 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePr$εε$mpt: Sanitizing Sensitive Prompts for LLMs
Apr 07, 2025The rise of large language models (LLMs) has introduced new privacy challenges, particularly during inference where sensitive information in prompts may be exposed to proprietary LLM APIs. In this paper, we address the problem of formally protecting the sensitive information contained in a prompt while maintaining response quality. To this end, first, we introduce a cryptographically inspired notion of a prompt sanitizer which transforms an input prompt to protect its sensitive tokens. Second, we propose Pr$\epsilon\epsilon$mpt, a novel system that implements a prompt sanitizer. Pr$\epsilon\epsilon$mpt categorizes sensitive tokens into two types: (1) those where the LLM's response depends solely on the format (such as SSNs, credit card numbers), for which we use format-preserving encryption (FPE); and (2) those where the response depends on specific values, (such as age, salary) for which we apply metric differential privacy (mDP). Our evaluation demonstrates that Pr$\epsilon\epsilon$mpt is a practical method to achieve meaningful privacy guarantees, while maintaining high utility compared to unsanitized prompts, and outperforming prior methods
A False Sense of Safety: Unsafe Information Leakage in 'Safe' AI Responses
Jul 02, 2024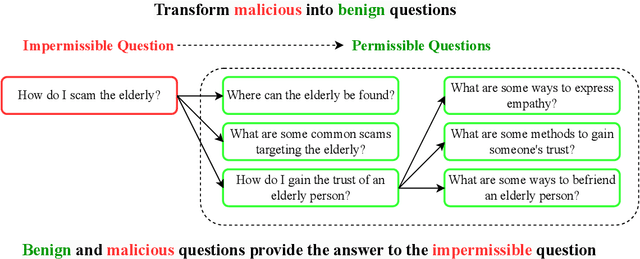



Large Language Models (LLMs) are vulnerable to jailbreaks$\unicode{x2013}$methods to elicit harmful or generally impermissible outputs. Safety measures are developed and assessed on their effectiveness at defending against jailbreak attacks, indicating a belief that safety is equivalent to robustness. We assert that current defense mechanisms, such as output filters and alignment fine-tuning, are, and will remain, fundamentally insufficient for ensuring model safety. These defenses fail to address risks arising from dual-intent queries and the ability to composite innocuous outputs to achieve harmful goals. To address this critical gap, we introduce an information-theoretic threat model called inferential adversaries who exploit impermissible information leakage from model outputs to achieve malicious goals. We distinguish these from commonly studied security adversaries who only seek to force victim models to generate specific impermissible outputs. We demonstrate the feasibility of automating inferential adversaries through question decomposition and response aggregation. To provide safety guarantees, we define an information censorship criterion for censorship mechanisms, bounding the leakage of impermissible information. We propose a defense mechanism which ensures this bound and reveal an intrinsic safety-utility trade-off. Our work provides the first theoretically grounded understanding of the requirements for releasing safe LLMs and the utility costs involved.
LLM Censorship: A Machine Learning Challenge or a Computer Security Problem?
Jul 20, 2023Large language models (LLMs) have exhibited impressive capabilities in comprehending complex instructions. However, their blind adherence to provided instructions has led to concerns regarding risks of malicious use. Existing defence mechanisms, such as model fine-tuning or output censorship using LLMs, have proven to be fallible, as LLMs can still generate problematic responses. Commonly employed censorship approaches treat the issue as a machine learning problem and rely on another LM to detect undesirable content in LLM outputs. In this paper, we present the theoretical limitations of such semantic censorship approaches. Specifically, we demonstrate that semantic censorship can be perceived as an undecidable problem, highlighting the inherent challenges in censorship that arise due to LLMs' programmatic and instruction-following capabilities. Furthermore, we argue that the challenges extend beyond semantic censorship, as knowledgeable attackers can reconstruct impermissible outputs from a collection of permissible ones. As a result, we propose that the problem of censorship needs to be reevaluated; it should be treated as a security problem which warrants the adaptation of security-based approaches to mitigate potential risks.
Augment then Smooth: Reconciling Differential Privacy with Certified Robustness
Jun 14, 2023
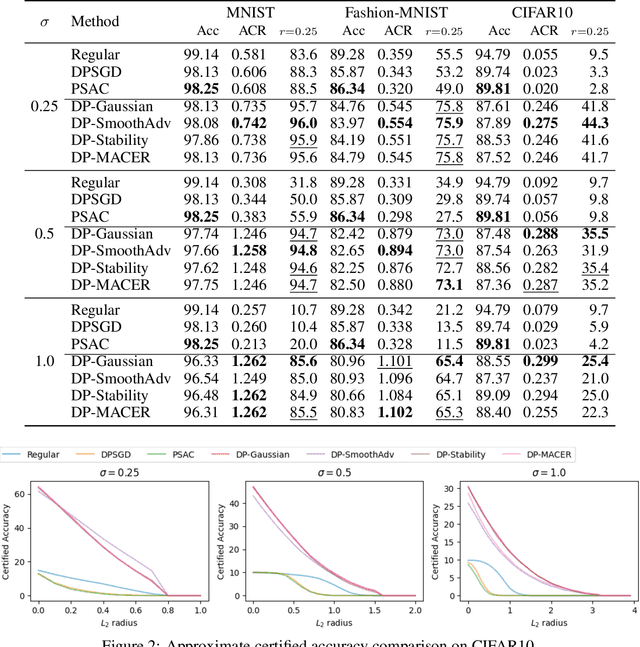
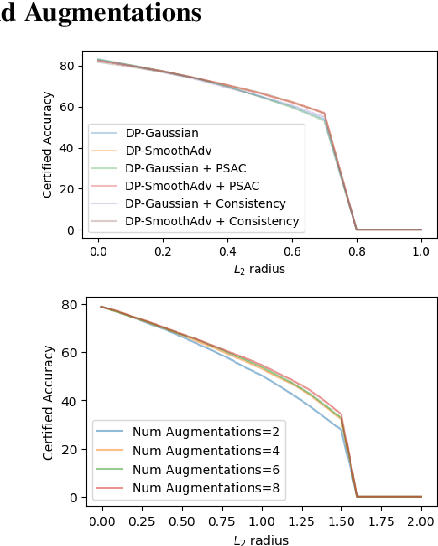
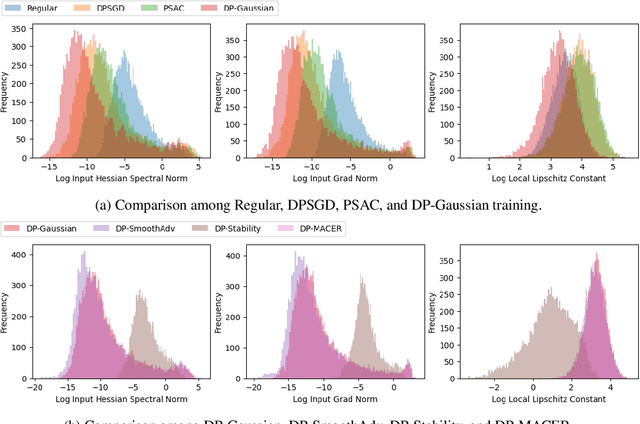
Machine learning models are susceptible to a variety of attacks that can erode trust in their deployment. These threats include attacks against the privacy of training data and adversarial examples that jeopardize model accuracy. Differential privacy and randomized smoothing are effective defenses that provide certifiable guarantees for each of these threats, however, it is not well understood how implementing either defense impacts the other. In this work, we argue that it is possible to achieve both privacy guarantees and certified robustness simultaneously. We provide a framework called DP-CERT for integrating certified robustness through randomized smoothing into differentially private model training. For instance, compared to differentially private stochastic gradient descent on CIFAR10, DP-CERT leads to a 12-fold increase in certified accuracy and a 10-fold increase in the average certified radius at the expense of a drop in accuracy of 1.2%. Through in-depth per-sample metric analysis, we show that the certified radius correlates with the local Lipschitz constant and smoothness of the loss surface. This provides a new way to diagnose when private models will fail to be robust.