 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroNN: An On-device Disk-resident Updatable Vector Database
Apr 08, 2025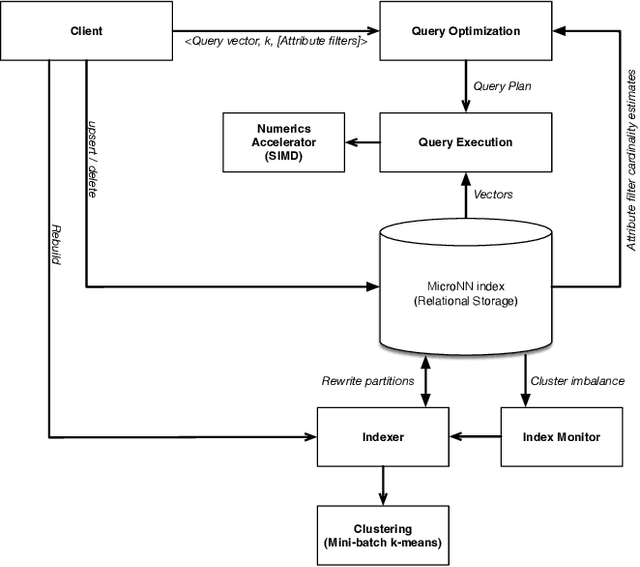
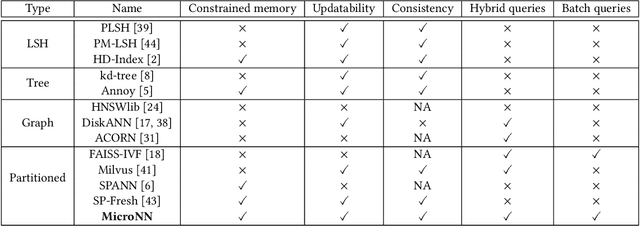

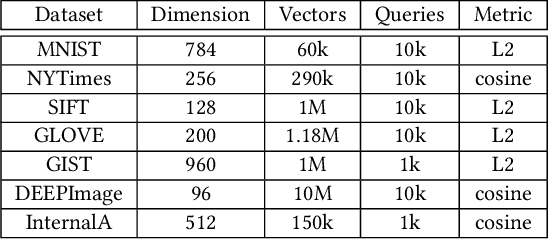
Nearest neighbour search over dense vector collections has important applications in information retrieval, retrieval augmented generation (RAG), and content ranking. Performing efficient search over large vector collections is a well studied problem with many existing approaches and open source implementations. However, most state-of-the-art systems are generally targeted towards scenarios using large servers with an abundance of memory, static vector collections that are not updatable, and nearest neighbour search in isolation of other search criteria. We present Micro Nearest Neighbour (MicroNN), an embedded nearest-neighbour vector search engine designed for scalable similarity search in low-resource environments. MicroNN addresses the problem of on-device vector search for real-world workloads containing updates and hybrid search queries that combine nearest neighbour search with structured attribute filters. In this scenario, memory is highly constrained and disk-efficient index structures and algorithms are required, as well as support for continuous inserts and deletes. MicroNN is an embeddable library that can scale to large vector collections with minimal resources. MicroNN is used in production and powers a wide range of vector search use-cases on-device. MicroNN takes less than 7 ms to retrieve the top-100 nearest neighbours with 90% recall on publicly available million-scale vector benchmark while using ~10 MB of memory.
Unsupervised Relation Extraction from Language Models using Constrained Cloze Completion
Oct 14, 2020
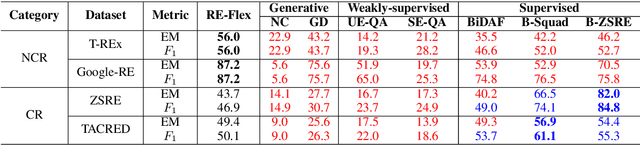
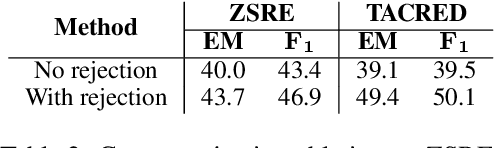

We show that state-of-the-art self-supervised language models can be readily used to extract relations from a corpus without the need to train a fine-tuned extractive head. We introduce RE-Flex, a simple framework that performs constrained cloze completion over pretrained language models to perform unsupervised relation extraction. RE-Flex uses contextual matching to ensure that language model predictions matches supporting evidence from the input corpus that is relevant to a target relation. We perform an extensive experimental study over multiple relation extraction benchmarks and demonstrate that RE-Flex outperforms competing unsupervised relation extraction methods based on pretrained language models by up to 27.8 $F_1$ points compared to the next-best method. Our results show that constrained inference queries against a language model can enable accurate unsupervised relation extraction.
Fine-Grained Object Detection over Scientific Document Images with Region Embeddings
Oct 30, 2019



We study the problem of object detection over scanned images of scientific documents. We consider images that contain objects of varying aspect ratios and sizes and range from coarse elements such as tables and figures to fine elements such as equations and section headers. We find that current object detectors fail to produce properly localized region proposals over such page objects. We revisit the original R-CNN model and present a method for generating fine-grained proposals over document elements. We also present a region embedding model that uses the convolutional maps of a proposal's neighbors as context to produce an embedding for each proposal. This region embedding is able to capture the semantic relationships between a target region and its surrounding context. Our end-to-end model produces an embedding for each proposal, then classifies each proposal by using a multi-head attention model that attends to the most important neighbors of a proposal. To evaluate our model, we collect and annotate a dataset of publications from heterogeneous journals. We show that our model, referred to as Attentive-RCNN, yields a 17% mAP improvement compared to standard object detection models.