 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning and Explainability in Structured Datasets
Oct 26, 2018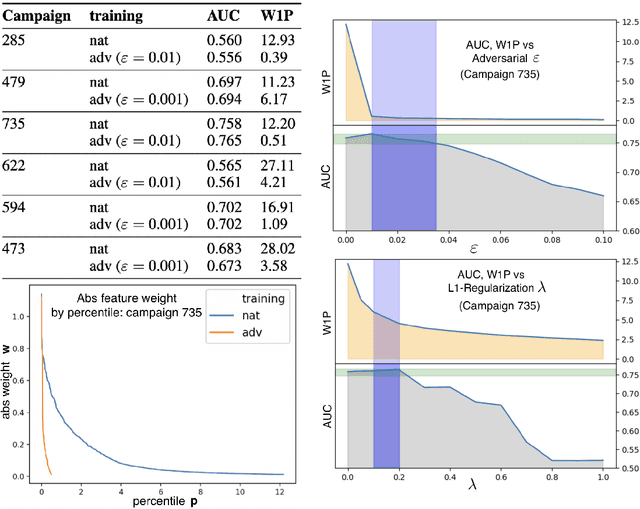
We theoretically and empirically explore the explainability benefits of adversarial learning in logistic regression models on structured datasets. In particular we focus on improved explainability due to significantly higher $\textit{feature-concentration}$ in adversarially-learned models: Compared to natural training, adversarial training tends to more efficiently shrink the weights of non-predictive and weakly-predictive features, while model performance on natural test data only degrades slightly (and even sometimes improves), compared to that of a naturally trained model. We provide theoretical insight into this phenomenon via an analysis of the expectation of the logistic model weight updates by an SGD-based adversarial learning algorithm, where examples are drawn from a random binary data-generation process. We empirically demonstrate the feature-pruning effect on a synthetic dataset, some datasets from the UCI repository, and real-world large-scale advertising response-prediction data-sets from MediaMath. In several of the MediaMath datasets there are 10s of millions of data points, and on the order of 100,000 sparse categorical features, and adversarial learning often results in model-size reduction by a factor of 20 or higher, and yet the model performance on natural test data (measured by AUC) is comparable to (and sometimes even better than) that of the naturally trained model. We also show that traditional $\ell_1$ regularization does not even come close to achieving this level of feature-concentration. We measure "feature concentration" using the Integrated Gradients-based feature-attribution method of Sundararajan et. al (2017), and derive a new closed-form expression for 1-layer networks, which substantially speeds up computation of aggregate feature attributions across a large dataset.