 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Floorspace in China: A Dataset and Learning Pipeline
Mar 03, 2023
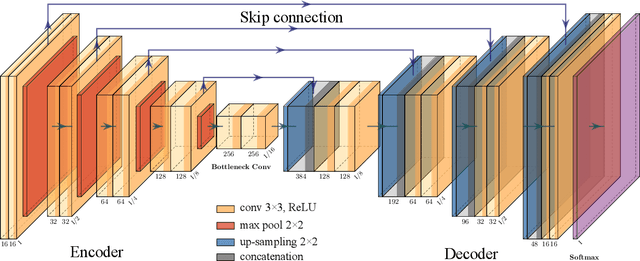
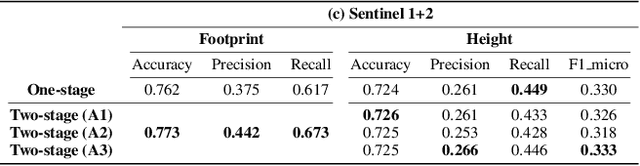

This paper provides the first milestone in measuring the floor space of buildings (that is, building footprint and height) and its evolution over time for China. Doing so requires building on imagery that is of a medium-fine-grained granularity, as longer cross-sections and time series data across many cities are only available in such format. We use a multi-class object segmenter approach to gauge the floor space of buildings in the same framework: first, we determine whether a surface area is covered by buildings (the square footage of occupied land); second, we need to determine the height of buildings from their imagery. We then use Sentinel-1 and -2 satellite images as our main data source. The benefits of these data are their large cross-sectional and longitudinal scope plus their unrestricted accessibility. We provide a detailed description of the algorithms used to generate the data and the results. We analyze the preprocessing steps of reference data (if not ground truth data) and their consequences for measuring the building floor space. We also discuss the future steps in building a time series on urban development based on our preliminary experimental results.
Keyword Extraction in Scientific Documents
Jul 07, 2022


The scientific publication output grows exponentially. Therefore, it is increasingly challenging to keep track of trends and changes. Understanding scientific documents is an important step in downstream tasks such as knowledge graph building, text mining, and discipline classification. In this workshop, we provide a better understanding of keyword and keyphrase extraction from the abstract of scientific publications.
TableParser: Automatic Table Parsing with Weak Supervision from Spreadsheets
Jan 05, 2022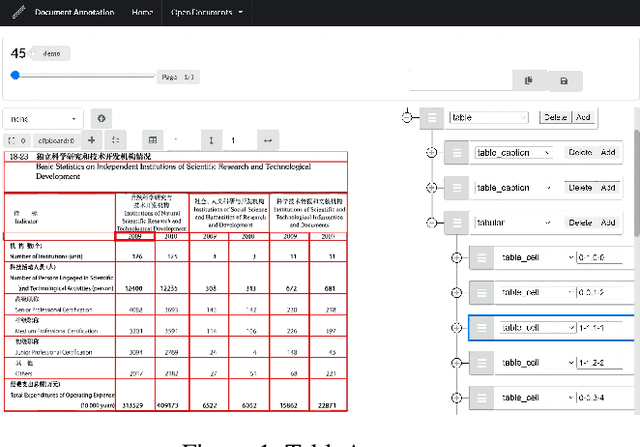
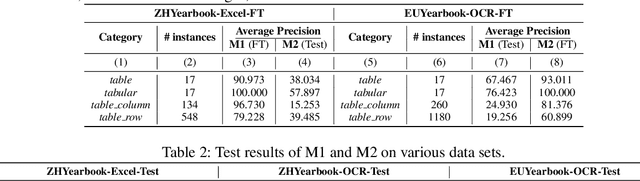
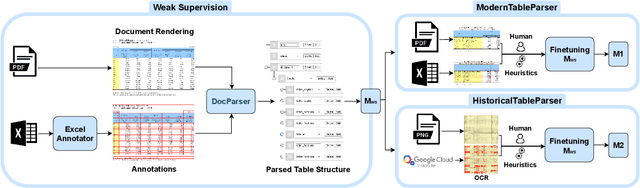

Tables have been an ever-existing structure to store data. There exist now different approaches to store tabular data physically. PDFs, images, spreadsheets, and CSVs are leading examples. Being able to parse table structures and extract content bounded by these structures is of high importance in many applications. In this paper, we devise TableParser, a system capable of parsing tables in both native PDFs and scanned images with high precision. We have conducted extensive experiments to show the efficacy of domain adaptation in developing such a tool. Moreover, we create TableAnnotator and ExcelAnnotator, which constitute a spreadsheet-based weak supervision mechanism and a pipeline to enable table parsing. We share these resources with the research community to facilitate further research in this interesting direction.