable CFM framework acting as an efficient generative surrogate for evaluating unconditional generation and conditional detector unfolding. Using synthetic stress tests and a Jefferson Lab kinematic dataset ($γp \to ρ^0 p \to π^+π^- p$) relevant to the forthcoming Electron-Ion Collider (EIC), we establish that physics-informed metrics continue to improve significantly long after the standard loss converges. Consequently, we propose a multi-metric evaluation protocol incorporating marginal and pairwise $χ^2$ statistics, $W_1$ distances, correlation matrix distances ($D_{\mathrm{corr}}$), and nearest-neighbor distance ratios ($R_{\mathrm{NN}}$). By demonstrating that domain-specific evaluations must supersede generic loss metrics, this work establishes JetPrism as a dependable generative surrogate that ensures precise statistical agreement with ground-truth data without memorizing the training set. While demonstrated in nuclear physics, this diagnostic framework is readily extensible to parameter generation and complex inverse problems across broad domains. Potential applications span medical imaging, astrophysics, semiconductor discovery, and quantitative finance, where high-fidelity simulation, rigorous inversion, and generative reliability are critical.
Cosmo3DFlow: Wavelet Flow Matching for Spatial-to-Spectral Compression in Reconstructing the Early Universe
Feb 10, 2026Reconstructing the early Universe from the evolved present-day Universe is a challenging and computationally demanding problem in modern astrophysics. We devise a novel generative framework, Cosmo3DFlow, designed to address dimensionality and sparsity, the critical bottlenecks inherent in current state-of-the-art methods for cosmological inference. By integrating 3D Discrete Wavelet Transform (DWT) with flow matching, we effectively represent high-dimensional cosmological structures. The Wavelet Transform addresses the ``void problem'' by translating spatial emptiness into spectral sparsity. It decouples high-frequency details from low-frequency structures through spatial compression, and wavelet-space velocity fields facilitate stable ordinary differential equation (ODE) solvers with large step sizes. Using large-scale cosmological $N$-body simulations, at $128^3$ resolution, we achieve up to $50\times$ faster sampling than diffusion models, combining a $10\times$ reduction in integration steps with lower per-step computational cost from wavelet compression. Our results enable initial conditions to be sampled in seconds, compared to minutes for previous methods.
OmniSpectra: A Unified Foundation Model for Native Resolution Astronomical Spectra
Jan 21, 2026We present OmniSpectra, the first native-resolution foundation model for astronomy spectra. Unlike traditional models, which are limited to fixed-length input sizes or configurations, OmniSpectra handles spectra of any length at their original size, without resampling or interpolation. Despite the large-scale spectroscopic data from diverse surveys fueling the rapid growth of astronomy, existing foundation models are limited to a fixed wavelength range and specific instruments. OmniSpectra is the first foundation model to learn simultaneously from multiple real-world spectra surveys with different configurations at a large scale. We achieve this by designing a novel architecture with adaptive patching across variable lengths, sinusoidal global wavelength encoding, local positional embeddings through depthwise convolution, and validity-aware self-attention masks. Allowing us to learn multi-scale spatial patterns while skipping attention for invalid patches. Even with a limited training example, OmniSpectra demonstrates excellent zero-shot generalization compared to methods tailored for specific tasks. This transfer learning capability makes this model the state-of-the-art across various astronomy tasks, including source classification, redshift estimation, and properties prediction for stars and galaxies. OmniSpectra reduces the need for training individual models for different tasks from scratch, establishing itself as the next-generation astronomy foundation model.
Leveraging Exogenous Signals for Hydrology Time Series Forecasting
Nov 14, 2025Recent advances in time series research facilitate the development of foundation models. While many state-of-the-art time series foundation models have been introduced, few studies examine their effectiveness in specific downstream applications in physical science. This work investigates the role of integrating domain knowledge into time series models for hydrological rainfall-runoff modeling. Using the CAMELS-US dataset, which includes rainfall and runoff data from 671 locations with six time series streams and 30 static features, we compare baseline and foundation models. Results demonstrate that models incorporating comprehensive known exogenous inputs outperform more limited approaches, including foundation models. Notably, incorporating natural annual periodic time series contribute the most significant improvements.
Scalable Cosmic AI Inference using Cloud Serverless Computing with FMI
Jan 08, 2025



Large-scale astronomical image data processing and prediction is essential for astronomers, providing crucial insights into celestial objects, the universe's history, and its evolution. While modern deep learning models offer high predictive accuracy, they often demand substantial computational resources, making them resource-intensive and limiting accessibility. We introduce the Cloud-based Astronomy Inference (CAI) framework to address these challenges. This scalable solution integrates pre-trained foundation models with serverless cloud infrastructure through a Function-as-a-Service (FaaS) Message Interface (FMI). CAI enables efficient and scalable inference on astronomical images without extensive hardware. Using a foundation model for redshift prediction as a case study, our extensive experiments cover user devices, HPC (High-Performance Computing) servers, and Cloud. CAI's significant scalability improvement on large data sizes provides an accessible and effective tool for the astronomy community. The code is accessible at https://github.com/UVA-MLSys/AI-for-Astronomy.
WinTSR: A Windowed Temporal Saliency Rescaling Method for Interpreting Time Series Deep Learning Models
Dec 05, 2024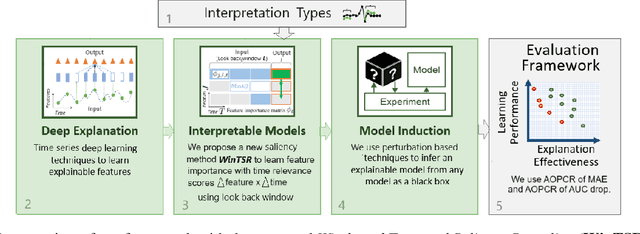


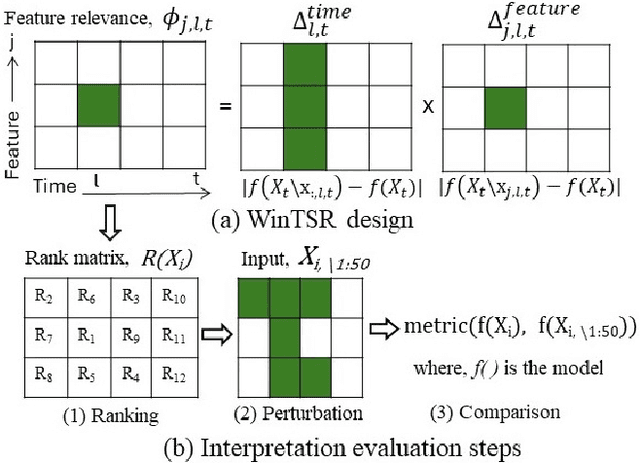
Interpreting complex time series forecasting models is challenging due to the temporal dependencies between time steps and the dynamic relevance of input features over time. Existing interpretation methods are limited by focusing mostly on classification tasks, evaluating using custom baseline models instead of the latest time series models, using simple synthetic datasets, and requiring training another model. We introduce a novel interpretation method called Windowed Temporal Saliency Rescaling (WinTSR) addressing these limitations. WinTSR explicitly captures temporal dependencies among the past time steps and efficiently scales the feature importance with this time importance. We benchmark WinTSR against 10 recent interpretation techniques with 5 state-of-the-art deep-learning models of different architectures, including a time series foundation model. We use 3 real-world datasets for both time-series classification and regression. Our comprehensive analysis shows that WinTSR significantly outranks the other local interpretation methods in overall performance. Finally, we provide a novel and open-source framework to interpret the latest time series transformers and foundation models.
Does Differential Privacy Impact Bias in Pretrained NLP Models?
Oct 24, 2024



Differential privacy (DP) is applied when fine-tuning pre-trained large language models (LLMs) to limit leakage of training examples. While most DP research has focused on improving a model's privacy-utility tradeoff, some find that DP can be unfair to or biased against underrepresented groups. In this work, we show the impact of DP on bias in LLMs through empirical analysis. Differentially private training can increase the model bias against protected groups w.r.t AUC-based bias metrics. DP makes it more difficult for the model to differentiate between the positive and negative examples from the protected groups and other groups in the rest of the population. Our results also show that the impact of DP on bias is not only affected by the privacy protection level but also the underlying distribution of the dataset.
Large Language Models for Financial Aid in Financial Time-series Forecasting
Oct 24, 2024Considering the difficulty of financial time series forecasting in financial aid, much of the current research focuses on leveraging big data analytics in financial services. One modern approach is to utilize "predictive analysis", analogous to forecasting financial trends. However, many of these time series data in Financial Aid (FA) pose unique challenges due to limited historical datasets and high dimensional financial information, which hinder the development of effective predictive models that balance accuracy with efficient runtime and memory usage. Pre-trained foundation models are employed to address these challenging tasks. We use state-of-the-art time series models including pre-trained LLMs (GPT-2 as the backbone), transformers, and linear models to demonstrate their ability to outperform traditional approaches, even with minimal ("few-shot") or no fine-tuning ("zero-shot"). Our benchmark study, which includes financial aid with seven other time series tasks, shows the potential of using LLMs for scarce financial datasets.
Interpreting Time Series Transformer Models and Sensitivity Analysis of Population Age Groups to COVID-19 Infections
Jan 26, 2024Interpreting deep learning time series models is crucial in understanding the model's behavior and learning patterns from raw data for real-time decision-making. However, the complexity inherent in transformer-based time series models poses challenges in explaining the impact of individual features on predictions. In this study, we leverage recent local interpretation methods to interpret state-of-the-art time series models. To use real-world datasets, we collected three years of daily case data for 3,142 US counties. Firstly, we compare six transformer-based models and choose the best prediction model for COVID-19 infection. Using 13 input features from the last two weeks, we can predict the cases for the next two weeks. Secondly, we present an innovative way to evaluate the prediction sensitivity to 8 population age groups over highly dynamic multivariate infection data. Thirdly, we compare our proposed perturbation-based interpretation method with related work, including a total of eight local interpretation methods. Finally, we apply our framework to traffic and electricity datasets, demonstrating that our approach is generic and can be applied to other time-series domains.
Fairness and Privacy in Federated Learning and Their Implications in Healthcare
Aug 15, 2023

Currently, many contexts exist where distributed learning is difficult or otherwise constrained by security and communication limitations. One common domain where this is a consideration is in Healthcare where data is often governed by data-use-ordinances like HIPAA. On the other hand, larger sample sizes and shared data models are necessary to allow models to better generalize on account of the potential for more variability and balancing underrepresented classes. Federated learning is a type of distributed learning model that allows data to be trained in a decentralized manner. This, in turn, addresses data security, privacy, and vulnerability considerations as data itself is not shared across a given learning network nodes. Three main challenges to federated learning include node data is not independent and identically distributed (iid), clients requiring high levels of communication overhead between peers, and there is the heterogeneity of different clients within a network with respect to dataset bias and size. As the field has grown, the notion of fairness in federated learning has also been introduced through novel implementations. Fairness approaches differ from the standard form of federated learning and also have distinct challenges and considerations for the healthcare domain. This paper endeavors to outline the typical lifecycle of fair federated learning in research as well as provide an updated taxonomy to account for the current state of fairness in implementations. Lastly, this paper provides added insight into the implications and challenges of implementing and supporting fairness in federated learning in the healthcare domain.