 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Bayesian Risk Decompositions and Multi-Source Domain Adaptation
Paper and Code
Apr 22, 2020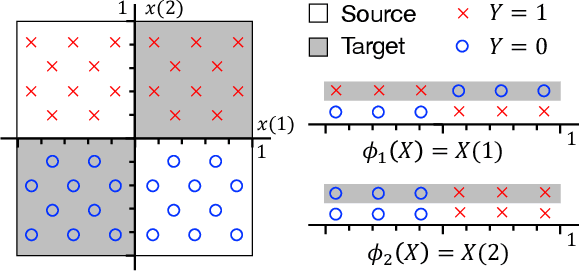
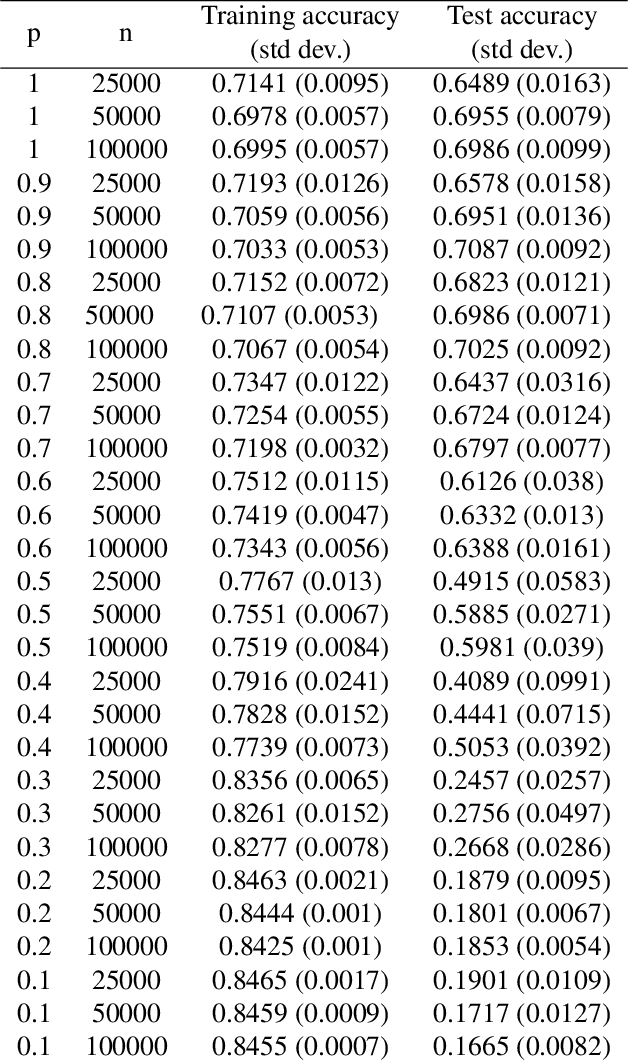
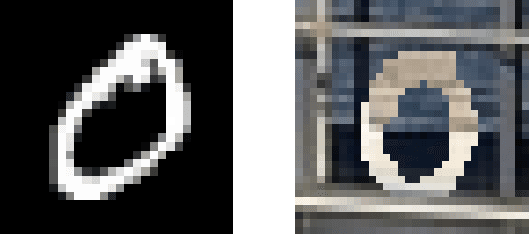

We consider representation learning (with hypothesis class $\mathcal{H} = \mathcal{F}\circ\mathcal{G}$) where training and test distributions can be different. Recent studies provide hints and failure examples for domain invariant representation learning, a common approach to this problem, but are inadequate for fully understanding the phenomena. In this paper, we provide new decompositions of risk which provide finer-grained explanations and clarify potential generalization issues. For Single-Source Domain Adaptation, we give an exact risk decomposition, an equality, where target risk is the sum of three factors: (1) source risk, (2) representation conditional label divergence, and (3) representation covariate shift. We derive a similar decomposition for the Multi-Source case. These decompositions reveal factors (2) and (3) as the precise reasons for failing to generalize. For example, we demonstrate that domain adversarial neural networks (DANN) attempt to regularize for (3) but miss (2), while a recent technique Invariant Risk Minimization (IRM) attempts to account for (2) but may suffer from not considering (3). We also verify these observations experimentally.