 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Domain Units for Multi-source Domain Generalization
Jun 24, 2022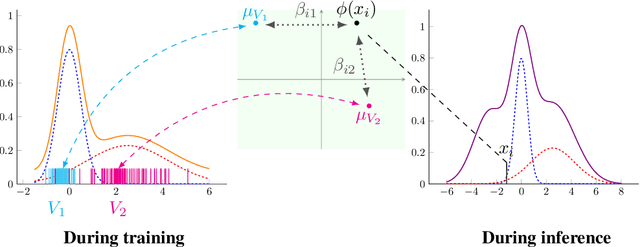

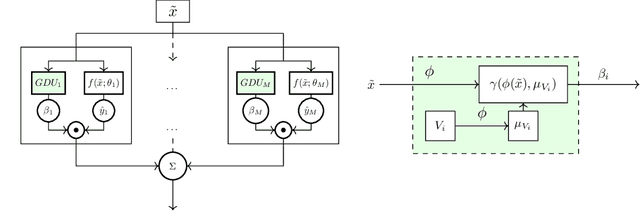
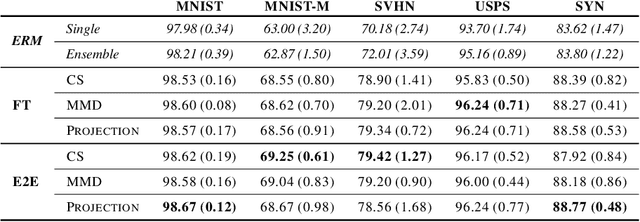
Distribution shift (DS) is a common problem that deteriorates the performance of learning machines. To overcome this problem, we postulate that real-world distributions are composed of elementary distributions that remain invariant across different domains. We call this an invariant elementary distribution (I.E.D.) assumption. This invariance thus enables knowledge transfer to unseen domains. To exploit this assumption in domain generalization (DG), we developed a modular neural network layer that consists of Gated Domain Units (GDUs). Each GDU learns an embedding of an individual elementary domain that allows us to encode the domain similarities during the training. During inference, the GDUs compute similarities between an observation and each of the corresponding elementary distributions which are then used to form a weighted ensemble of learning machines. Because our layer is trained with backpropagation, it can be easily integrated into existing deep learning frameworks. Our evaluation on Digits5, ECG, Camelyon17, iWildCam, and FMoW shows a significant improvement in the performance on out-of-training target domains without any access to data from the target domains. This finding supports the validity of the I.E.D. assumption in real-world data distributions.
Ranking architectures using meta-learning
Nov 26, 2019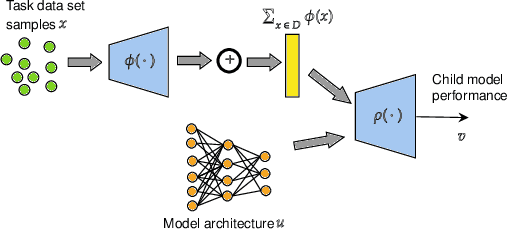
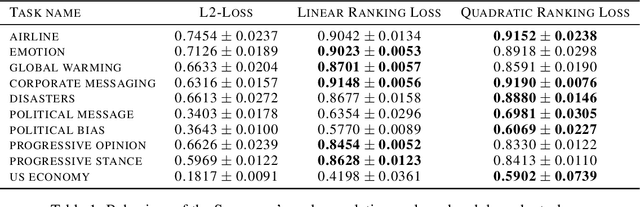
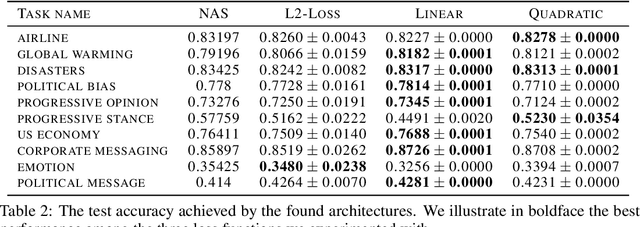
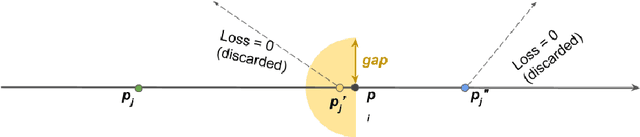
Neural architecture search has recently attracted lots of research efforts as it promises to automate the manual design of neural networks. However, it requires a large amount of computing resources and in order to alleviate this, a performance prediction network has been recently proposed that enables efficient architecture search by forecasting the performance of candidate architectures, instead of relying on actual model training. The performance predictor is task-aware taking as input not only the candidate architecture but also task meta-features and it has been designed to collectively learn from several tasks. In this work, we introduce a pairwise ranking loss for training a network able to rank candidate architectures for a new unseen task conditioning on its task meta-features. We present experimental results, showing that the ranking network is more effective in architecture search than the previously proposed performance predictor.
Exact information propagation through fully-connected feed forward neural networks
Jun 17, 2018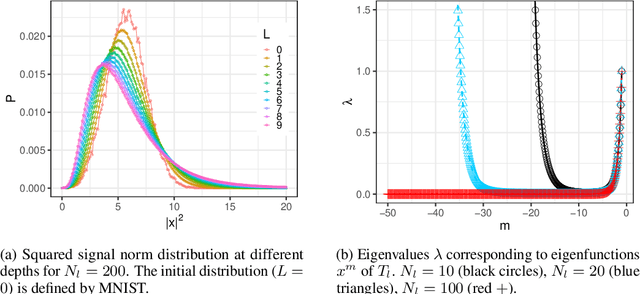
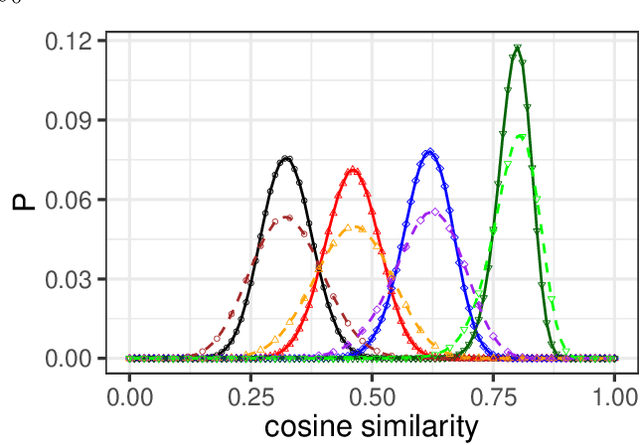
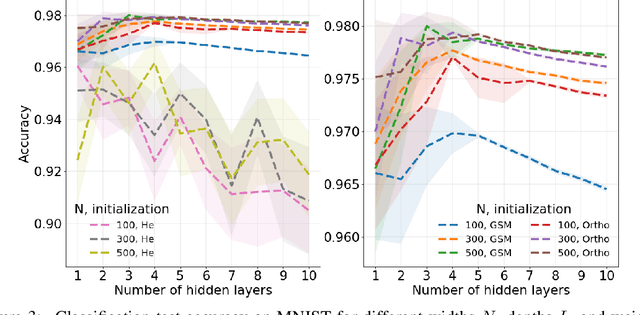
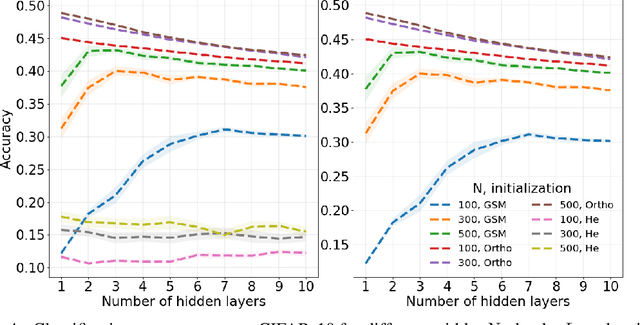
Neural network ensembles at initialisation give rise to the trainability and training speed of neural networks and thus support parameter choices at initialisation. These insights rely so far on mean field approximations that assume infinite layer width and study average squared signals. Thus, information about the full output distribution gets lost. Therefore, we derive the output distribution exactly (without mean field assumptions), for fully-connected networks with Gaussian weights and biases. The layer-wise transition of the signal distribution is guided by a linear integral operator, whose kernel has a closed form solution in case of rectified linear units for nonlinear activations. This enables us to analyze some of its spectral properties, for instance, the shape of the stationary distribution for different parameter choices and the dynamics of signal propagation.