 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArmada: Memory-Efficient Distributed Training of Large-Scale Graph Neural Networks
Feb 25, 2025We study distributed training of Graph Neural Networks (GNNs) on billion-scale graphs that are partitioned across machines. Efficient training in this setting relies on min-edge-cut partitioning algorithms, which minimize cross-machine communication due to GNN neighborhood sampling. Yet, min-edge-cut partitioning over large graphs remains a challenge: State-of-the-art (SoTA) offline methods (e.g., METIS) are effective, but they require orders of magnitude more memory and runtime than GNN training itself, while computationally efficient algorithms (e.g., streaming greedy approaches) suffer from increased edge cuts. Thus, in this work we introduce Armada, a new end-to-end system for distributed GNN training whose key contribution is GREM, a novel min-edge-cut partitioning algorithm that can efficiently scale to large graphs. GREM builds on streaming greedy approaches with one key addition: prior vertex assignments are continuously refined during streaming, rather than frozen after an initial greedy selection. Our theoretical analysis and experimental results show that this refinement is critical to minimizing edge cuts and enables GREM to reach partition quality comparable to METIS but with 8-65x less memory and 8-46x faster. Given a partitioned graph, Armada leverages a new disaggregated architecture for distributed GNN training to further improve efficiency; we find that on common cloud machines, even with zero communication, GNN neighborhood sampling and feature loading bottleneck training. Disaggregation allows Armada to independently allocate resources for these operations and ensure that expensive GPUs remain saturated with computation. We evaluate Armada against SoTA systems for distributed GNN training and find that the disaggregated architecture leads to runtime improvements up to 4.5x and cost reductions up to 3.1x.
Incremental IVF Index Maintenance for Streaming Vector Search
Nov 01, 2024

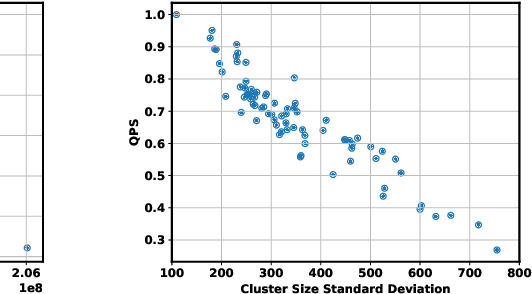

The prevalence of vector similarity search in modern machine learning applications and the continuously changing nature of data processed by these applications necessitate efficient and effective index maintenance techniques for vector search indexes. Designed primarily for static workloads, existing vector search indexes degrade in search quality and performance as the underlying data is updated unless costly index reconstruction is performed. To address this, we introduce Ada-IVF, an incremental indexing methodology for Inverted File (IVF) indexes. Ada-IVF consists of 1) an adaptive maintenance policy that decides which index partitions are problematic for performance and should be repartitioned and 2) a local re-clustering mechanism that determines how to repartition them. Compared with state-of-the-art dynamic IVF index maintenance strategies, Ada-IVF achieves an average of 2x and up to 5x higher update throughput across a range of benchmark workloads.
High-Throughput Vector Similarity Search in Knowledge Graphs
Apr 04, 2023



There is an increasing adoption of machine learning for encoding data into vectors to serve online recommendation and search use cases. As a result, recent data management systems propose augmenting query processing with online vector similarity search. In this work, we explore vector similarity search in the context of Knowledge Graphs (KGs). Motivated by the tasks of finding related KG queries and entities for past KG query workloads, we focus on hybrid vector similarity search (hybrid queries for short) where part of the query corresponds to vector similarity search and part of the query corresponds to predicates over relational attributes associated with the underlying data vectors. For example, given past KG queries for a song entity, we want to construct new queries for new song entities whose vector representations are close to the vector representation of the entity in the past KG query. But entities in a KG also have non-vector attributes such as a song associated with an artist, a genre, and a release date. Therefore, suggested entities must also satisfy query predicates over non-vector attributes beyond a vector-based similarity predicate. While these tasks are central to KGs, our contributions are generally applicable to hybrid queries. In contrast to prior works that optimize online queries, we focus on enabling efficient batch processing of past hybrid query workloads. We present our system, HQI, for high-throughput batch processing of hybrid queries. We introduce a workload-aware vector data partitioning scheme to tailor the vector index layout to the given workload and describe a multi-query optimization technique to reduce the overhead of vector similarity computations. We evaluate our methods on industrial workloads and demonstrate that HQI yields a 31x improvement in throughput for finding related KG queries compared to existing hybrid query processing approaches.
Marius++: Large-Scale Training of Graph Neural Networks on a Single Machine
Feb 04, 2022



Graph Neural Networks (GNNs) have emerged as a powerful model for ML over graph-structured data. Yet, scalability remains a major challenge for using GNNs over billion-edge inputs. The creation of mini-batches used for training incurs computational and data movement costs that grow exponentially with the number of GNN layers as state-of-the-art models aggregate information from the multi-hop neighborhood of each input node. In this paper, we focus on scalable training of GNNs with emphasis on resource efficiency. We show that out-of-core pipelined mini-batch training in a single machine outperforms resource-hungry multi-GPU solutions. We introduce Marius++, a system for training GNNs over billion-scale graphs. Marius++ provides disk-optimized training for GNNs and introduces a series of data organization and algorithmic contributions that 1) minimize the memory-footprint and end-to-end time required for training and 2) ensure that models learned with disk-based training exhibit accuracy similar to those fully trained in mixed CPU/GPU settings. We evaluate Marius++ against PyTorch Geometric and Deep Graph Library using seven benchmark (model, data set) settings and find that Marius++ with one GPU can achieve the same level of model accuracy up to 8$\times$ faster than these systems when they are using up to eight GPUs. For these experiments, disk-based training allows Marius++ deployments to be up to 64$\times$ cheaper in monetary cost than those of the competing systems.
Learning Massive Graph Embeddings on a Single Machine
Jan 20, 2021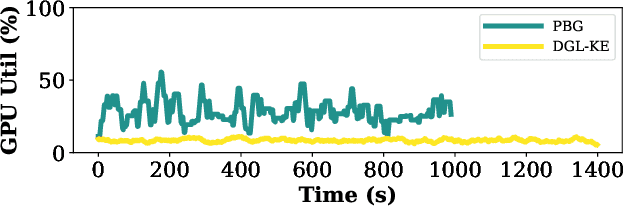

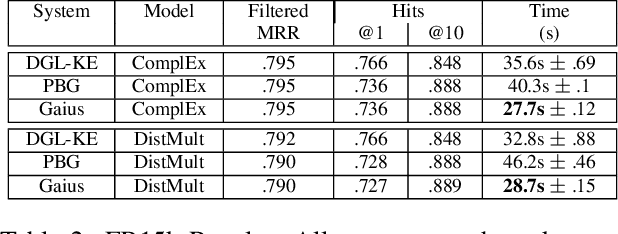
We propose a new framework for computing the embeddings of large-scale graphs on a single machine. A graph embedding is a fixed length vector representation for each node (and/or edge-type) in a graph and has emerged as the de-facto approach to apply modern machine learning on graphs. We identify that current systems for learning the embeddings of large-scale graphs are bottlenecked by data movement, which results in poor resource utilization and inefficient training. These limitations require state-of-the-art systems to distribute training across multiple machines. We propose Gaius, a system for efficient training of graph embeddings that leverages partition caching and buffer-aware data orderings to minimize disk access and interleaves data movement with computation to maximize utilization. We compare Gaius against two state-of-the-art industrial systems on a diverse array of benchmarks. We demonstrate that Gaius achieves the same level of accuracy but is up to one order-of magnitude faster. We also show that Gaius can scale training to datasets an order of magnitude beyond a single machine's GPU and CPU memory capacity, enabling training of configurations with more than a billion edges and 550GB of total parameters on a single AWS P3.2xLarge instance.