 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Compiler for Secure Agentic Systems
Feb 19, 2026LLM-based agents are increasingly being deployed in contexts requiring complex authorization policies: customer service protocols, approval workflows, data access restrictions, and regulatory compliance. Embedding these policies in prompts provides no enforcement guarantees. We present PCAS, a Policy Compiler for Agentic Systems that provides deterministic policy enforcement. Enforcing such policies requires tracking information flow across agents, which linear message histories cannot capture. Instead, PCAS models the agentic system state as a dependency graph capturing causal relationships among events such as tool calls, tool results, and messages. Policies are expressed in a Datalog-derived language, as declarative rules that account for transitive information flow and cross-agent provenance. A reference monitor intercepts all actions and blocks violations before execution, providing deterministic enforcement independent of model reasoning. PCAS takes an existing agent implementation and a policy specification, and compiles them into an instrumented system that is policy-compliant by construction, with no security-specific restructuring required. We evaluate PCAS on three case studies: information flow policies for prompt injection defense, approval workflows in a multi-agent pharmacovigilance system, and organizational policies for customer service. On customer service tasks, PCAS improves policy compliance from 48% to 93% across frontier models, with zero policy violations in instrumented runs.
Pr$εε$mpt: Sanitizing Sensitive Prompts for LLMs
Apr 07, 2025The rise of large language models (LLMs) has introduced new privacy challenges, particularly during inference where sensitive information in prompts may be exposed to proprietary LLM APIs. In this paper, we address the problem of formally protecting the sensitive information contained in a prompt while maintaining response quality. To this end, first, we introduce a cryptographically inspired notion of a prompt sanitizer which transforms an input prompt to protect its sensitive tokens. Second, we propose Pr$\epsilon\epsilon$mpt, a novel system that implements a prompt sanitizer. Pr$\epsilon\epsilon$mpt categorizes sensitive tokens into two types: (1) those where the LLM's response depends solely on the format (such as SSNs, credit card numbers), for which we use format-preserving encryption (FPE); and (2) those where the response depends on specific values, (such as age, salary) for which we apply metric differential privacy (mDP). Our evaluation demonstrates that Pr$\epsilon\epsilon$mpt is a practical method to achieve meaningful privacy guarantees, while maintaining high utility compared to unsanitized prompts, and outperforming prior methods
PolicyLR: A Logic Representation For Privacy Policies
Aug 27, 2024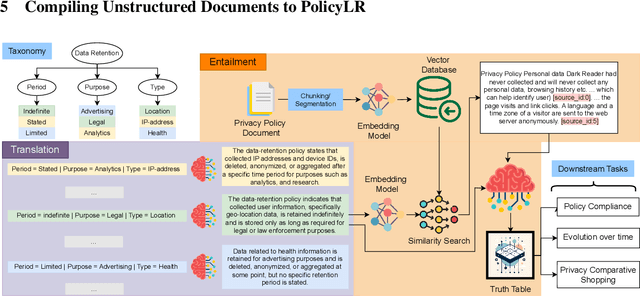
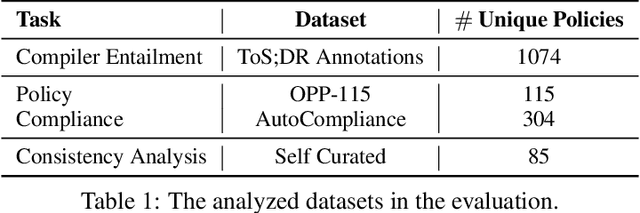
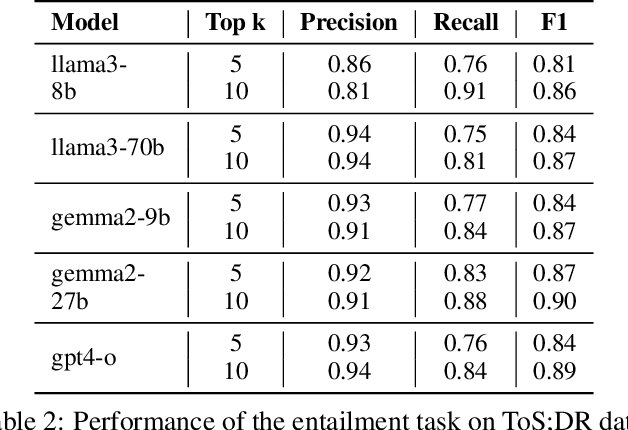
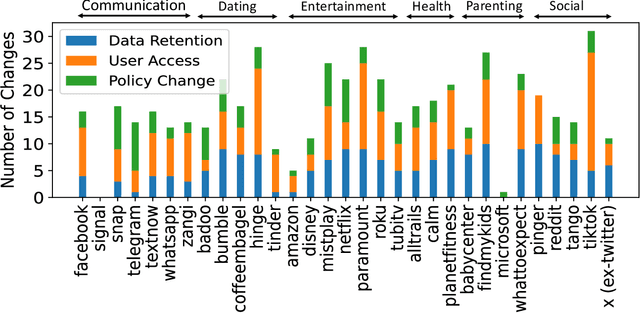
Privacy policies are crucial in the online ecosystem, defining how services handle user data and adhere to regulations such as GDPR and CCPA. However, their complexity and frequent updates often make them difficult for stakeholders to understand and analyze. Current automated analysis methods, which utilize natural language processing, have limitations. They typically focus on individual tasks and fail to capture the full context of the policies. We propose PolicyLR, a new paradigm that offers a comprehensive machine-readable representation of privacy policies, serving as an all-in-one solution for multiple downstream tasks. PolicyLR converts privacy policies into a machine-readable format using valuations of atomic formulae, allowing for formal definitions of tasks like compliance and consistency. We have developed a compiler that transforms unstructured policy text into this format using off-the-shelf Large Language Models (LLMs). This compiler breaks down the transformation task into a two-stage translation and entailment procedure. This procedure considers the full context of the privacy policy to infer a complex formula, where each formula consists of simpler atomic formulae. The advantage of this model is that PolicyLR is interpretable by design and grounded in segments of the privacy policy. We evaluated the compiler using ToS;DR, a community-annotated privacy policy entailment dataset. Utilizing open-source LLMs, our compiler achieves precision and recall values of 0.91 and 0.88, respectively. Finally, we demonstrate the utility of PolicyLR in three privacy tasks: Policy Compliance, Inconsistency Detection, and Privacy Comparison Shopping.
MALADE: Orchestration of LLM-powered Agents with Retrieval Augmented Generation for Pharmacovigilance
Aug 03, 2024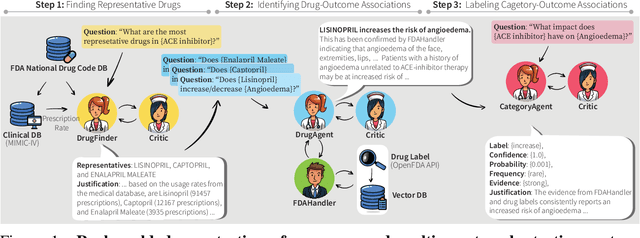
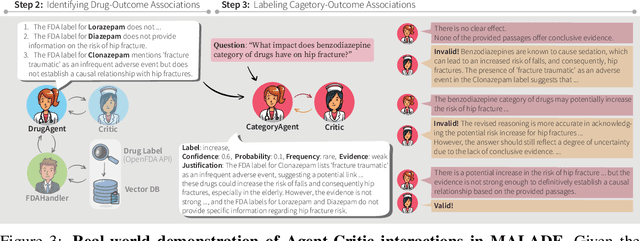
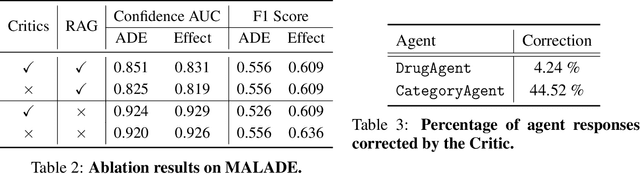
In the era of Large Language Models (LLMs), given their remarkable text understanding and generation abilities, there is an unprecedented opportunity to develop new, LLM-based methods for trustworthy medical knowledge synthesis, extraction and summarization. This paper focuses on the problem of Pharmacovigilance (PhV), where the significance and challenges lie in identifying Adverse Drug Events (ADEs) from diverse text sources, such as medical literature, clinical notes, and drug labels. Unfortunately, this task is hindered by factors including variations in the terminologies of drugs and outcomes, and ADE descriptions often being buried in large amounts of narrative text. We present MALADE, the first effective collaborative multi-agent system powered by LLM with Retrieval Augmented Generation for ADE extraction from drug label data. This technique involves augmenting a query to an LLM with relevant information extracted from text resources, and instructing the LLM to compose a response consistent with the augmented data. MALADE is a general LLM-agnostic architecture, and its unique capabilities are: (1) leveraging a variety of external sources, such as medical literature, drug labels, and FDA tools (e.g., OpenFDA drug information API), (2) extracting drug-outcome association in a structured format along with the strength of the association, and (3) providing explanations for established associations. Instantiated with GPT-4 Turbo or GPT-4o, and FDA drug label data, MALADE demonstrates its efficacy with an Area Under ROC Curve of 0.90 against the OMOP Ground Truth table of ADEs. Our implementation leverages the Langroid multi-agent LLM framework and can be found at https://github.com/jihyechoi77/malade.
Representation Bayesian Risk Decompositions and Multi-Source Domain Adaptation
Apr 22, 2020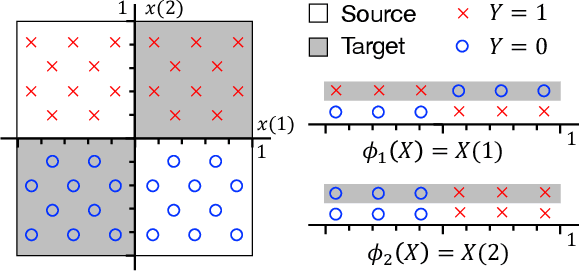
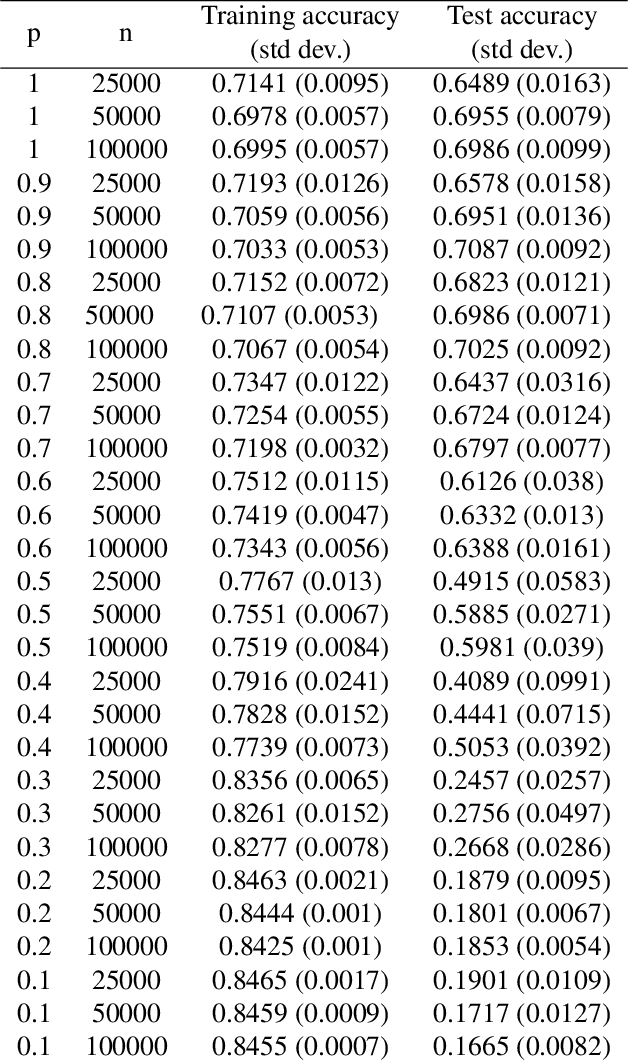

We consider representation learning (with hypothesis class $\mathcal{H} = \mathcal{F}\circ\mathcal{G}$) where training and test distributions can be different. Recent studies provide hints and failure examples for domain invariant representation learning, a common approach to this problem, but are inadequate for fully understanding the phenomena. In this paper, we provide new decompositions of risk which provide finer-grained explanations and clarify potential generalization issues. For Single-Source Domain Adaptation, we give an exact risk decomposition, an equality, where target risk is the sum of three factors: (1) source risk, (2) representation conditional label divergence, and (3) representation covariate shift. We derive a similar decomposition for the Multi-Source case. These decompositions reveal factors (2) and (3) as the precise reasons for failing to generalize. For example, we demonstrate that domain adversarial neural networks (DANN) attempt to regularize for (3) but miss (2), while a recent technique Invariant Risk Minimization (IRM) attempts to account for (2) but may suffer from not considering (3). We also verify these observations experimentally.
CAUSE: Learning Granger Causality from Event Sequences using Attribution Methods
Feb 18, 2020
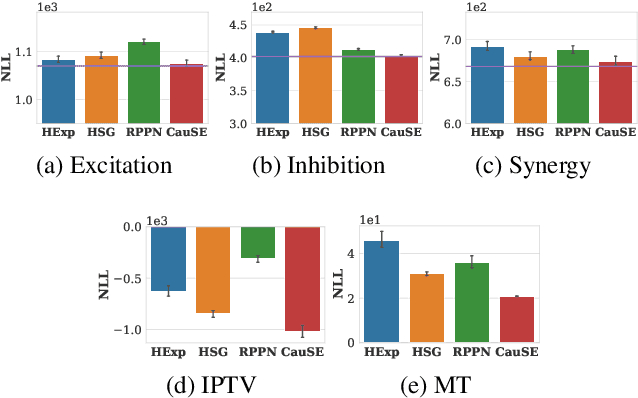
We study the problem of learning Granger causality between event types from asynchronous, interdependent, multi-type event sequences. Existing work suffers from either limited model flexibility or poor model explainability and thus fails to uncover Granger causality across a wide variety of event sequences with diverse event interdependency. To address these weaknesses, we propose CAUSE (Causality from AttribUtions on Sequence of Events), a novel framework for the studied task. The key idea of CAUSE is to first implicitly capture the underlying event interdependency by fitting a neural point process, and then extract from the process a Granger causality statistic using an axiomatic attribution method. Across multiple datasets riddled with diverse event interdependency, we demonstrate that CAUSE achieves superior performance on correctly inferring the inter-type Granger causality over a range of state-of-the-art methods.
Adversarial Learning and Explainability in Structured Datasets
Oct 26, 2018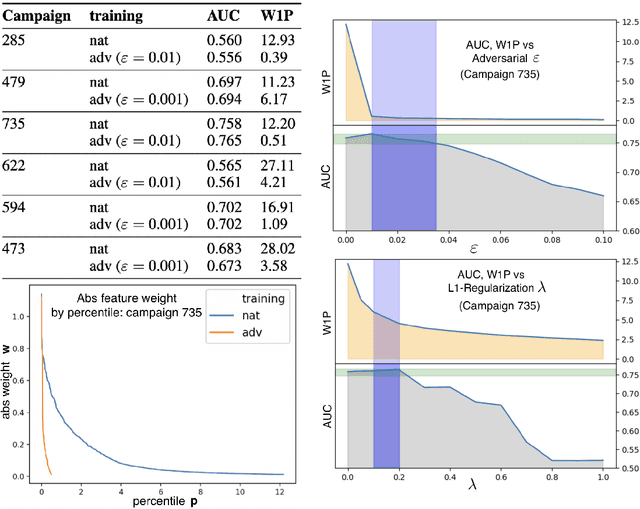
We theoretically and empirically explore the explainability benefits of adversarial learning in logistic regression models on structured datasets. In particular we focus on improved explainability due to significantly higher $\textit{feature-concentration}$ in adversarially-learned models: Compared to natural training, adversarial training tends to more efficiently shrink the weights of non-predictive and weakly-predictive features, while model performance on natural test data only degrades slightly (and even sometimes improves), compared to that of a naturally trained model. We provide theoretical insight into this phenomenon via an analysis of the expectation of the logistic model weight updates by an SGD-based adversarial learning algorithm, where examples are drawn from a random binary data-generation process. We empirically demonstrate the feature-pruning effect on a synthetic dataset, some datasets from the UCI repository, and real-world large-scale advertising response-prediction data-sets from MediaMath. In several of the MediaMath datasets there are 10s of millions of data points, and on the order of 100,000 sparse categorical features, and adversarial learning often results in model-size reduction by a factor of 20 or higher, and yet the model performance on natural test data (measured by AUC) is comparable to (and sometimes even better than) that of the naturally trained model. We also show that traditional $\ell_1$ regularization does not even come close to achieving this level of feature-concentration. We measure "feature concentration" using the Integrated Gradients-based feature-attribution method of Sundararajan et. al (2017), and derive a new closed-form expression for 1-layer networks, which substantially speeds up computation of aggregate feature attributions across a large dataset.