 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACCL+: an FPGA-Based Collective Engine for Distributed Applications
Dec 18, 2023FPGAs are increasingly prevalent in cloud deployments, serving as Smart NICs or network-attached accelerators. Despite their potential, developing distributed FPGA-accelerated applications remains cumbersome due to the lack of appropriate infrastructure and communication abstractions. To facilitate the development of distributed applications with FPGAs, in this paper we propose ACCL+, an open-source versatile FPGA-based collective communication library. Portable across different platforms and supporting UDP, TCP, as well as RDMA, ACCL+ empowers FPGA applications to initiate direct FPGA-to-FPGA collective communication. Additionally, it can serve as a collective offload engine for CPU applications, freeing the CPU from networking tasks. It is user-extensible, allowing new collectives to be implemented and deployed without having to re-synthesize the FPGA circuit. We evaluated ACCL+ on an FPGA cluster with 100 Gb/s networking, comparing its performance against software MPI over RDMA. The results demonstrate ACCL+'s significant advantages for FPGA-based distributed applications and highly competitive performance for CPU applications. We showcase ACCL+'s dual role with two use cases: seamlessly integrating as a collective offload engine to distribute CPU-based vector-matrix multiplication, and serving as a crucial and efficient component in designing fully FPGA-based distributed deep-learning recommendation inference.
Co-design Hardware and Algorithm for Vector Search
Jul 06, 2023Vector search has emerged as the foundation for large-scale information retrieval and machine learning systems, with search engines like Google and Bing processing tens of thousands of queries per second on petabyte-scale document datasets by evaluating vector similarities between encoded query texts and web documents. As performance demands for vector search systems surge, accelerated hardware offers a promising solution in the post-Moore's Law era. We introduce \textit{FANNS}, an end-to-end and scalable vector search framework on FPGAs. Given a user-provided recall requirement on a dataset and a hardware resource budget, \textit{FANNS} automatically co-designs hardware and algorithm, subsequently generating the corresponding accelerator. The framework also supports scale-out by incorporating a hardware TCP/IP stack in the accelerator. \textit{FANNS} attains up to 23.0$\times$ and 37.2$\times$ speedup compared to FPGA and CPU baselines, respectively, and demonstrates superior scalability to GPUs, achieving 5.5$\times$ and 7.6$\times$ speedup in median and 95\textsuperscript{th} percentile (P95) latency within an eight-accelerator configuration. The remarkable performance of \textit{FANNS} lays a robust groundwork for future FPGA integration in data centers and AI supercomputers.
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020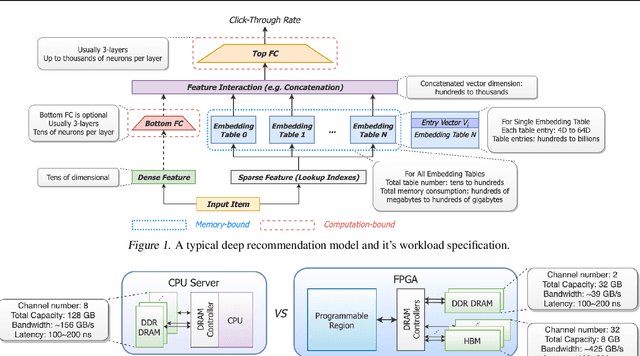
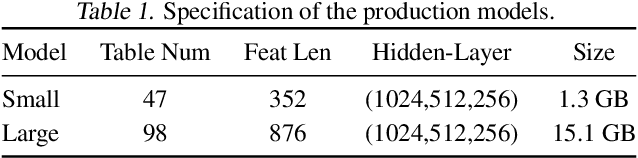
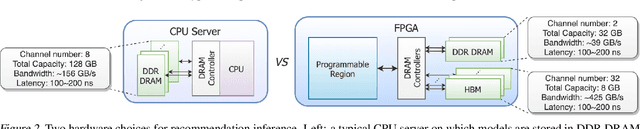
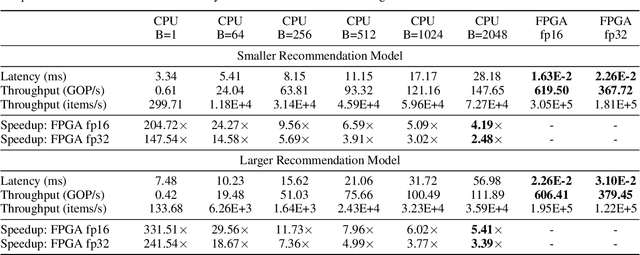
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.
Hierarchical Neural Architecture Search for Single Image Super-Resolution
Mar 10, 2020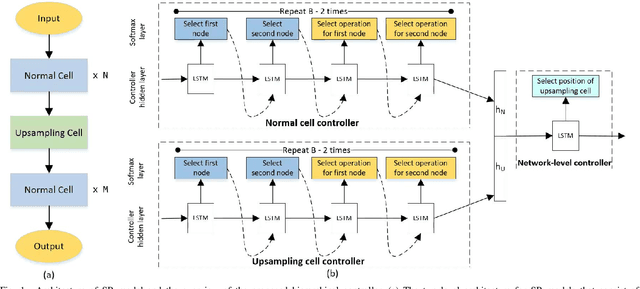
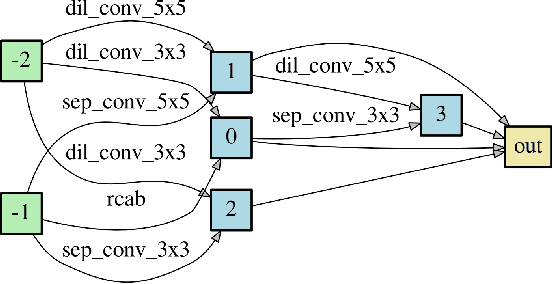


Deep neural networks have exhibited promising performance in image super-resolution (SR). Most SR models follow a hierarchical architecture that contains both the cell-level design of computational blocks and the network-level design of the positions of upsampling blocks. However, designing SR models heavily relies on human expertise and is very labor-intensive. More critically, these SR models often contain a huge number of parameters and may not meet the requirements of computation resources in real-world applications. To address the above issues, we propose a Hierarchical Neural Architecture Search (HNAS) method to automatically design promising architectures with different requirements of computation cost. To this end, we design a hierarchical SR search space and propose a hierarchical controller for architecture search. Such a hierarchical controller is able to simultaneously find promising cell-level blocks and network-level positions of upsampling layers. Moreover, to design compact architectures with promising performance, we build a joint reward by considering both the performance and computation cost to guide the search process. Extensive experiments on five benchmark datasets demonstrate the superiority of our method over existing methods.