 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroNN: An On-device Disk-resident Updatable Vector Database
Apr 08, 2025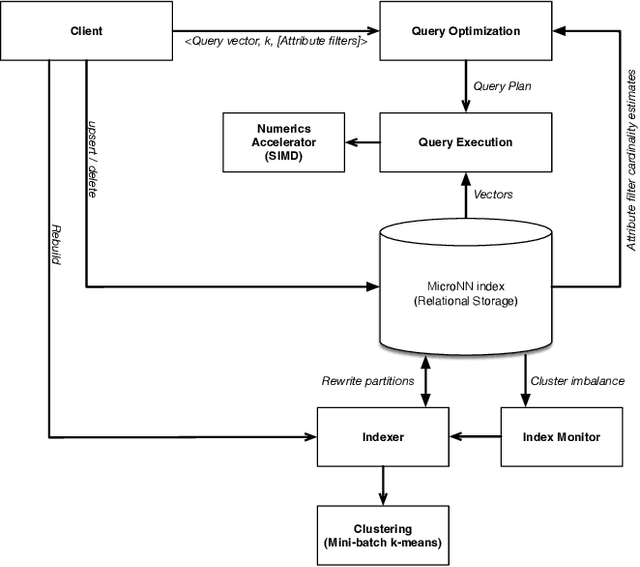
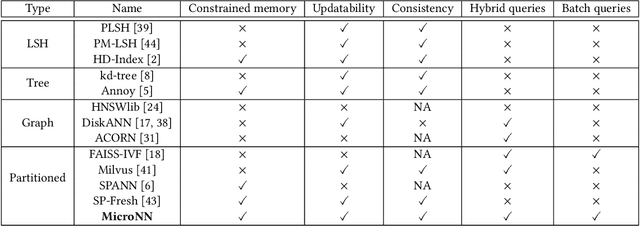

Nearest neighbour search over dense vector collections has important applications in information retrieval, retrieval augmented generation (RAG), and content ranking. Performing efficient search over large vector collections is a well studied problem with many existing approaches and open source implementations. However, most state-of-the-art systems are generally targeted towards scenarios using large servers with an abundance of memory, static vector collections that are not updatable, and nearest neighbour search in isolation of other search criteria. We present Micro Nearest Neighbour (MicroNN), an embedded nearest-neighbour vector search engine designed for scalable similarity search in low-resource environments. MicroNN addresses the problem of on-device vector search for real-world workloads containing updates and hybrid search queries that combine nearest neighbour search with structured attribute filters. In this scenario, memory is highly constrained and disk-efficient index structures and algorithms are required, as well as support for continuous inserts and deletes. MicroNN is an embeddable library that can scale to large vector collections with minimal resources. MicroNN is used in production and powers a wide range of vector search use-cases on-device. MicroNN takes less than 7 ms to retrieve the top-100 nearest neighbours with 90% recall on publicly available million-scale vector benchmark while using ~10 MB of memory.
Incremental IVF Index Maintenance for Streaming Vector Search
Nov 01, 2024

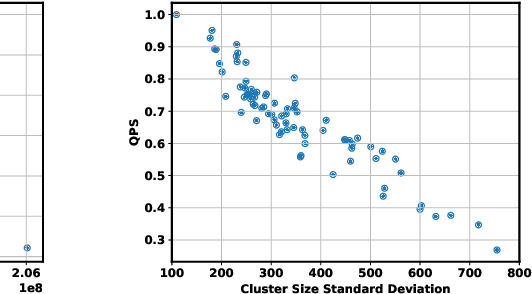

The prevalence of vector similarity search in modern machine learning applications and the continuously changing nature of data processed by these applications necessitate efficient and effective index maintenance techniques for vector search indexes. Designed primarily for static workloads, existing vector search indexes degrade in search quality and performance as the underlying data is updated unless costly index reconstruction is performed. To address this, we introduce Ada-IVF, an incremental indexing methodology for Inverted File (IVF) indexes. Ada-IVF consists of 1) an adaptive maintenance policy that decides which index partitions are problematic for performance and should be repartitioned and 2) a local re-clustering mechanism that determines how to repartition them. Compared with state-of-the-art dynamic IVF index maintenance strategies, Ada-IVF achieves an average of 2x and up to 5x higher update throughput across a range of benchmark workloads.
High-Throughput Vector Similarity Search in Knowledge Graphs
Apr 04, 2023



There is an increasing adoption of machine learning for encoding data into vectors to serve online recommendation and search use cases. As a result, recent data management systems propose augmenting query processing with online vector similarity search. In this work, we explore vector similarity search in the context of Knowledge Graphs (KGs). Motivated by the tasks of finding related KG queries and entities for past KG query workloads, we focus on hybrid vector similarity search (hybrid queries for short) where part of the query corresponds to vector similarity search and part of the query corresponds to predicates over relational attributes associated with the underlying data vectors. For example, given past KG queries for a song entity, we want to construct new queries for new song entities whose vector representations are close to the vector representation of the entity in the past KG query. But entities in a KG also have non-vector attributes such as a song associated with an artist, a genre, and a release date. Therefore, suggested entities must also satisfy query predicates over non-vector attributes beyond a vector-based similarity predicate. While these tasks are central to KGs, our contributions are generally applicable to hybrid queries. In contrast to prior works that optimize online queries, we focus on enabling efficient batch processing of past hybrid query workloads. We present our system, HQI, for high-throughput batch processing of hybrid queries. We introduce a workload-aware vector data partitioning scheme to tailor the vector index layout to the given workload and describe a multi-query optimization technique to reduce the overhead of vector similarity computations. We evaluate our methods on industrial workloads and demonstrate that HQI yields a 31x improvement in throughput for finding related KG queries compared to existing hybrid query processing approaches.