 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes `Deep Learning on a Data Diet' reproduce? Overall yes, but GraNd at Initialization does not
Paper and Code
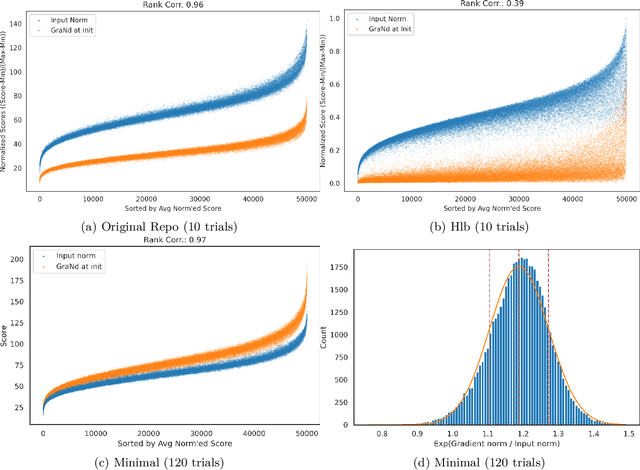
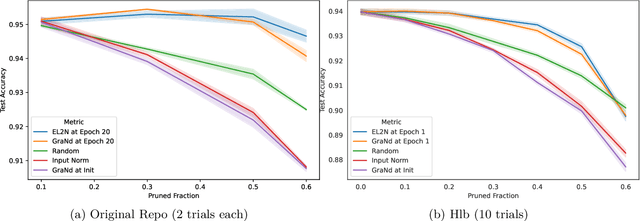
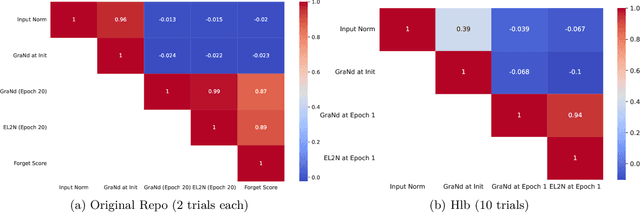
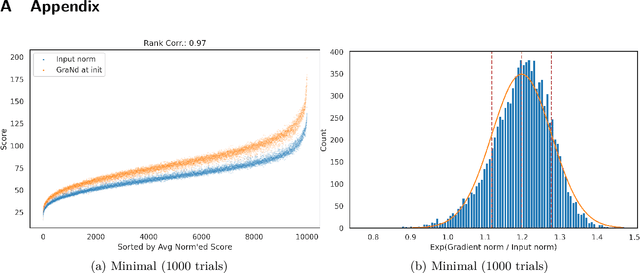
The paper 'Deep Learning on a Data Diet' by Paul et al. (2021) introduces two innovative metrics for pruning datasets during the training of neural networks. While we are able to replicate the results for the EL2N score at epoch 20, the same cannot be said for the GraNd score at initialization. The GraNd scores later in training provide useful pruning signals, however. The GraNd score at initialization calculates the average gradient norm of an input sample across multiple randomly initialized models before any training has taken place. Our analysis reveals a strong correlation between the GraNd score at initialization and the input norm of a sample, suggesting that the latter could have been a cheap new baseline for data pruning. Unfortunately, neither the GraNd score at initialization nor the input norm surpasses random pruning in performance. This contradicts one of the findings in Paul et al. (2021). We were unable to reproduce their CIFAR-10 results using both an updated version of the original JAX repository and in a newly implemented PyTorch codebase. An investigation of the underlying JAX/FLAX code from 2021 surfaced a bug in the checkpoint restoring code that was fixed in April 2021 (https://github.com/google/flax/commit/28fbd95500f4bf2f9924d2560062fa50e919b1a5).